ICCV 2021|“白嫖”性能的MixMo,一种新的数据增强or模型融合方法
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达
![]()
导读
本文作者提出了一种新的多输入多输出深度子网学习广义框架MixMo,MixMo可以作为一种集成方法或一种新的混合样本数据增强方法进行分析,同时仍然与两种研究方向的工作保持互补。
写在前面
最近的工作提出的不用额外计算的集成方法,大多是在一个网络中同时设置不同的subnet。训练时。每个subnet只学习分类多个输入数据中的其中一个。然而,如何更好地混合这些多个输入的问题迄今尚未被研究。
在本文,作者提出了一种新的多输入多输出深度子网学习广义框架MixMo。作者的Motivation是用一个更合适的混合机制来代替先前方法中求和导致的次优操作。受到混合样本数据增强的启发,作者发现特征的混合可以使subnet更强,使得数据更加多样,进而提高模型performance。
基于MixMo,作者提升了CIFAR-100和Tiny ImageNet数据集上的SOTA性能。
1. 论文和代码地址

论文地址:https://arxiv.org/abs/2103.06132
代码地址:https://github.com/alexrame/mixmo-pytorch
2. Motivation
卷积神经网络(cnn)在计算机视觉任务中表现出了出色的性能,尤其是分类任务。为了在真实场景中增加鲁棒性或赢得Kaggle竞赛,cnn通常会采用两种实用策略:数据增强 和模型集成 。
数据增强可以减少过拟合并提升模型的泛化性。传统的图像增强是保留标签的:例如翻转、裁剪等。然而,最近的混合样本数据增强(MSDA)改变了这种方式:多个输入和它们的标签按比例混合来创建人工样本,代表工作有MixUp,CutMix等等。
模型集成证明了聚合来自多个神经网络的不同预测能够显著提高了泛化能力,尤其是不确定性估计。从经验上讲,几个小网络的集成通常比一个大网络性能更好。然而,在训练和推理方面,集成在时间和显存消耗方面都是昂贵的:这往往限制了模型集成的适用性。
在本文,作者提出了多输入多输出框架MixMo。为了解决传统集成中出现的这些开销,作者将M个独立子网放入一个单一的base网络中。这也是合理的,因为在模型集成时,“最终采纳的网络”其实就和整体的网络表现差不多。
所以,现在最大的问题是如何在没有结构差异的情况下加强subnet之间的多样性。
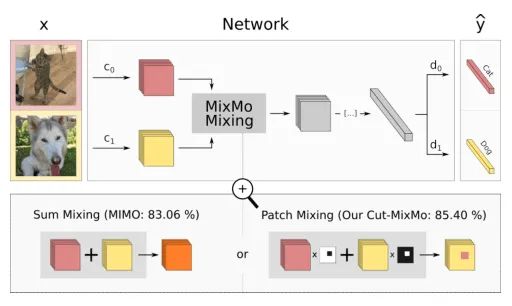
如上图,作者在训练过程中同时考虑了M个输入,M个输入被M个参数不共享的Encoder编码到共享空间中,然后将特征送到核心网络,核心网络最终分成M个分支;这个M个分支用来预测不同输入信息的label。在inference的时候,同一图像重复M次:通过平均M个预测获得“免费”的集成效果。
与现有的MSDA相比,MixMo最大的不同就是multi-input mixing block。如果合并是一个基本的求和,MixMo将变成到MIMO[1]。作者对比了大量的MSDA的工作,设计了更合适的混合块,因此作者采用binary masking的方法来确保子网络的多样性。(如上图所示,作者对不同样本采用了一个binary masking方法,这一点就类似CutMix,而不是像MIMO那样直接相加 )。
这种不对称的混合也会造成网络特征中的信息不平衡的新问题,因此作者通过一个新的加权函数来解决多个分类训练任务之间的不平衡问题。
3. 方法
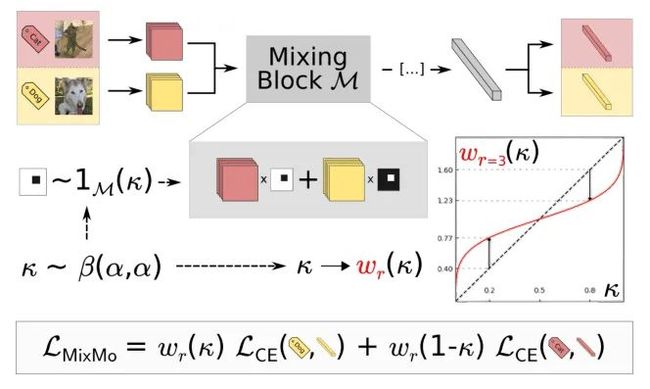
MixMo的整体结构如上图所示
3.1. General overview
如上图所示,多个训练数据 ,通过参数不共享的两个卷积神经网络分别编码到一个共享空间得到 和 。
为了能够显式地突出混合的信息,作者采用了一个广义多输入混合块 (generalized multi-input mixing block)。这种多重混合能够解决模型集成多样性和个体精度权衡的问题,从而达到更高的performance。共享的特征表示 , 被送入到下一个卷积层。
核心网络 需要同时处理两种输入的特征表示。然后多层的网络D,通过这个mix的特征,再一次把各自样本的类别识别出来。(个人理解这个网络是一个“分-总-分”的结构,首先,这个网络对不同输入的样本进行分别编码,这是第一个“分”的过程;然后这些被编码的特征通过Mixing Block融合,这是“总”的过程;最后不同的层再根据这个混合的特征,识别出各自样本的类别,这是最后一个“分”的过程 )
训练过程中的损失函数为各自样本的交叉熵损失函数之和(分别乘上各自的权重,权重的计算见下文):
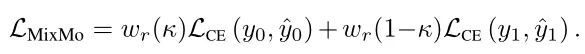
在inference的时候,同一个输入x被输入到不同的分支中,核心网络C的输入为 的和,这最大的保留了来自两种编码信息。然后,最终的预测结果为将不同分支的预测平均值 。这使得模型可以在一次前向传播的过程中享受模型融合的结果。
3.2. Mixing block
Mixing block 是MixMo的核心,它将两个输入组合成一个共享表示。受MSDA混合方法的启发,MixMo通用框架包含了更广泛的变化。
作者提出的第一个变体是 Linear-MixMo,借鉴了MixUp的思想,直接将两张图片通过一个透明度叠在一起:
接着,作者受到MixCut的启发,提出了 Cut-MixMo :
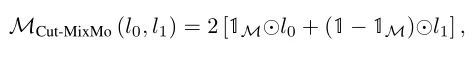
与Linear-MixMo不同,这里并不是将整张图片相加,而是像MixCut一样,每次都是加了一个patch。
Cut-MixMo比其他策略表现更好。具体来说,Cut-MixMo中的binary mixing取代了MIMO和 Linear-MixMo中的线性插值,使子网络更加精确和多样化。
为什么Cut-MixMo会比 Linear-MixMo要更好?
1)基于CutMix优于Mixup的相同原因,M中的binary mixing训练了更强的单个子网。此外通过binary mixing,模拟了常见的物体遮挡问题。
2)线性插值从根本上不适合诱导多样性,因为两个输入都保留了完整的信息。CutMix通过交替选择的图像patch,显式地增加了数据集的多样性。
3.3. Loss weighting
Mixing机制中的不对称可能导致一种输入盖过另一种输入。当 时,权重更大的输入可能更容易预测。因此,作者定义了一个权重函数 来平衡多个损失函数的重要性。这种加权调整了有效学习率、梯度在网络中的流动方式以及混合信息在特征中表示的方式。
加权函数具体表示如下:
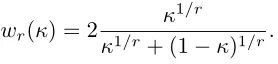
其中 是一个超参数, 的曲线如下图所示:

3.4. From manifold mixing to MixMo
相比于其他MSDA方法,MixMo使用两个独立的编码器(每个编码器输入一个数据),并且它输出是两个预测而不是一个。
而其他MSDA方法使用一个单一的分类器,该分类器针对一个唯一的软标签,通过线性插值反映不同的类。相反,MixMo选择充分利用混合样本的复合特性,训练分离的dense层,d0和d1,在测试时能够在没有额外计算的情况下,达到模型集成的效果。
4.实验
4.1. Main results on CIFAR-100 and CIFAR-10
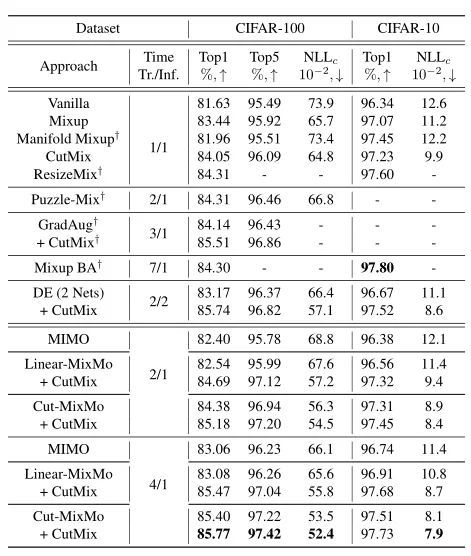
上表展示了MixMo在CIFAR10和CIFAR100上的结果,可以看出相比于原始的网络,MixMo对于性能的提升非常明显。

从上图可以看出,随着宽度w的增加,MixMo比DE(绿色曲线)的性能提升更加明显。
4.2. Training time
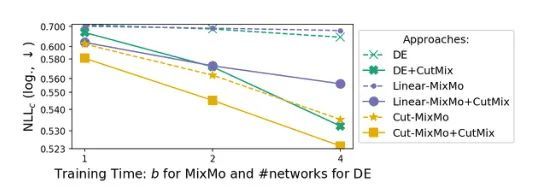
可以看出,在相同的训练时间内,Cut-MixMo的表现优于DE。
4.3. The mixing block
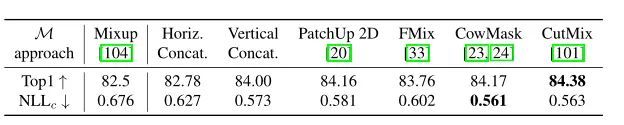
上表比较几个mix block的性能,可以看出无论形状如何,binary mixing的性能都优于线性混合。
4.4. Weighting function
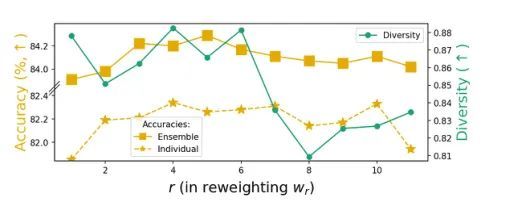
上图比较了加权函数不同r下的性能,r在[3,6]范围内达到了很好的trade-off。
4.5. Multiple encoders and classifiers

上表的实验结果表明,2个编码器和2个分类器对于实验结果是比较好的。
4.6. Pushing MixMo further: Tiny ImageNet
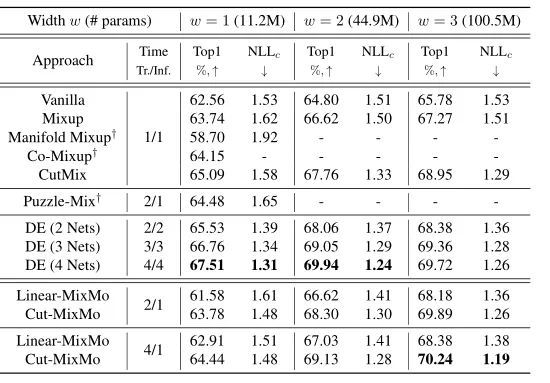
在更大的规模和更多样的64 × 64图像上,Cut-MixMo在Tiny ImageNet上达到了70.24%的新水平,如上表所示。
5. 总结
在本文中,作者提出了MixMo,一个多输入多输出策略的框架。MixMo可以作为一种集成方法或一种新的混合样本数据增强方法进行分析,同时仍然与两种研究方向的工作保持互补。此外,作者引入了一个新的权重函数,以平衡训练时的损失。最终,作者通过实验证明了MixMo的有效性。
参考文献
[1]. Marton Havasi, Rodolphe Jenatton, Stanislav Fort,Jeremiah Liu, Jasper Roland Snoek, Balaji Lakshminarayanan, Andrew Mingbo Dai, and Dustin Tran. Training independent subnetworks for robust prediction. In ICLR,2021.
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 