基于顺承关系的事理图谱的构建
目录
前言
一.数据获取
二.顺承事件的抽取
三.顺承关系图谱的构建
四.顺承关系图谱的展示
五.总结
前言
事理图谱中一般认为主要包含四种逻辑,本文主要讨论了基于顺承关系的事理图谱的构建过程。
一.数据获取
通过从旅游网站爬取博主的旅游经验及心得作为原始语料。该爬虫基于scrapy实现,爬取数据存储在mongo数据库中。
import scrapy
# from urllib import request
import request
import pymongo
from lxml import etree
from travelspider.items import TravelspiderItem
class TravelSpider(scrapy.Spider):
name = 'travel'
'''资讯采集主控函数'''
def start_requests(self):
for index in range(1, 505831):
url = 'http://you.ctrip.com/travels/china110000/t3-p%s.html'%index
response = request.urlopen(url)
page = response.read().decode('utf-8')
urls = self.get_urls(page)
if urls:
for url in urls:
try:
print(url)
param = {'url': url}
yield scrapy.Request(url=url, meta=param, callback=self.page_parser, dont_filter=True)
except:
pass
'''获取url列表'''
def get_urls(self, content):
selector = etree.HTML(content)
urls = ['http://you.ctrip.com' + i for i in selector.xpath('//a[starts-with(@class,"journal-item")]/@href')]
return set(urls)
'''网页解析'''
def page_parser(self, response):
selector = etree.HTML(response.text)
title = selector.xpath('//title/text()')[0]
paras = [p.xpath('string(.)').replace('\xa0', '') for p in selector.xpath('//div[@class="ctd_content"]/p') if
p.xpath('string(.)').replace('\xa0', '')]
if not paras:
paras = [p.xpath('string(.)').replace('\xa0', '') for p in
selector.xpath('//div[@class="ctd_content wtd_content"]/p') if
p.xpath('string(.)').replace('\xa0', '')]
if not paras:
paras = [p.xpath('string(.)').replace('\xa0', '') for p in selector.xpath('//div[@class="ctd_content"]')]
content = "\n".join([i.replace('\r', '').replace('\n', '') for i in paras])
item = TravelspiderItem()
item['url'] = response.meta['url']
item['title'] = title
item['content'] = content
yield item
return
import pymongo
class TravelspiderPipeline(object):
def __init__(self):
conn = pymongo.MongoClient()
self.col = conn['travel']['doc2']
'''处理采集资讯, 存储至Mongodb数据库'''
def process_item(self, item, spider):
try:
self.col.insert(dict(item))
except (pymongo.errors.WriteError, KeyError) as err:
raise DropItem("Duplicated Item: {}".format(item['name']))
return item
爬取原始数据一览:

二.顺承事件的抽取
首先从原始语料中通过人为构建的顺承关系关键词模板提取出具有顺承关系的句子,对这些句子进行处理后,进行顺承关系库的构建。
具体的构建步骤如下:
1.输入原始语料
2.对原始语料进行长句的切分(认为每一个短句包含一个事件)
3.基于人为构建的顺承关系关键词模板,提取具有顺承关系的句子
4.对得到的句子再进行短句切分处理(处理括号,顿号等符号)
5.对第4步得到的句子进行谓语的提取(认为句子中的谓语是体现事件的核心词)
6.对提取出的谓语成分进行组成,构成一个由谓语成分组成的长句集合
7.以滑窗方式构建顺承关系事件对
8.将第7步中的事件对进行整合,获得具有顺承关系的事件库
9.对事件库进行筛选,去除频次过低的事件,构造最终的顺承关系库
#依存句法分析
import os
from pyltp import Segmentor, Postagger, Parser, NamedEntityRecognizer
class LtpParser():
def __init__(self):
LTP_DIR = "./ltp_data"
self.segmentor = Segmentor()
self.segmentor.load(os.path.join(LTP_DIR, "cws.model"))
self.postagger = Postagger()
self.postagger.load(os.path.join(LTP_DIR, "pos.model"))
self.parser = Parser()
self.parser.load(os.path.join(LTP_DIR, "parser.model"))
self.recognizer = NamedEntityRecognizer()
self.recognizer.load(os.path.join(LTP_DIR, "ner.model"))
'''ltp基本操作'''
def basic_parser(self, words):
postags = list(self.postagger.postag(words))
netags = self.recognizer.recognize(words, postags)
return postags, netags
'''ltp获取词性'''
def get_postag(self, words):
return list(self.postagger.postag(words))
'''基于实体识别结果,整理输出实体列表'''
def format_entity(self, words, netags, postags):
name_entity_dist = {}
name_entity_list = []
place_entity_list = []
organization_entity_list = []
ntag_E_Nh = ""
ntag_E_Ni = ""
ntag_E_Ns = ""
index = 0
for item in zip(words, netags):
word = item[0]
ntag = item[1]
if ntag[0] != "O":
if ntag[0] == "S":
if ntag[-2:] == "Nh":
name_entity_list.append(word+'_%s ' % index)
elif ntag[-2:] == "Ni":
organization_entity_list.append(word+'_%s ' % index)
else:
place_entity_list.append(word + '_%s ' % index)
elif ntag[0] == "B":
if ntag[-2:] == "Nh":
ntag_E_Nh = ntag_E_Nh + word + '_%s ' % index
elif ntag[-2:] == "Ni":
ntag_E_Ni = ntag_E_Ni + word + '_%s ' % index
else:
ntag_E_Ns = ntag_E_Ns + word + '_%s ' % index
elif ntag[0] == "I":
if ntag[-2:] == "Nh":
ntag_E_Nh = ntag_E_Nh + word + '_%s ' % index
elif ntag[-2:] == "Ni":
ntag_E_Ni = ntag_E_Ni + word + '_%s ' % index
else:
ntag_E_Ns = ntag_E_Ns + word + '_%s ' % index
else:
if ntag[-2:] == "Nh":
ntag_E_Nh = ntag_E_Nh + word + '_%s ' % index
name_entity_list.append(ntag_E_Nh)
ntag_E_Nh = ""
elif ntag[-2:] == "Ni":
ntag_E_Ni = ntag_E_Ni + word + '_%s ' % index
organization_entity_list.append(ntag_E_Ni)
ntag_E_Ni = ""
else:
ntag_E_Ns = ntag_E_Ns + word + '_%s ' % index
place_entity_list.append(ntag_E_Ns)
ntag_E_Ns = ""
index += 1
name_entity_dist['nhs'] = self.modify_entity(name_entity_list, words, postags, 'nh')
name_entity_dist['nis'] = self.modify_entity(organization_entity_list, words, postags, 'ni')
name_entity_dist['nss'] = self.modify_entity(place_entity_list,words, postags, 'ns')
return name_entity_dist
'''entity修正,为rebuild_wordspostags做准备'''
def modify_entity(self, entity_list, words, postags, tag):
entity_modify = []
if entity_list:
for entity in entity_list:
entity_dict = {}
subs = entity.split(' ')[:-1]
start_index = subs[0].split('_')[1]
end_index = subs[-1].split('_')[1]
entity_dict['stat_index'] = start_index
entity_dict['end_index'] = end_index
if start_index == entity_dict['end_index']:
consist = [words[int(start_index)] + '/' + postags[int(start_index)]]
else:
consist = [words[index] + '/' + postags[index] for index in range(int(start_index), int(end_index)+1)]
entity_dict['consist'] = consist
entity_dict['name'] = ''.join(tmp.split('_')[0] for tmp in subs) + '/' + tag
entity_modify.append(entity_dict)
return entity_modify
'''基于命名实体识别,修正words,postags'''
def rebuild_wordspostags(self, name_entity_dist, words, postags):
pre = ' '.join([item[0] + '/' + item[1] for item in zip(words, postags)])
post = pre
for et, infos in name_entity_dist.items():
if infos:
for info in infos:
post = post.replace(' '.join(info['consist']), info['name'])
post = [word for word in post.split(' ') if len(word.split('/')) == 2 and word.split('/')[0]]
words = [tmp.split('/')[0] for tmp in post]
postags = [tmp.split('/')[1] for tmp in post]
return words, postags
'''依存关系格式化'''
def syntax_parser(self, words, postags):
arcs = self.parser.parse(words, postags)
words = ['Root'] + words
postags = ['w'] + postags
tuples = list()
for index in range(len(words)-1):
arc_index = arcs[index].head
arc_relation = arcs[index].relation
tuples.append([index+1, words[index+1], postags[index+1], words[arc_index], postags[arc_index], arc_index, arc_relation])
return tuples
'''为句子中的每个词语维护一个保存句法依存儿子节点的字典'''
def build_parse_child_dict(self, words, postags, tuples):
child_dict_list = list()
for index, word in enumerate(words):
child_dict = dict()
for arc in tuples:
if arc[3] == word:
if arc[-1] in child_dict:
child_dict[arc[-1]].append(arc)
else:
child_dict[arc[-1]] = []
child_dict[arc[-1]].append(arc)
child_dict_list.append([word, postags[index], index, child_dict])
return child_dict_list
'''parser主函数'''
def parser_main(self, words, postags):
tuples = self.syntax_parser(words, postags)
child_dict_list = self.build_parse_child_dict(words, postags, tuples)
return tuples, child_dict_list
'''基础语言分析'''
def basic_process(self, sentence):
words = list(self.segmentor.segment(sentence))
postags, netags = self.basic_parser(words)
name_entity_dist = self.format_entity(words, netags, postags)
words, postags = self.rebuild_wordspostags(name_entity_dist, words, postags)
return words, postags
import pymongo
import re
import jieba
from sentence_parser import *
class EventGraph:
def __init__(self):
#连接mongo客户端
conn = pymongo.MongoClient()
#顺承关系模板
self.pattern = re.compile(r'(.*)(其次|然后|接着|随后|接下来)(.*)')
#选择mongo中的数据库
self.col = conn['travel']['doc']
self.col_insert = conn['travel']['events']
#依存句法分析
self.parse_handler = LtpParser()
'''长句切分'''
def seg_long_sents(self, content):
return [sentence for sentence in re.split(r'[??!!。;;::\n\r….·]', content.replace(' ','').replace('\u3000','')) if len(sentence) > 5]
'''短句切分'''
def process_subsent(self, content):
return [s for s in re.split(r'[,、,和与及且跟()~▲.]', content) if len(s)>1]
'''处理数据库中的文本'''
def process_doc(self):
count = 0
#find返回数据库中所有数据
for item in self.col.find():
content = item['content']
events_all = self.collect_event(content)
if events_all:
data = {}
data['events'] = events_all
self.col_insert.insert(data)
else:
continue
'''统计收集EVENT'''
def collect_event(self, content):
events_all = []
sents= self.seg_long_sents(content)
for sent in sents:
events = self.event_extract(sent)
if events:
events_all.append(events)
return events_all
'''顺承事件抽取'''
def event_extract(self, sent):
result = self.pattern.findall(sent)
if result:
event_seqs = []
for tmp in result:
pre = tmp[0]
post = tmp[2]
pre_sents = self.process_subsent(pre)
post_sents = self.process_subsent(post)
if pre_sents and post_sents:
event_seqs += pre_sents
event_seqs += post_sents
else:
continue
'''对事件进行结构化'''
if event_seqs:
events = self.extract_phrase(event_seqs)
return events
else:
pass
return []
'''将一个长句中的句子进行分解,提取出其中的vob短语'''
def extract_phrase(self, event_seqs):
events = []
for event in event_seqs:
vobs = self.vob_exract(event)
if vobs:
events += vobs
return events
'''提取VOB关系'''
def vob_exract(self, content):
vobs = []
words = list(jieba.cut(content))
if len(words) >= 300:
return []
postags = self.parse_handler.get_postag(words)
tuples, child_dict_list = self.parse_handler.parser_main(words, postags)
for tuple in tuples:
rel = tuple[-1]
pos_verb= tuple[4][0]
pos_object = tuple[2][0]
if rel == 'VOB' and (pos_verb, pos_object) in [('v', 'n'), ('v', 'i')]:
phrase = ''.join([tuple[3], '#', tuple[1]])
vobs.append(phrase)
return vobs
handler = EventGraph()
handler.process_doc()三.顺承关系图谱的构建
利用JS中的VIS插件实现顺承关系图谱在网页上的构建和呈现。
'''构造显示图谱'''
class CreatePage:
def __init__(self):
self.base = '''
'''
'''生成数据'''
def collect_data(self, nodes, edges):
node_dict = {node:index for index, node in enumerate(nodes)}
data_nodes= []
data_edges = []
for node, id in node_dict.items():
data = {}
data["group"] = 'Event'
data["id"] = id
data["label"] = node
data_nodes.append(data)
for edge in edges:
data = {}
data['from'] = node_dict.get(edge[0])
data['label'] = '顺承'
data['to'] = node_dict.get(edge[1])
data_edges.append(data)
return data_nodes, data_edges
'''生成html文件'''
def create_html(self, data_nodes, data_edges):
f = open('travel_event_graph.html', 'w+' ,encoding='utf-8')
html = self.base.replace('data_nodes', str(data_nodes)).replace('data_edges', str(data_edges))
f.write(html)
f.close()
'''顺承关系图谱'''
class EventGraph:
def __init__(self):
self.event_path = './seq_events.txt'
'''统计事件频次'''
def collect_events(self):
event_dict = {}
node_dict = {}
for line in open('seq_events.txt' ,encoding='utf-8'):
event = line.strip()
if not event:
continue
nodes = event.split('->')
for node in nodes:
if node not in node_dict:
node_dict[node] = 1
else:
node_dict[node] += 1
if event not in event_dict:
event_dict[event] = 1
else:
event_dict[event] += 1
return event_dict, node_dict
'''过滤低频事件,构建事件图谱'''
def filter_events(self, event_dict, node_dict):
edges = []
nodes = []
for event in sorted(event_dict.items(), key=lambda asd: asd[1], reverse=True)[:500]:
e1 = event[0].split('->')[0]
e2 = event[0].split('->')[1]
if e1 in node_dict and e2 in node_dict:
nodes.append(e1)
nodes.append(e2)
edges.append([e1, e2])
else:
continue
return edges, nodes
'''调用VIS插件,进行事件图谱展示'''
def show_graph(self, edges, nodes):
handler = CreatePage()
data_nodes, data_edges = handler.collect_data(nodes, edges)
handler.create_html(data_nodes, data_edges)
handler = EventGraph()
event_dict, node_dict = handler.collect_events()
edges, nodes = handler.filter_events(event_dict, node_dict)
handler.show_graph(edges, nodes)
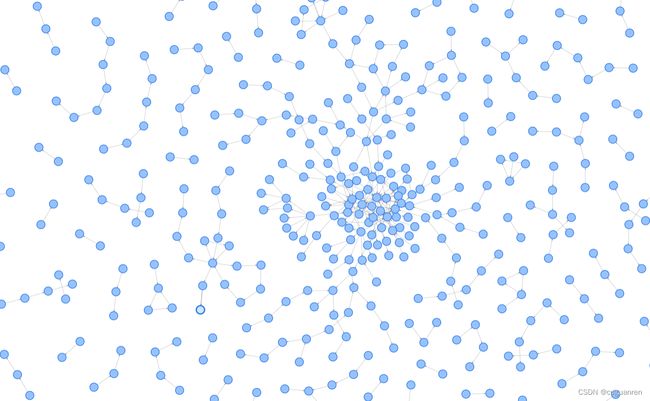
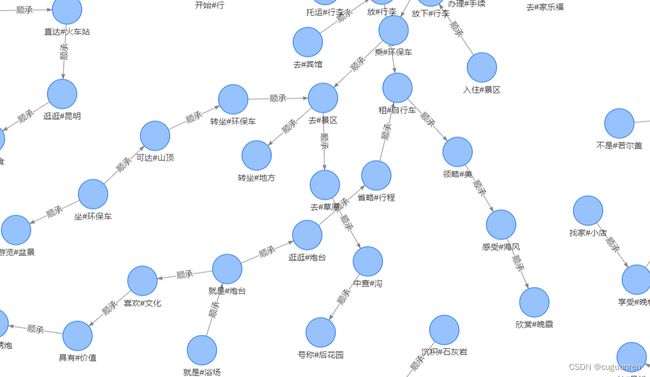
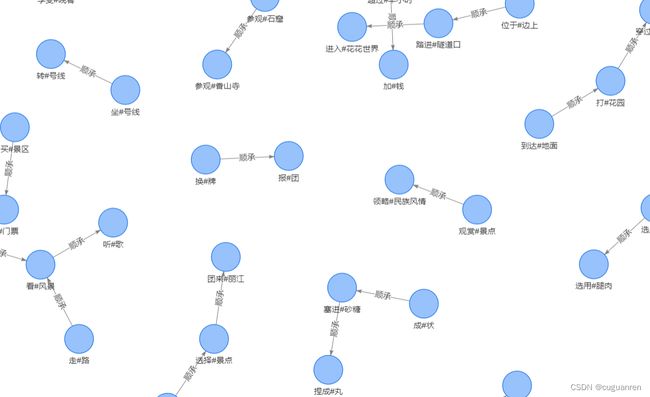
四.顺承关系图谱的展示
展示如下:
五.总结
1.本文中提到对于从原始语料中提取具有顺承关系的句子是采用的人为构建的关键词模板,但考虑到关键词由人为确定,且具有顺承关系的句子不一定含有这些标志词,因此基于这种方法的提取过程并不能称得上“精准”,后续可以通过人为构造神经网络训练好模型,对原始语料进行文本分类完成提取。
2.本文认为句子的谓语成分主要由动宾,也就是依存关系中的VOB关系体现,因此在谓语成分的识别中,只对VOB关系进行了识别,显然这种方法既会遗漏一定数量的谓语成分,也会引入一些非谓语成分,有待后续对该过程的完善。