2020年,那些「引爆」了ML社区的热门论文、库和基准
2020 年出现了哪些引爆机器学习社区的论文和库呢?哪些模型和方法登顶各领域基准排行榜呢?这篇文章给你答案。
机器之心报道,作者:杜伟
不平凡的 2020 年终于过去了!这一年,由于新冠肺炎疫情的影响,CVPR、ICLR、NeurIPS 等各大学术会议都改为线上举行。但是,机器学习社区的研究者和开发者没有停下脚步,依然贡献了很多重大的研究发现。
不久前,资源网站 Papers with Code 发文总结了 2020 年 Top 10 热门的论文、库和基准,涵盖自然语言处理、图像分类、目标检测、语义分割、实例分割、姿态估计、行人重识别等诸多领域。
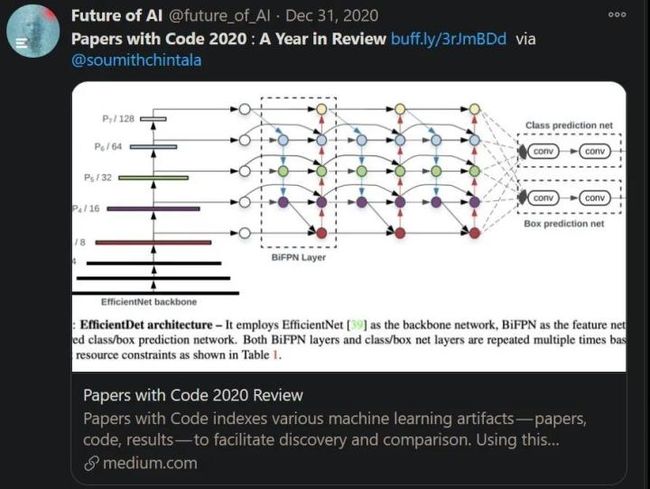
Top 10 热门论文
论文 1:EfficientDet: Scalable and Efficient Object Detection

论文链接:https://arxiv.org/pdf/1911.09070v7.pdf
简介:这项论文最初在 2019 年 11 月份发布首版,机器之心进行了报道,本文是最新版。谷歌大脑的研究者探讨了计算机视觉领域的模型效率问题,分别提出了加权双向特征金字塔网络和复合缩放方法,进而开发了一种新的 EfficientDet 目标检测器,实现了新的 SOTA 水平。本文被 CVPR 2020 会议接收。
论文 2:Fixing the train-test resolution discrepancy

论文链接:https://arxiv.org/pdf/2003.08237v5.pdf
简介:FixRes(Fixing Resolution)是一种能够提升任何模型性能的方法,可以在数个 epoch 期间用作卷积训练后的微调步骤,因而具有非常高的灵活性。FixRes 也可以轻松地集成到现有任何训练 pipeline。FAIR 的研究者将 FixRes 方法与 SOTA 模型 EfficientNet 结合,提出了新的架构 FixEfficientNet,并在 ImageNet 数据集上取得了 88.5% 的 top-1 准确率,实现了当时的 SOTA 性能。
论文 3:ResNeSt: Split-Attention Networks

论文链接:https://arxiv.org/pdf/2004.08955v2.pdf
简介:Facebook、加州大学戴维斯分校、字节跳动等机构的研究者提出了一种模块化 Split-Attention 块,可以将注意力分散到若干特征图组中。按照 ResNet 的风格堆叠这些 Split-Attention 块,他们得到一个 ResNet 的新变体,称为ResNeSt。其中,ResNeSt-50 在 ImageNet 数据集上取得了 81.13% 的 top-1 准确率,比此前最好的 ResNet 变体高 1% 以上。这一提升对于目标检测、实例分割、语义分割等下游任务来说很有意义。
论文 4:Big Transfer (BiT): General Visual Representation Learning

论文链接:https://arxiv.org/pdf/1912.11370v3.pdf
简介:谷歌大脑的研究者提出了迁移学习模型 Big Transfer (BiT)。BiT 是一组预训练的图像模型:即便每个类只有少量样本,经迁移后也能够在新数据集上实现出色的性能。BiT 分别在 ILSVRC-2012、CIFAR-10 和包含 19 项评估任务的 Visual Task Adaptation Benchmark (VTAB) 数据集上实现了 87.5%、99.4% 和 76.3% 的 top-1 准确率;在小型数据集上,BiT 也分别在每类 10 个样本的 ILSVRC-2012 和 CIFAR-10 数据集上实现了 76.8% 和 97.0% 的 top-1 准确率。本文被 ECCV 2020 会议接收。
论文 5:Object-Contextual Representations for Semantic Segmentation

论文链接:https://arxiv.org/pdf/1909.11065v5.pdf
简介:中科院计算所、微软亚研等机构的研究者旨在解决语义分割问题,并聚焦上下文聚合策略。他们提出了一种简单却有效的方法目标上下文表征(object-contextual representation, OCR),它利用相应目标类的表征来描述像素特征。实验结果表明,本文提出的 OCR 方法在 Cityscapes、ADE20K 以及 PASCAL-Context 等多种挑战性语义分割基准上实现了相当不错的性能。本文被 ECCV 2020 会议接收。
论文 6:Self-training with Noisy Student improves ImageNet classification

论文链接:https://arxiv.org/pdf/1911.04252v4.pdf
简介:机器之心在 2019 年 11 月对该论文 v1 版进行了报道,本文是 v2 版本。谷歌大脑和卡内基梅隆大学的研究者提出了一种半监督学习方法 Noisy Student Training,该方法在标注数据充足时也能运行良好。实验结果表明,Noisy Student Training 在 ImageNet 数据集上实现了 88.4% 的准确率,比需要 35 亿(3.5B)弱标注 Ins 图像的 SOTA 模型提升了 2.0%。在鲁棒性测试集中,Noisy Student Training 将 ImageNet-A 的 top-1 准确率从 61.0% 提升至了 83.7%,将 ImageNet-C 的 mean corruption error (MCR) 从 45.7 降至了 28.3,并将 ImageNet-P 的 mean flip rate(MFR) 从 27.8 降至了 12.2。本文被 CVPR 2020 会议接收。
论文 7:YOLOv4: Optimal Speed and Accuracy of Object Detection

论文链接:https://arxiv.org/pdf/2004.10934v1.pdf
简介:2020 年 4 月份,YOLO 的官方 Github 开源了YOLOv4,迅速引起了 CV 社区的关注。研究者对比了 YOLOv4 和当前最优目标检测器,发现 YOLOv4 在取得与 EfficientDet 同等性能的情况下,速度是 EfficientDet 的二倍!此外,与 YOLOv3 相比,新版本的 AP 和 FPS 分别提高了 10% 和 12%。
论文 8:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

论文链接:https://arxiv.org/pdf/2010.11929.pdf
简介:谷歌大脑的研究者受到 NLP 领域中 Transformer 缩放成功的启发,尝试将标准 Transformer 直接应用于图像,并尽可能减少修改。他们提出了一个新的Vision Transformer(ViT)模型,并在多个图像识别基准上实现了接近甚至优于当前 SOTA 方法的性能。
论文 9:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer

论文链接:https://arxiv.org/pdf/1910.10683v3.pdf
简介:谷歌研究者通过引入一个将所有基于文本的语言问题转化为文本到文本格式的统一框架,对自然语言处理(NLP)的迁移学习方法进行了探索。他们提出了新的Text-to-Text Transfer Transformer (T5) 模型,参数量最高达到了 110 亿。T5 模型在涵盖摘要生成、问答以及文本分类等 17 项 NLP 任务上实现了新 SOTA。此外,研究者开源了新的 Colossal Clean Crawled Corpus (C4) 语料库,内含从网上爬取的数百个千兆字节干净英文文本。
论文 10:Hierarchical Multi-Scale Attention for Semantic Segmentation

论文链接:https://arxiv.org/pdf/2005.10821v1.pdf
简介:多尺度推理通常用于提升语义分割的结果。英伟达的研究者提出了一种分层注意力机制,通过这种机制,网络可以学习预测相邻尺度之间的相对权重。研究者在 Cityscapes 和 Mapillary Vistas 两个数据集上测试了分层注意力机制的效果,其中在拥有大量弱标注图像的 Cityscapes 数据集上,他们还引入了一种提升泛化性能的自动标注方法。实验结果表明,分层多尺度注意力机制均取得了 SOTA 结果,在 Mapillary 上实现了 61.1% 的 mIOU,在 Cityscapes 实现了 85.1% 的 mIOU。
Top 10 热门库
Transformers

项目地址:https://github.com/huggingface/transformers
简介:transformers 库由 Hugging Face 团队创建,旨在将这些 NLP 进展开放给更广泛的机器学习社区。该库包含多个精心设计的 SOTA Transformer 架构,并使用统一的 API。transformers 库汇集了社区构建的多个预训练模型,并向社区开放。目前,该库的 star 量高达 39.3k,transformers 论文获得了EMNLP 2020 最佳 demo 论文奖。
PyTorch Image Models

项目地址:https://github.com/rwightman/pytorch-image-models
简介:pytorch-image-models 库由热衷于构建 ML 和 AI 系统的加拿大人 Ross Wightman 创建,包含了图像模型、层、实用工具、优化器、调度器、数据加载器 / 扩增、推理训练 / 验证脚本等资源。该库旨在将多种多样的 SOTA 模型整合起来,以复现 ImageNet 数据集上的训练结果。目前,该库的 star 量为 6.6k。
detectron2

项目地址:https://github.com/facebookresearch/detectron2
简介:Detectron2 是 Facebook AI Research 的新一代软件系统,旨在实现 SOTA 目标检测算法。该库在以前版本Detectron上进行重新编写,并包含了 maskrcnn-benchmark 库(已被弃用)的所有模型实现。目前,该库的 star 量高达 14.5k。
insightface

项目地址:https://github.com/deepinsight/insightface
简介:insightface 由 Deep Insight 团队创建,是一个开源的 2D 和 3D 深度人脸分析工具箱,主要基于 MXNet 框架构建。该库的主分支(master branch)适用于 MXNet 1.2-1.6 版本以及 Python 3.x 版本。目前,该库的 star 量为 8.4k。
imgclsmob

项目地址:https://github.com/osmr/imgclsmob
简介:imgclsmob 库由高级软件工程师 Oleg Sémery 创建,主要研究计算机视觉任务的卷积网络。该库包含用于训练、评估和转换的各种分类、分割、检测和姿态估计模型和脚本的实现或复现。目前,该库的 star 量为 2k。
DarkNet

项目地址:https://github.com/pjreddie/darknet
简介:darknet 库由专注于计算机视觉研究的 Joseph Redmon 创建,是一个基于 C 语言和 CUDA 编写的开源神经网络框架。它的安装快速且方便,并且支持 CPU 和 GPU 计算。目前,该库的 star 量高达 19.8k。
PyTorchGAN

项目地址:https://github.com/eriklindernoren/PyTorch-GAN
简介:PyTorchGAN 库由 Apple 公司的 ML 工程师 Erik Linder-Norén 创建,收集了论文中各种生成对抗网络(GAN)的 PyTorch 实现。创建者认为模型架构并不总是能够反映论文中提出的观点,所以他聚焦于获取论文的核心理念而不只是确保每个层配置都正确。不过遗憾的是,由于创建者没有时间维护,该库已经过时了。目前,该库的 star 量为 8.4k。
MMDetection

项目地址:https://github.com/open-mmlab/mmdetection
简介:MMDetection是基于 PyTorch 的开源目标检测工具箱,由香港中文大学多媒体实验室(Multimedia Laboratory)创建,是 OpenMMLab 项目的组成部分。该库始于 MMDet 团队(赢得 2018 COCO 挑战赛检测赛道)的代码库,之后逐渐发展成为一个涵盖很多流行检测方法和模块的统一平台。该库不仅包含训练和推理代码,而且提供有 200 多个网络模型的权重。目前,该库的 star 量高达 13.3k。
FairSeq

项目地址:https://github.com/pytorch/fairseq
简介:Fairseq 由 PyTorch 团队创建,是一个序列建模工具包,使得研究者和开发者能够训练用于翻译、摘要生成、语言建模和其他文本生成任务的自定义模型。目前,该库的 star 量高达 11k。
Gluon CV

项目地址:https://github.com/dmlc/gluon-cv
简介:GluonCV 由分布式机器学习社区(DMLC)创建,提供了计算机视觉领域 SOTA 深度学习模型的实现,旨在使工程师、研究者和学生能够基于这些模型快速 prototype 产品和研究思路。该库具有以下几种主要特性:提供训练脚本以复现论文 SOTA 结果;支持 PyTorch 和 MXNet;提供大量预训练模型以及显著降低实现复杂度的精心设计的 API;社区支持。目前,该库的 star 量为 4.5k。
Top 10 热门基准
ImageNet 数据集上的图像分类基准
top-1 和 top-5 准确率排名第一的均为谷歌大脑团队提出的元伪标签(Meta Pseudo Labels)半监督学习方法,其中 top-1 准确率为 90.2%,top-5 准确率为 98.8%。

- 基准地址:https://paperswithcode.com/sota/image-classification-on-imagenet
- Meta Pseudo Labels 论文地址:https://arxiv.org/pdf/2003.10580v3.pdf
COCO test-dev 数据集上的目标检测基准
box AP 数值最高的是谷歌大脑团队提出 Cascade Eff-B7 NAS-FPN,在 COCO 实例分割任务上实现了 49.1 的 mask AP 和 57.3 的 box AP,分别比之前 SOTA 高出了 0.6 和 1.5。

- 基准地址:https://paperswithcode.com/sota/object-detection-on-coco
- Cascade Eff-B7 NAS-FPN 论文地址:https://arxiv.org/pdf/2012.07177v1.pdf
Cityscapes test 数据集上的语义分割基准
Mean IoU 最高的是英伟达提出的 HRNet-OCR(分层多尺度注意力机制),在 Cityscapes test 数据集上取得了 85.1% 的 mIoU。
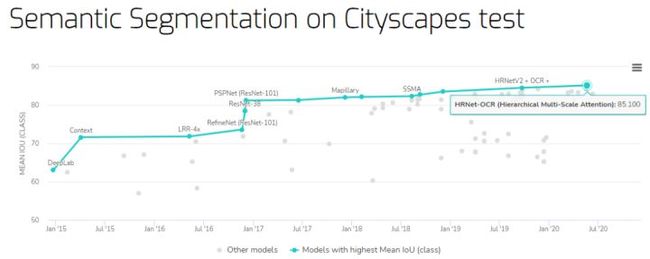
基准地址:https://paperswithcode.com/sota/semantic-segmentation-on-cityscapes
- HRNet-OCR 论文地址:https://arxiv.org/pdf/2005.10821v1.pdf
CIFAR-10 数据集上的图像分类基准
Percentage Correct 指标排名第一的是谷歌研究院提出的 EffNet-L2 (SAM),取得了 99.7% 的 SOTA 得分。
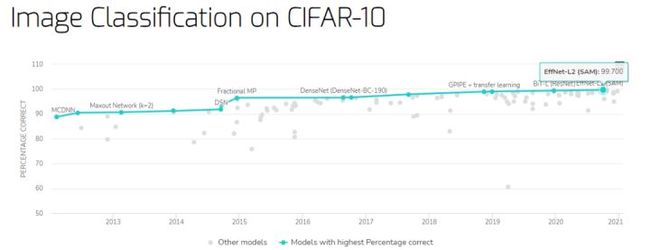
- 基准地址:https://paperswithcode.com/sota/image-classification-on-cifar-10
- EffNet-L2 (SAM) 论文地址:https://arxiv.org/pdf/2010.01412v2.pdf
CIFAR-100 数据集上的图像分类基准
Percentage Correct 指标排名第一的依然是谷歌研究院提出的 EffNet-L2 (SAM),取得了 96.08% 的 SOTA 得分。
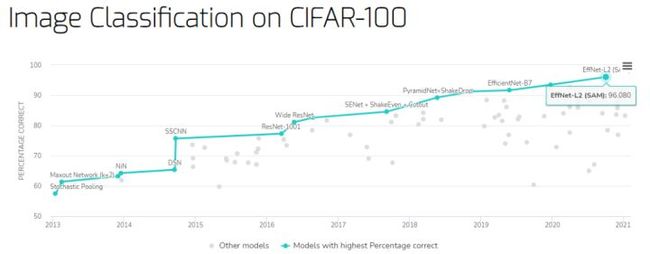
基准地址:https://paperswithcode.com/sota/image-classification-on-cifar-100
PASCAL VOC 2012 test 数据集上的语义分割基准
Mean IoU 最高的是谷歌大脑团队提出的 EfficientNet-L2+NAS-FPN,在 PASCAL VOC 2012 test 数据集上取得了 90.5% 的 mIoU。
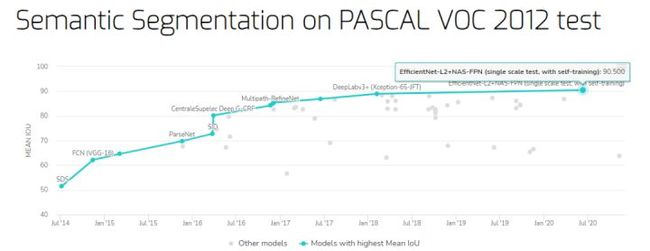
- 基准地址:https://paperswithcode.com/sota/semantic-segmentation-on-pascal-voc-2012
- EfficientNet-L2+NAS-FPN 论文地址:https://arxiv.org/pdf/2006.06882v2.pdf
MPII Human Pose 数据集上的姿态估计基准
PCKH-0.5 最高的是三星 AI Center 提出的 Soft-gated Skip Connections,在 MPII Human Pose 数据集上取得了 94.1% 的 PCKH-0.5。
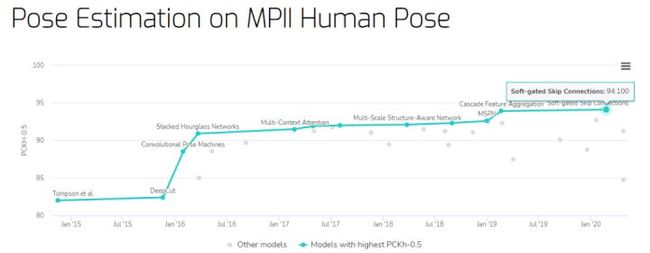
- 基准地址:https://paperswithcode.com/sota/pose-estimation-on-mpii-human-pose
- Soft-gated Skip Connections 论文地址:https://arxiv.org/pdf/2002.11098v1.pdf
Market-1501 数据集上的行人重识别基准
mAP(Mean Average Precision)最高的是中山大学于 2018 年提出的 st-ReID,在 Market-1501 数据集上取得了 95.5% 的 mAP 和 98.0% 的 rank-1 准确率,均显著优于以往的 SOTA 方法。
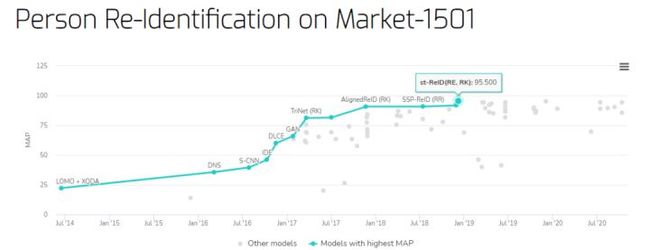
- 基准地址:https://paperswithcode.com/sota/person-re-identification-on-market-1501
- st-ReID 论文地址:https://arxiv.org/pdf/1812.03282v1.pdf
MNIST 数据集上的图像分类基准
准确率最高的是布鲁内尔大学联合布拉德利大学提出的 Branching/Merging CNN + Homogeneous Filter Capsules,在 MNIST 数据集上取得了 99.84 的 SOTA 准确率,同时 Percentage Error 也最低,为 0.16%。

- 基准地址:https://paperswithcode.com/sota/image-classification-on-mnist
- Branching/Merging CNN + Homogeneous Filter Capsules 论文地址:https://arxiv.org/pdf/2001.09136v4.pdf
Human3.6M 数据集上的 3D 人体姿态估计基准
三星 AI Center 提出的 Learnable Triangulation of Human Pose 在该数据集上取得了最低的 Average MPJPE ——17.7 mm。
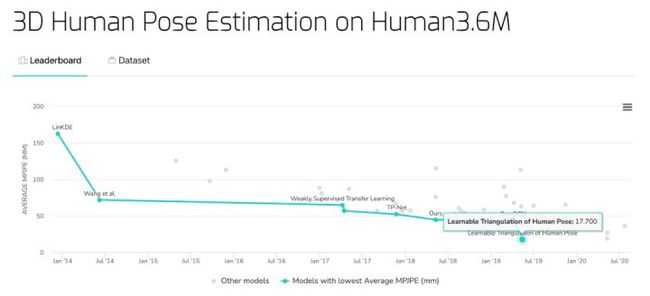
基准地址:https://paperswithcode.com/sota/3d-human-pose-estimation-on-human36m
- Learnable Triangulation of Human Pose 论文地址:https://arxiv.org/pdf/1905.05754v1.pdf
参考链接:https://medium.com/paperswithcode/papers-with-code-2020-review-938146ab9658
发布于 02-15