基于DeeplabV3+的语义分割实现
摘要: 当今机器学习不断发展,成为社会的热点新闻,机器学习能在各个领域不断发展并且应用。其中语义分割是研究最为频繁的领域,在深度学习中,由于分割模型的参数量确实是很大,所用到的算法既耗费时间又耗费精力,于是提出轻量级的DeeplabV3的模型方法,最终实现语义分割的效果。为了实现对图像深度的理解,达到检测识别图片中物体的各类,能够更充分的理解图片的含义,而DeeplabV3是语义分割的新高峰,我们基于DeeplabV3的模型方法在VOC2007公开数据集进行训练预测,该方法为一种轻量级网络,主要包括编码器和解码器两部分,主要的特点是在编码器的部分使用了DCNN(深度卷积神经网络),由它得到深层特征和浅层特征,将深层特征和浅层特征进行融合,实现了图片的语义分割。
关键词:语义分割 机器学习 DeeplabV3
1 前言
随着计算机领域飞速发展,计算机的图像处理被应用在各个行业中,图像分割作为处理图像的基本技术,目的就是要把图像分为各具有自己特征的区域。
目前图像分割[1]主要集中在语义分割,但是目前的瓶颈也是在于“语义”,表达一种语义的同一物体并不总是以同样一模一样的形象出现,也就是说比如可以有同一个意思对应着不同的图像,图像中包含不同的颜色、纹理等,这对精确分割带来了很大的挑战。从图像的发展到视频中的分割,对分割的精确度有着很大的要求,就目前的模型表现来看,在精准率上肯定还有提升空间。除此之外,解决昂贵的数据标注问题也还存在,或许用弱监督甚至无监督训练也是一种方向。
图像分割的方法有两种,一种是实例分割[2][3],是根据图像中的不同类,识别出每个类包含的实例数,将图像分为多个区域,而每一类的实例数目也被区分开来,而另一种方法便是本文的语义分割,语义分割不需要将一种类中的实例分离出来,只需要将识别出的不同类进行相应的分割。
DeeplabV3有两大优点,分别是:1、引入了Multi-Grid策略,即多次使用空洞卷积核(也就是跨像素提取会在下一节方法原理中提到)而不像在v1和v2中仅使用一次空洞卷积[4]。2、优化ASPP的结构,包括加入BN等。主要是利用DeeplabV3当作编码器,设计一个译码器构成一个新的编码器-译码器的结构。DeeplabV3+主要贡献部分是通过空洞卷积网络来控制输出特征图的分辨率,达到准确率和运行时间的平衡效果。
2 方法原理
DeeplabV3模型之所以被称之为语义分割的新高峰,是这个模型实现出来的效果比较理想,模型的架构和引进了可控编码器提取特征出来的分辨率,最后通过空洞卷积将耗时和精度平衡好。DeeplabV3在编码的过程中加入了许多空洞卷积,并且在尽量不损失信息的情况下,扩大了感受野,所谓的空洞,就是在提取特征的情况下会跨像素,也就是会间隔提取特征,如图1所示。

图1 空洞卷积
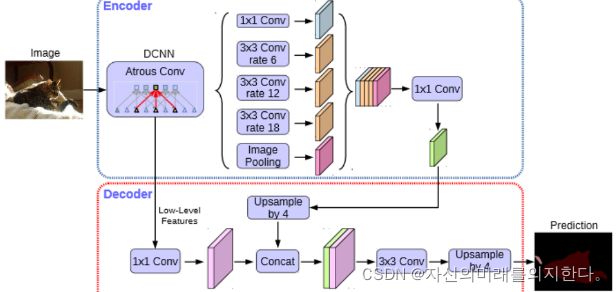
图2 DeeplabV3的主干框架
DeeplabV3的主干框架如图2。在编码的时候,将图片先进入DCNN,同时取出一个低水平的特征以便后续解码所用,这部分DCNN包括四个卷积层和一个图像池化层,四个卷积层分别是1*1卷积层、3*3膨胀率为6的卷积层、3*3膨胀率为12的卷积层、3*3膨胀率为18的卷积层,之后通过这四个卷积层提取出来的特征加上池化层之后的特征,五部分,这五部分称之为ASPP,是深层特征,再经过一个1*1的卷积层得到一个特征图,这个1*1卷积层是为了进行降维,于是编码完成。解码的部分,编码时候经过DCNN并且降维所得到的特征图进行向上采样,将之前在编码时的特征图经过1*1的卷积层得到一个特征图与向上采样得到的特征图进行拼接(concat),得到一个新的特征图之后,于是再经过一个3*3的卷积层,最后向上采样得到预测的效果。
3 实验仿真
VOC数据集准备,VOC2007和2012数据集总共分为四大类:车轮系列、房子相关、动物相关、人,比如车系列包含了汽车、公交车、自行车、摩托车、飞机、船、火车等;房子相关包括家具一些的椅子、沙发、电视、植物等;动物包括猫、狗、牛、马、绵羊、鸟等;最后一种是人类,数据集总
共21个小类(加上背景就是21类)包含类别如下图3。

图3 VOC2017数据集
每一类的右上角的1,2,3数字代表的是年份分别为:2005年,2006,2007。我们将训练集和测试集按照9:1划分,大小分别为10827、1204。可以看到以下是飞机的原图和分割出来的标签,如图4。

图4 飞机的原图和分割出来的标签
轻量级的网络有很多,由于轻量级的网络训练速度快,在部署的时候需要更少的带宽要求,所以轻量级网络被广泛受欢迎。比如:mobilenet系列、xception、shufflenet系列、Ghostnet、SqueezeNet系列、condensenet系列、movenet。
主干网络是MobilenetV2,它属于轻量级的,训练速度快,设备要求不高。Mobilenetv2是mobilenet的升级版,它具有一个非常重要的特点就是使用了inverted resblock组成,inverted resblock的结构是输入经过1*1的卷积层进行升维也就是进行通道数的上升再经过BN层归一化然后经过ReLU6得到之后的特征提取再进入3*3的DW(Depthwise)卷积层逐层卷积相当于进行了跨特征点的特征提取,之后经过BN层和ReLU6,得到之后经过1*1卷积层进行降维也就是通道数的下降和BN层(BatchNorm)得到输出,如下图5所示。

图5 主干网络
图5的上下两边是残差边部分,是输入输出直接相连,中间三块是主干部分。主干部分网络(DCNN)一般进行下采样不会超过5次,利用DCNN(深度卷积网络)得到浅层特征和深层特征
ASPP 如何获得深层的特征进行加强特征提取,分为五个部分,四个膨胀率不同的卷积层和一个池化层,池化层进行两次全局池化,之后通道的整合,完成整合之后,利用上采样的方式把他的shape大小调整成于上面获得的分支调节成一样大小,才能够进行堆叠,即用cat进行堆叠。
浅层特征和深层特征的融合也就是解码的过程,首先获得的浅层特征,浅层特征利用1*1卷积进行通道数的调整,完成通道数的调整之后,调整之后和录得的深层特征上采样之后的进行堆叠,完成堆叠之后对我们获得的特征通过3*3卷积层进行特征提取,最后得到特征图。最后获得的特征进行分类,利用特征获得预测结果。将输出的结果和输入的结果大小一样,保证每个像素点获得种类。运行结果如图6,当然从图中所看到的还有一定的不准确,这也是轻量级网络的不足之处。

图6 运行结果
本次实验的评价指标分别为,计算MIoU、训练集和测试集的损失、类别平均像素的准确率。下面公式1为MIoU的公式。
 (1)
(1)
其中:TP(True Positive)是真正例;FP(False Positive)是假正例;FN(False Negative)是假反例;TN(True Negative)是真反例。最终测试的指标结果是mIoU如图7,训练集和测试集的损失如图8,类别平均像素的准确率如图9。
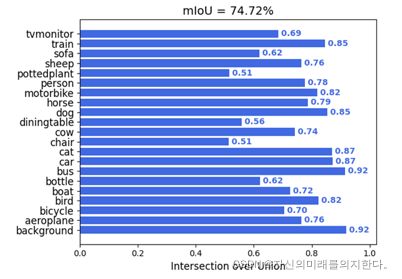
图7 mIoU

图8 训练集和测试集的损失

图9 mPA
语义分割领域虽然研究颇多,但仍然不能松懈,他的应用非常广泛。语义分割还是有许多应用,在大的应用领域可以分为三类,分别是:图像分类(识别图像是什么);图像检测和图像识别(识别图像中的具体位置);图像分割(理解图像的意义)。
图像分类主要是识别图像,它的实际应用例如,分类数字手写体,比如0-9之间的数字识别出来是哪一个数字;而图像检测主要是达到一种“有什么“和“他在哪里”的效果,而本文的图像分割旨在理解图像的含义,达到知道这个图片上的物体是什么类。
比如地质的检测是对土地进行分类而方便观察土地的状态。精准农业领域上,农业机器人可以精准检测到田间里哪里需要除草,哪里需要喷洒,这种图像视觉技术可以减少对农业的人工监测,减轻人力成本,提高农业的效率。自动驾驶的道路、车辆、路况[5]、行人检测[6],自动驾驶[7]需要精准的分割,因为涉及到了人体生命安全,需要在不断变化的环境中既要要求速度又要要求质量,以最高精度致性此任务。面部分割的这部分精准分割对许多面部的应用非常重要。比如:相机上的换脸功能、美颜功能。服装分类是由于服装的类别、材质一般都比较繁琐众多,这个相关领域是一项十分复杂的任务,并且同时服装解析也有了一些研究,在当下现实生活中,服装解析的应用程序有较大的价值。当然在医学领域也很广泛,利用语义分割进行医疗里的病灶分割[8],血管分割。医学影像分割,如各种器官的分割(用于独立器官的三维的vr显示,手术导航),病灶的分割(病灶定靶,体积计算用于诊断等,手术导航,如肿瘤分割)等。
图像分割的技术主要是能够理解图像中的每一个物体,标记住每一个物体,语义分割的实际应用非常广泛,而且到今天的地步语义分割已经发展到了十分精确的地步,仍然不能停下。
4 结论
当然,现如今,语义分割[9]已经做到了很精准的程度,有很多方法能够实现它,但是很多方法急于求成精确度,忽略了时间与空间效率,这就导致了这个问题的很少研究,出现了空缺,在极度追求准确度的时候忘记了时间效率也是很关键的,所有的研究最终都是要落到实践当中去的,语义分割它会被应用到无人机、自动驾驶、机器人等,这些应用都受限于计算消耗和内存空间,这个问题应该被给予重视。考虑到这个问题,我们认为deeplab是相对可靠、比较合理、比较轻量级的方法,其几乎在每个数据集上有超过其他方法。最后在处理视频序列和实时的语义分割的领域同样是一个棘手的区域,未来的研究还需继续。
参考文献
- 杨洁洁,杨顶.基于深度学习的语义分割综述[J].长江信息通信,2022,35(02):69-72.
- 苏丽,孙雨鑫,苑守正.基于深度学习的实例分割研究综述[J].智能系统学报,2022,17(01):16-31.
- 李晓筱,胡晓光,王梓强,杜卓群.基于深度学习的实例分割研究进展[J].计算机工程与应用,2021,57(09):60-67.
- 高明.卷积和空洞卷积及其应用研究[J].信息与电脑(理论版),2021,33(08):77-80.
- 谷湘煜,刘晓熠,周仁彬.多特征融合的道路场景语义分割算法[J].科学技术与工程,2021,21(33):14251-14257.
- 王璐,王帅,张国峰,徐礼胜.基于语义分割注意力与可见区域预测的行人检测方法[J].东北大学学报(自然科学版),2021,42(09):1261-1267.
- 段续庭,周宇康,田大新,郑坤贤,周建山,孙亚夫.深度学习在自动驾驶领域应用综述[J].无人系统技术,2021,4(06):1-27.DOI:10.19942/j.issn.2096-5915.2021.6.051.
- 刘文,亓文霞,仲国强,王佳佳,王大寒.基于Concat-UNet的食管癌肿瘤医学影像分割研究[J/OL].计算机工程:1-9[2022-04-06].http://kns.cnki.net/kcms/detail/31.1289.TP.20220329.1344.002.html
- Chen L C , Papandreou G , Kokkinos I , et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848.
- 侯舟帆, 陈龙, 张亚琛. 基于轻量级网络的实时目标检测与语义分割的多任务学习方法:, CN110941995A[P]. 2020.