对于多目标跟踪模型TraDeS的学习与理解
本文对于CVPR2021发表文章TraDeS(Track to Detect and Segment)进行学习。
TraDeS
之前大多数在线MOT方法的检测器在整个跟踪网络中一般都以backbone作为独立的一部分。也就是说网络的目标检测在没有任何跟踪输入的情况下独立进行。在这篇文章中作者提出了一个新的在线联合检测和跟踪的模型TraDeS,利用了跟踪线索来辅助端到端检测。TraDeS通过a cost volume来推断目标的偏移量,该cost volume用于传播前帧的目标特征以改进当前对象的检测与分割。
Introduction
此前的在线MOT基本上都遵从两个范式:基于目标检测的跟踪算法(Tracking By Detection,TBD)和联合检测与跟踪的端到端算法(Joint Detection and Tracking,JDT)
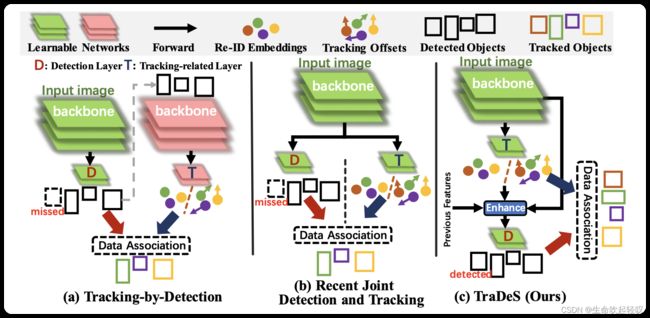
如上图,TBD范式如(a)所示,将检测和跟踪视为两个独立的任务,一般是采用一个现有的检测器如Yolo产生检测结果,然后用另外一个独立的网络来进行数据关联,这也就是传统的目标检测+数据关联前后两个阶段,这样做的效率并不高。
为了解决TBD的问题,JDT应运而生,如(b)所示,它在一次前向传播的过程中同时解决了检测和跟踪的问题。然而JDT目前也面临着两个问题:
- **尽管JDT中提取特征的backbone网络是共享的,然后检测通常依然是独立与跟踪进行的。**也就是说跟踪并没对检测起到反馈作用。而作者认为检测是稳定和一致的轨迹的基石,因此反过来跟踪也能有利于检测,尤其是在一些比较困难的场景如遮挡和运动模糊。
- **ReID跟踪损失与检测损失在同一个网络中并不兼容,甚至跟踪损失会在一定程度上损害检测任务的表现。**这是因为ReID任务关注的是类内差异,而检测的目的是扩大类间差异,最小化类内差异。举个例子,对于行人跟踪而言,ReID任务期待最大化每个人之间的差异,Detection任务则期待最大化不同类别之间目标的差异。
在该论文中,作者提出了TraDeS方法,类似于CenterNet,在该方法中特征图上的每个点表示一个目标中心或者一个背景区域,针对于上述存在的两个问题,作者在TraDeS中设计了一个基于cost volume(代价空间)的关联模块(CVA)和一个运动知道的特征变换模块(MFW)。CVA模块通过backbone提取逐点的ReID embedding特征来构建一个cost volume,这个cost volume存储两帧之间的embedding对之间的匹配相似度。所以模型可以根据cost volume推断跟踪偏移,即所有点的时空位移,也就得到了两帧间潜在的目标中心。跟踪偏移和embedding一起被用来构建一个简单的两轮长程数据关联。之后MFW模块以跟踪偏移作为运动线索来将目标的特征从前一帧传到后一帧,最后,对于前一帧传来的特征和当前帧的特征进行聚合,以此进行当前帧的检测和分割任务。
在CVA模块中,cost volume被用来监督ReID embedding,不同的目标类别和背景区域被考虑到,也就是说ReID分支的学习目标考虑了类间差异。因此,它不仅可以学到有效的embedding而且能够兼容检测损失从而不会损害检测性能。除此之外,因为tracking offset是基于外观特征相似度得到的,因此它可以匹配一个大幅度运动的目标或者在低帧率下工作,甚至能跟踪不同数据集之间的目标。因此预测的tracking offset可以作为鲁棒的运动线索来指导MFW模块中的特征传播。当前帧被遮挡或者模糊的目标在之前的帧中可能是清晰的,也就是是说我们可以通过MFW模块,传播前一帧的特征支持当前帧去恢复潜在的不可见目标。
TraDeS是一个新的在线多目标跟踪器,该模型深度集成跟踪线索从而辅助检测,而加强后的检测又能够帮助跟踪,两者相辅相成,检测不再独立于跟踪,带来了更好的跟踪效果。接下来进一步对TraDeS的底层逻辑进行学习。
CenterNet
TraDeS是基于CenterNet的工作,CenterNet以图片 I ∈ R H × W × 3 I∈\mathbb{R}^{H×W×3} I∈RH×W×3并通过backbone网络生成基本的特征图 f = ϕ ( I ) , f ∈ R H F × W F × 64 f=ϕ(I),f∈\mathbb{R}^{H_{F}×W_{F}×64} f=ϕ(I),f∈RHF×WF×64,其中 H F = H 4 , W F = W 4 H_{F}=\dfrac{H}{4},W_{F}=\dfrac{W}{4} HF=4H,WF=4W
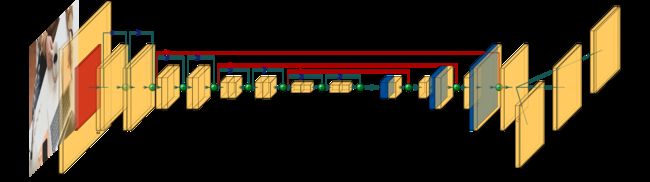
如图所示,生成基本特征图后,一系列的head被设计用于各种任务。如heatmaps head经过卷积变换产生特征图 P ∈ R H F × W F × N c l s P∈\mathbb{R}^{H_{F}×W_{F}×N_{cls}} P∈RHF×WF×Ncls以及2D尺寸特征图和偏移特征图等。其中 N c l s N_{cls} Ncls是目标类别数,CenterNet通过特征图 P P P上的峰值点作为待检测目标的中心,通过预测距离中心点的距离来估计目标的尺寸。在文章中,作者构建的baseline跟踪器是基于CenterTrack的,它是在CenterNet的基础上添加了一个位移预测分支 O B ∈ R H F × W F × 2 O^{B}∈\mathbb{R}^{H_{F}×W_{F}×2} OB∈RHF×WF×2进行数据关联, O B O^{B} OB计算的是当前帧 t t t到之前帧 t − τ t-τ t−τ的时空位移。
TraDeS跟踪器
为了实现跟踪辅助检测的目标,作者设计了Cost Volume based Association(CVA)模块和Motion-guided Feature Warper(MFW)模块,前者用于学习ReID embedding和产生目标运动,后者则用于利用CVA产生的跟踪线索来传播和增强目标的特征。

如上图所示,TraDeS可以从多个先前帧传播特征以增强对象特征。下面是关于对t和t-1帧的处理。
基于cost volume的数据关联
对于给定的两帧图像 I t I^{t} It和 I t − τ I^{t−τ} It−τ,它们通过backbone(即上图的ϕ网络)产生的特征图为 f t f^{t} ft和 f t − τ f^{t−τ} ft−τ,随后特征图被送入一个三层卷积构成的模块中提取ReID embedding,得到的特征图为 e t = σ ( f t ∈ R H F × W F × 128 ) e^{t}=σ(f^{t}∈\mathbb{R}^{H_{F}×W_{F}×128}) et=σ(ft∈RHF×WF×128),需要注意的是,这个ReID提取网络每一帧之间都是权重共享的。
接下来是关键的计算一个cost volume来保存两帧之间特征图上每两个点之间的匹配相似度。首先为了降低计算量,先用最大池化MP对ReID embedding进行下采样,得到 e ′ = ∈ R H C × W C × 128 e'=∈\mathbb{R}^{H_{C}×W_{C}×128} e′=∈RHC×WC×128,其中 H C = H F 2 , W C = W F 2 H_{C}=\dfrac{H_{F}}{2},W_{C}=\dfrac{W_{F}}{2} HC=2HF,WC=2WF,也就是说每张特征图上有 H C × W C H_{C}×W_{C} HC×WC个目标的embedding向量,因此需要计算得到两个特征图上任意两个点之间的相似度矩阵,即cost volume,它表示为 C ∈ R H C × W C × H C × W C C∈\mathbb{R}^{H_{C}×W_{C}×H_{C}×W_{C}} C∈RHC×WC×HC×WC,代表图像 I t I^{t} It和 I t − τ I^{t-τ} It−τ之间的cost volume,其计算方法如下:
C i , j , k , l = e i , j ′ t e k , l ′ t − τ ⊤ C_{i,j,k,l}=e'^{t}_{i,j}e'^{t−τ}_{k,l}⊤ Ci,j,k,l=ei,j′tek,l′t−τ⊤
其中的元素 C i , j , k , l C_{i,j,k,l} Ci,j,k,l表示帧 t t t上的一点 ( i , j ) (i,j) (i,j)和帧 t − τ t-τ t−τ上的点 ( k , l ) (k,l) (k,l)之间的embedding相似度,这部分对应图上Cost Volume Map部分。
得到C之后就可以通过C计算跟踪偏移矩阵 O ∈ R H C × W C × 2 O∈\mathbb{R}^{H_{C}×W_{C}×2} O∈RHC×WC×2,这个矩阵存储的是 t t t时刻上的每个点相对于其在 t − τ t-τ t−τ时刻的那个点的时空位移,其中 O i , j ∈ R 2 O_{i,j}∈\mathbb{R}^{2} Oi,j∈R2。

如上图 O C O^{C} OC部分所示,对于帧 t t t上的中心 ( i , j ) (i,j) (i,j)目标x而言,可以从C即cost volume中得到其对应的二维cost volume map C i , j ∈ R H C × W C C_{i,j}∈\mathbb{R}^{H_{C}×W_{C}} Ci,j∈RHC×WC,它表示着点x和帧t − τ上所有点的匹配相似度.
通过 C i , j C_{i,j} Ci,j计算 O i , j ∈ R 2 O_{i,j}∈\mathbb{R}^{2} Oi,j∈R2有以下两个步骤:
- 首先,横竖两个方向的最大池化分别作用于 C i , j C_{i,j} Ci,j,其中池化核大小分别为 H C × 1 H_{C}×1 HC×1和 1 × W C 1×W_{C} 1×WC,然后经过softmax函数,得到两个向量 C i , j H ∈ [ 0 , 1 ] H C × 1 C^{H}_{i,j}∈[0,1]^{H_{C}×1} Ci,jH∈[0,1]HC×1和 C i , j W ∈ [ 0 , 1 ] 1 × W C C^{W}_{i,j}∈[0,1]^{1×W_{C}} Ci,jW∈[0,1]1×WC,其中 C i , j W C^{W}_{i,j} Ci,jW和 C i , j H C^{H}_{i,j} Ci,jH分别包含了对象x出现在t − τ帧上出现在指定的水平位置和竖直位置的概率。例如 C i , j , l H C^{H}_{i,j,l} Ci,j,lH表示目标x出现在t − τ帧上(l,*)位置的概率。
- 然后,因为 C i , j W C^{W}_{i,j} Ci,jW和 C i , j H C^{H}_{i,j} Ci,jH提供了x在之前帧上指定位置的概率,为了获取最终的偏移,作者定义了两个偏移模版对应两个方向,它表明x实际出现在那些位置的偏移值。记这两个模版为 M i , j ∈ R 1 × W C M_{i,j}∈\mathbb{R}^{1×W_C} Mi,j∈R1×WC和 V i , j ∈ R H C ′ × 1 V_{i,j}∈\mathbb{R}^{H'_C×1} Vi,j∈RHC′×1,通过以下公式得到:
{ M i , j , l = ( l − j ) × s , 1 ≤ l ≤ W C V i , j , k = ( k − i ) × s , 1 ≤ k ≤ H C \begin{cases} M_{i,j,l}=(l-j)×s, & 1\leq l \leq W_C\\ V_{i,j,k}=(k-i)×s, & 1\leq k \leq H_C \end{cases} {Mi,j,l=(l−j)×s,Vi,j,k=(k−i)×s,1≤l≤WC1≤k≤HC
其中s为特征图相对于原图的下采样倍率,在TraDeS为8。 M i , j , l M_{i,j,l} Mi,j,l指目标x在帧t-τ上出现在(*,l)位置的偏移量。最终的跟踪偏移可以通过相似度和实际偏移值的点积计算得到:

由于O的维度为 H C × W C H_C × W_C HC×WC,因此通过两倍上采样变成 O C ∈ R H F × W F × 2 O^C∈\mathbb{R}^{H_F × W_F ×2} OC∈RHF×WF×2作为MFW模块的运动线索。
在CVA模块中,优化目标就是学到有效的ReID embedding e。但是CVA并不只像很多ReID模型那样通过损失直接监督e,而是监督cost volume。为了构建训练监督的标签Y,当t帧上的(i,j)位置的目标在帧t-τ上的(k,l)位置时,令 Y i j k l = 1 Y_{ijkl}=1 Yijkl=1,否则为0。CVA的训练损失按focal loss形式的逻辑回归损失来计算。
由于 C i , j , l W C^{W}_{i,j,l} Ci,j,lW和 C i , j , k H C^{H}_{i,j,k} Ci,j,kH是通过softmax计算得到,其不仅包含(i,j)和(k,l)之间的嵌入相似度,还包含(i,j)和之前帧上所有点的相似度。
综上所述,不同传统的ReID损失,CVA损失不仅仅要求学习的embedding考虑类内差异,也要求其考虑类间差异。这种处理方式不会损害到检测任务的学习。此外,由于tracking offset是基于外观相似度计算到的,所以它能在较大的运动范围内跟踪目标,因此也能作为非常有效的运动线索,而且同时使用外观嵌入和跟踪偏移,可以保证准确的数据关联。
运动指导的特征变换
在CVA模块后,紧跟着是MFW模块,它根据CVA生成的跟踪偏移 O C O^C OC来将跟踪线索从特征图 f t − τ f^{t-τ} ft−τ变换传播到当前帧来完善增强 f t f^t ft。为了实现这个目的,作者通过单个可变形卷积来进行高效的时序传播,继而聚合传播的特征来增强 f t f^t ft。
传播特征:首先,记 O D ∈ R H F × W F × 2 K 2 O^D\in \mathbb{R}^{H_F × W_F × 2K^2} OD∈RHF×WF×2K2为DCN两个方向的输入偏移,取K=3作为DCN核的宽和高。为了生成 O D O^D OD,首先经过3×3卷积对 O C O^C OC进行变换(γ)。为了获得更多的运动线索,采用 f t − F t − τ f^t-F^{t-τ} ft−Ft−τ 作为γ (·)的输入。由于该检测核分割任务是基于目标中心特征进行的,相比于直接变换 f f − τ f^{f-τ} ff−τ,作者在这里将其先计算为一个中心注意力图 f ‾ t − τ ∈ R H F × W F × 64 \overline{f}^{t-τ}\in \mathbb{R}^{H_F × W_F ×64} ft−τ∈RHF×WF×64,计算公式如下:
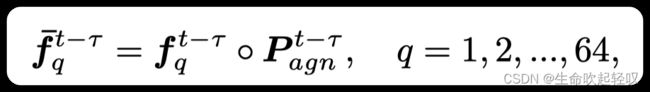
其中q为通道索引,∘表示Hadamard积, P a g n t − τ ∈ R H F × W F × 1 P^{t-τ}_{agn} \in \mathbb{R}^{H_F × W_F × 1} Pagnt−τ∈RHF×WF×1则是类别无关的中心热度图,然后通过DCN可以计算传播特征 f ^ t − τ = D C N ( O D , f ‾ t − τ ) ∈ R H F × W F × 64 \hat{f}^{t-τ}=DCN(O^D,\overline{f}^{t-τ})\in \mathbb{R}^{H_F × W_F ×64} f^t−τ=DCN(OD,ft−τ)∈RHF×WF×64。
考虑到当前帧目标可能遮挡或者模糊,之前帧传播的特征可以融合到当前帧特征上来增强表示。当前帧特征为 f t f^t ft,之前帧传播的特征为 f ^ t − τ \hat{f}^{t-τ} f^t−τ,加权求和的增强特征通过以下公式计算得到:

w t ∈ R H F × W F × 1 w^t \in \mathbb{R}^{H_F × W_F × 1} wt∈RHF×WF×1为帧的自适应权重,其中T表示用于聚合的之前帧数目。融合后的特征被用于后续的head部分,生成检测框或者掩膜完成检测和分割任务。
轨迹生成
TraDeS可以适应三种不同的head以处理检测和分割任务。
对于一个检测或者分割部分d,处在位置(i,j),首先进行DA-Round(1),首先将其和t-1帧上未匹配的检测框进行关联,该检测必须在以r为半径的中心点在 ( i , j ) + O i , j C (i,j)+O^C_{i,j} (i,j)+Oi,jC的范围内,其中r是检测框宽高的几何平均值, O i , j C O^C_{i,j} Oi,jC表示图像 I t I^t It和 T t − 1 T^{t-1} Tt−1的跟踪偏移。接着进行DA-Round(2),这里考虑d在第一轮没有匹配上任何目标的情况,将其embedding e i , j t e^t_{i,j} ei,jt与未匹配的或者历史轨迹段的embedding计算余弦相似度,d将和具有最高相似度且高于某个阈值的轨迹段关联上。第二轮匹配适用于长期关联,如果两轮d都没有匹配上,则将其视为新轨迹的产生。
TraDeS设计了一种新的online MOT框架,它是基于JDT范式的,致力于让跟踪辅助检测任务的进行,设计的CVA模块和MFW模块着重改善了JDT范式的两个问题,取得了不错的表现。因此,个人认为CVA模块和MFW模块作为优点可以部分融合到CTracker上,利用跟踪线索辅助进行检测。