PaddleNLP系列课程一:Taskflow、小样本学习、FasterTransformer
文章目录
-
- 一、Taskflow
-
- 1.1 前言
- 1.2 Taskflow应用介绍
-
- 1.2.1 词法分析
- 1.2.2 命名实体识别
- 1.2.3 文本纠错
- 1.2.4 句法分析
- 1.2.5 情感分析
- 1.2.6 文本生成应用(三行代码体验 Stable Diffusion)
- 1.2.7 使用技巧(保存地址、批量推理)
- 二、 小样本学习(Prompt Tuning 三种典型算法详解)
-
- 2.1 小样本学习背景
- 2.2 预训练模型的标准范式`Pre-train+Fine-Tune`
- 2.3 预训练时代新范式prompt-based learning
-
- 2.3.1 前言
- 2.3.2 PET:基于人工模板释放预训练模型潜力
- 2.3.3 P-Tuning:连续空间可学习模板
- 2.3.4 EFL:将所有任务都转为蕴含任务
- 2.4 `R-Drop`策略:显著提升模型效果(附代码示例)
-
- 2.4.1 R-Drop算法原理
- 2.4.2 训练过程
- 2.4.3 R-Drop策略效果
- 2.4.4 RDrop 代码使用示例
- 2.4.5 总结
- 2.4.6 总结
- 三、FasterTransformer:针对Transformer的高性能加速
-
- 3.1 Transformer性能瓶颈
- 3.2 FasterTransformer整体结构
- 3.3 优化策略:融合kernel
-
- 3.3.1 encoder融合
- 3.3.2 decoder融合
- 3.3.3 decoding 融合
-
- 3.3.3.1 解码策略(Greedy Search、Beam Search、T2T Beam Search)
- 3.3.3.2 decoding优化
- 3.4 优化策略总结
- 3.5 Faster Transformer的使用和总结

课程链接《AI快车道PaddleNLP系列》、PaddleNLP项目地址、PaddleNLP文档
一、Taskflow
Taskflow文档、AI studio《PaddleNLP 一键预测功能 Taskflow API 使用教程》
1.1 前言
百度同传:轻量级音视频同传字幕工具,一键开启,实时生成同传双语字幕。可用于英文会议、英文视频翻译等等。
- PaddleNLP框架主要结构
PaddleNLP:飞浆自然语言处理开发库,架构如下- 底层是PaddlePaddle,一些API、算子都是这里实现。
- 文本领域API:文本加载(Data/Dataset)、预处理(Seq2Vec、Embedding)、评估指标(metrics、losses)、Transformer模型
- 产业级模型库,包括两部分:
- 预训练模型:比如通用预训练模型ERNIE系列、对话领域模型PLATO-2、情感分析模型SKEP
- 场景应用模型:
- PaddleNLP2.1:推出产业级预置任务框架Taskflow
- PaddleNLP v2.4:发布NLP 流水线系统 Pipelines
- PaddleNLP2.4.4:新增Huggingface Hub集成,PaddleHub/PaddleNLP/PaddleDetection/Taskflow等将直接从
Huggingface Hub加载。

- Taskflow:旨在提供的开箱即用的NLP预置任务能力,覆盖自然语言理解与生成两大场景,提供产业级的效果与极致的预测性能。从结构上看,分为前处理、推理、后处理三个部分:
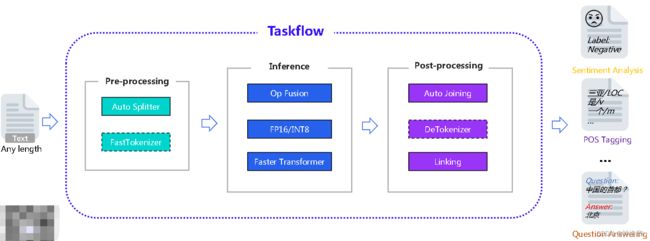
- AutoSplitter:自动截断,可以处理任何长度的文本输入序列
- FastTokenizer:文本编码为向量
- OpFusion:算子融合
- FP16/INT8:精度转换
- FasterTransformer:常用的主流BERT/GPT等模型的加速模块,与英伟达工程师共同开发维护,可以提高翻译/对话等文本任务的速度。
- AutoJoining/DeTokenizer:分别对应AutoSplitter和FastTokenizer,输出模型处理结果。
1.2 Taskflow应用介绍
Taskflow覆盖自然语言理解与生成两大场景:
- NLU:中文分词、词性标注、命名实体识别、文本纠错、句法分析、情感分类等等
- NLG:生成式问答、写作、文本翻译、开放域对话等等。最近还集成了文生图( Stable Diffusion)
1.2.1 词法分析
词法分析:利用计算机对自然语言的形态(morphology) 进行分析,判断词的结构和类别等。简单而言,就是分词并对每个词进行分类,所以是包含了分词、词性标注、命名实体识别(NER)三个任务。NER相当于更细粒度的词性标注。
词法分析是自然语言处理基础且重要的任务。它是信息检索、信息抽取等应用的重要基础;可用于辅助其他自然语言任务,如句法分析、文本分类、问答对话等。

- 中文分词示例
# 通过任务名word_segmentation实例化Taskflow分词任务
from paddlenlp import Taskflow
seg= Taskflow('word_segmentation')
seg('三亚是一个美丽的城市')
['三亚', '是', '一个', '美丽', '的', '城市']
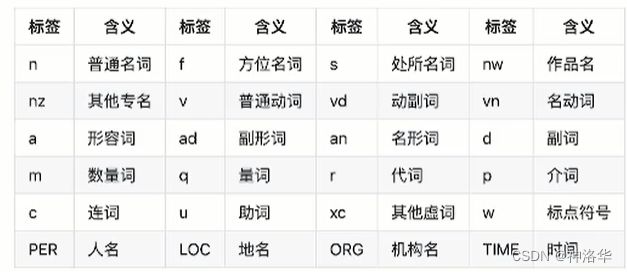
- 词性标注
from paddlenlp import Taskflow
seg= Taskflow('pos_tagging')
seg('三亚是一个美丽的城市')
[('三亚', 'LOC'), ('是', 'v'), ('一个', 'm'), ('美丽', 'a'), ('的', 'u'), ('城市', 'n')]
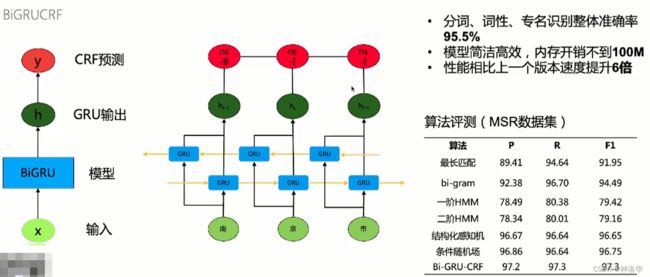
分词和词性标注都是使用BiGRUCRF模型训练的,输入文本经过双向GRU输出文本特征,然后以词性为标签进行训练。预测时使用CRF比直接softmax预测更准。
1.2.2 命名实体识别
- 命名实体识别:旨在识别自然语言文本中具有特定意义的实体(人物、地点、时间、机构、作品等)。
Taskflow(NER):基于解语框架的命名实体识别
ner= Taskflow('ner')
ner('美人鱼是周星驰执导的电影')
[('美人鱼', '作品类_实体'),
('是', '肯定词'),
('周星驰', '人物类_实体'),
('执导', '场景事件'),
('的', '助词'),
('电影', '作品类_概念')]
传统NER方案有一些不足,比如:
- 粒度切分不一致(基础粒度、混合粒度)
- 词兼类现象严重,区分特征弱(n/nz/nt/nw/vn/an),就是一个词包含混合实体,比如:“伦敦市长”
- 只识别部分实体类。模型只能区分训练到的实体内容,其它实体无法识别,所以是远远不够的。
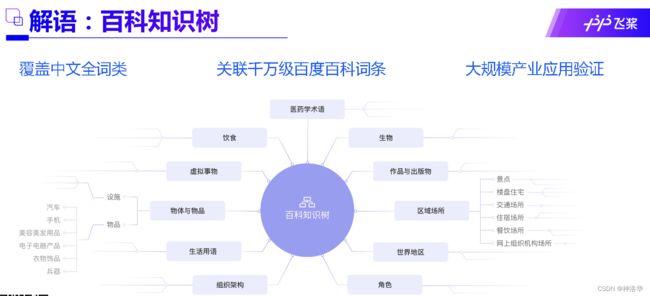
PaddleNLP - 解语:解语(Text to Knowledge)是首个覆盖中文全词类的知识库(百科知识树)及知识标注框架,拥有可描述所有中文词汇的词类体系、中文知识标注工具集,以及更适用于中文挖掘任务的预训练语言模型。

1.2.3 文本纠错
1. 示例
文本纠错就是对语法错误的句子进行纠正。示例如下:
corrector= Taskflow('text_correction')
corrector(['人生就是如此,经过磨练才能让自己更加拙壮','遇到逆竟时,我们必须勇于面对'])
[{'source': '人生就是如此,经过磨练才能让自己更加拙壮',
'target': '人生就是如此,经过磨练才能让自己更加茁壮',
'errors': [{'position': 18, 'correction': {'拙': '茁'}}]},
{'source': '遇到逆竟时,我们必须勇于面对',
'target': '遇到逆境时,我们必须勇于面对',
'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]
2. 文本纠错方案:
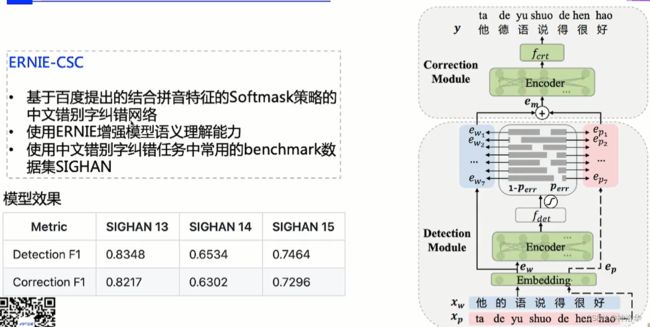
针对文本纠错任务,PaddleNLP使用的是2021年提出的专门针对中文文本纠错的模型ERNIE-CSC。
- 论文:《CorrectingChineseSpellingErrorswithPhoneticPre-Training.,ACL.,2021》。
- 结构:整个模型分为两个模块。第一个是检测模型,用于判断每个词是错别字的概率。第二个是校正模块,对检测出来的错别字进行校正。
- 训练样本来自百度线上千万级的文本。
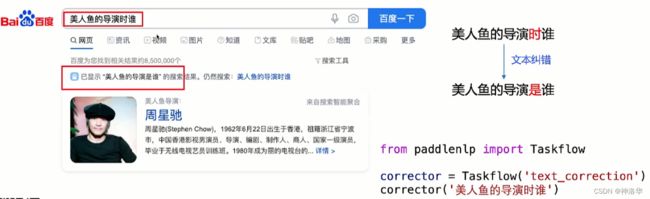
3. 文本纠错应用场景 - 应用于搜索场景,用户输入的预处理上。如果不纠正,就可能匹配到不相关的内容
- 集成到OCR(文字识别)、ACR(语音识别)中。
- OCR中,因为连笔、模糊等原因,没有办法正确识别出每一个字。通过文本纠错的辅助,就可以将识别的错别字进行校正。
- ASR同理

1.2.4 句法分析
句法分析定义如下:
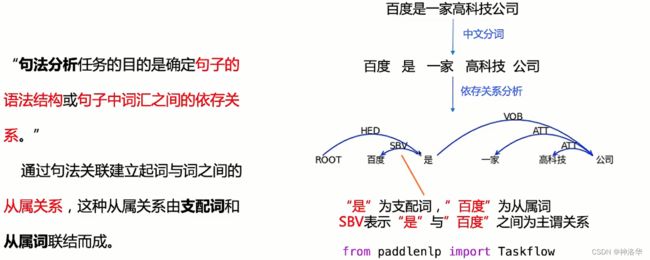
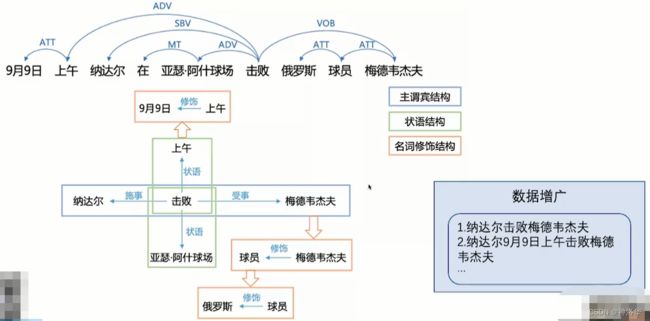
Taskflow句法分析任务,使用了百度建造的DuCTB1.0数据库,是目前最大的中文依存句法数据库。

2. 模型方案
Taskflow句法分析使用了Deep Biaffine Attention和百度依存句法分析工具DDParser。
DDParser训练数据不仅覆盖了多种输入形式的数据,如键盘输入query、语音输入query,还覆盖了多种场景的数据,如新闻、论坛。该工具在随机评测数据上取得了优异的效果。同时,该工具使用简单,一键完成安装及预测。
- 文本经过
BiLSTM、MLP、Biaffine Attention三个模块之后得到文本特征 - S a r c , S r e l S^{arc},S^{rel} Sarc,Srel分别表示下面例子中“公司”为“是”的从属概率和依赖概率。
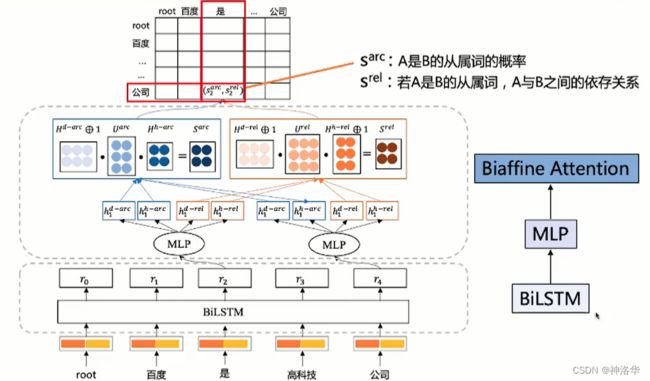
将backbone从BiLSTM替换为ERNIE之后,模型精度从91.7%提升到95.6%,但是推理速度会有所下降,可以自行选择。
from paddlenlp import Taskflow
ddp= Taskflow('dependency_parsing',model='ddparser-ernie-1.0')
ddp('百度是一家高科技公司')
[{'word': ['百度', '是', '一家', '高科技', '公司'],
'head': [2, 0, 5, 5, 2],
'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB']}]
- 应用场景
- 数据增广:抽取句子依存关系之后,可以在保持句子语义不变的情况下生成多个句子,达到数据增广的效果
1.2.5 情感分析
-
背景:文本可以分为客观性文本和主观性文本。随着互联网的兴起,这方面的需求和应用也很普遍。
-
定义:情感分析又称意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,具体来说,对于给定的主观文本,输出如下五元组:
- 实体:描述目标实体或者物体
- 维度:描述/评价实体的某一/某些方面
- 情感:积极,消极,中性,打分,情绪等
- 观点持有者:发表观点的人
- 发表时间:发表观点的时间
-
示例:
from paddlenlp import Taskflow
senta= Taskflow('sentiment_analysis')
senta('昨天我买了一台新的iphone手机,它的触摸屏做的非常精致酷炫')
[{'text': '昨天我买了一台新的iphone手机,它的触摸屏做的非常精致酷炫',
'label': 'positive',
'score': 0.969430685043335}]
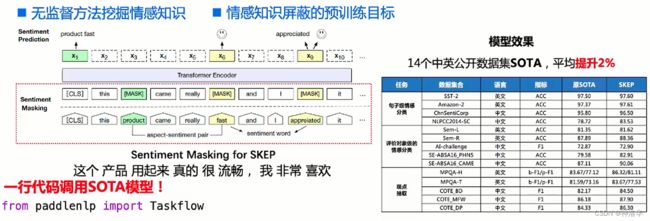
- 方案:使用百度2020年提出的情感增强知识模型SKEP(SentimentKnowledgeEnhancedPre-training),SKEP通过MLM无监督的方式在海量的数据中挖掘大量的情感知识。
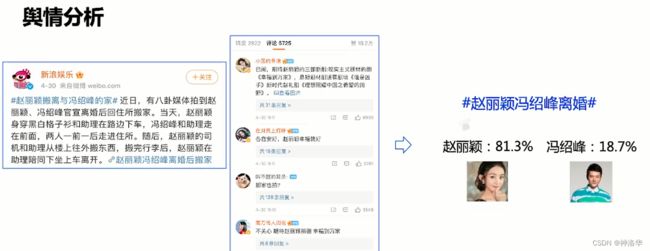
- 应用场景:消费决策、舆论分析等。比如下面的微博评论,通过情感分析可知,有81.3%的网友支持赵丽颖,这就得到了一个大概的舆论导向。
1.2.6 文本生成应用(三行代码体验 Stable Diffusion)
- 智能问答。问答模型默认是9.7G大的GPT-cpm-Large-cn,加载很慢
- 写诗
- 文生图:三行代码体验 Stable Diffusion
from paddlenlp import Taskflow
# 智能问答
qa=Taskflow('question anwser')
qa('中国国土面积有多大')
[{'text': '中国国土面积有多大', 'answer': '960万平方公里。'}]
# 智能写诗
portry=Taskflow('poetry_generation')
portry('深山不见人')
[{'text': '深山不见人', 'answer': ',明月来相照。'}]
# 文生图
text_to_image = Taskflow("text_to_image", model="CompVis/stable-diffusion-v1-4")
image_list = text_to_image('"In the morning light,Chinese ancient buildings in the mountains,Magnificent and fantastic John Howe landscape,lake,clouds,farm,Fairy tale,light effect,Dream,Greg Rutkowski,James Gurney,artstation"')
文生可选参数:
model:可选,默认为pai-painter-painting-base-zh。
另外支持的还有[“dalle-mini”, “dalle-mega”, “dalle-mega-v16”, “pai-painter-painting-base-zh”, “pai-painter-scenery-base-zh”, “pai-painter-commercial-base-zh”, “CompVis/stable-diffusion-v1-4”, “openai/disco-diffusion-clip-vit-base-patch32”, “openai/disco-diffusion-clip-rn50”, “openai/disco-diffusion-clip-rn101”, “disco_diffusion_ernie_vil-2.0-base-zh”]。num_return_images:返回图片的数量,默认为2。特例:disco_diffusion模型由于生成速度太慢,因此该模型默认值为1。
Disco Diffusion-2.0-base-zh模型,支持中文:
# 注意,该模型生成速度较慢,在32G的V100上需要10分钟才能生成图片,因此默认返回1张图片。
text_to_image = Taskflow("text_to_image", model="disco_diffusion_ernie_vil-2.0-base-zh")
image_list = text_to_image("一幅美丽的睡莲池塘的画,由Adam Paquette在artstation上所做。")
for batch_index, batch_image in enumerate(image_list):
for image_index_in_returned_images, each_image in enumerate(batch_image):
each_image.save(f"disco_diffusion_ernie_vil-2.0-base-zh-figure_{batch_index}_{image_index_in_returned_images}.png")
支持复现生成结果 (以Stable Diffusion模型为例)
from paddlenlp import Taskflow
text_to_image = Taskflow("text_to_image", model="CompVis/stable-diffusion-v1-4")
prompt = [
"In the morning light,Chinese ancient buildings in the mountains,Magnificent and fantastic John Howe landscape,lake,clouds,farm,Fairy tale,light effect,Dream,Greg Rutkowski,James Gurney,artstation",
]
image_list = text_to_image(prompt)
for batch_index, batch_image in enumerate(image_list):
# len(batch_image) == 2 (num_return_images)
for image_index_in_returned_images, each_image in enumerate(batch_image):
each_image.save(f"stable-diffusion-figure_{batch_index}_{image_index_in_returned_images}.png")
# 如果我们想复现promt[0]文本的第二张返回的结果,我们可以首先查看生成该图像所使用的参数信息。
each_image.argument
# {'mode': 'text2image',
# 'seed': 2389376819,
# 'height': 512,
# 'width': 512,
# 'num_inference_steps': 50,
# 'guidance_scale': 7.5,
# 'latents': None,
# 'num_return_images': 1,
# 'input': 'In the morning light,Chinese ancient buildings in the mountains,Magnificent and fantastic John Howe landscape,lake,clouds,farm,Fairy tale,light effect,Dream,Greg Rutkowski,James Gurney,artstation'}
# 通过set_argument设置该参数。
text_to_image.set_argument(each_image.argument)
new_image = text_to_image(each_image.argument["input"])
# 查看生成图片的结果,可以发现最终结果与之前的图片相一致。
new_image[0][0]
1.2.7 使用技巧(保存地址、批量推理)
- Taskflow默认会将任务相关模型等文件保存到
$HOME/.paddlenlp下,可以在任务初始化的时候通过home_path自定义修改保存路径
from paddlenlp import Taskflow
ner = Taskflow("ner", home_path="/workspace")
- 批量推理,速度更快。
# 精确模式模型体积较大,可结合机器情况适当调整batch_size,采用批量样本输入的方式。
seg_accurate = Taskflow("word_segmentation", mode="accurate", batch_size=32)
# 批量样本输入,输入为多个句子组成的list,预测速度更快
texts = ["热梅茶是一道以梅子为主要原料制作的茶饮", "《孤女》是2010年九州出版社出版的小说,作者是余兼羽"]
seg_accurate(texts)
其它用法请参考Taskflow文档。
二、 小样本学习(Prompt Tuning 三种典型算法详解)
课程《自然语言处理中的小样本学习》、PaddleNLP小样本学习项目地址、Prompt Learning、《提示学习:Prompt API》
2.1 小样本学习背景
- 什么是小样本学习
Few-Shot Learning旨在研究如何从少量有监督的训练样本中学习出具有良好泛化性的模型,对训练数据很少或监督数据获取成本极高的应用场景有很大价值(比如每个类只有4/8/16个样本)。小样本学习和人类的学习场景是很相似的,可以认为是人类学习的一种模拟。只有搞定了小样本学习,才能说模型具有了一定的人类智能。


现实生活中,很多场景都只有很少的样本,比如疾病辅助诊断、推荐系统冷启动(比如新用户)、新药发现。这些场景都不可能获取大量标注数据。 - NLP领域发展历程
- 2015年之前:机器学习时代
- 2015——2018:深度学习时代,使用模型fasttext、LSTM、CNN等
- 2018.10——2020.1:BERT发布,进入预训练时代
- 2020.1至今:2020.1发布了PET,预训练时代新范式Prompt Tuning
- 小样本学习方法:主要有数据增强、模型、算法三个方面。本章主要讲算法部分(PET、P-Tuning、EFL)。
2.2 预训练模型的标准范式Pre-train+Fine-Tune
- 预训练模型综述:《Pre-trained Models for Natural Language Processing: A Survey》
(2020.3.18)
自从BERT发布以来,使用大规模预训练模型PTMs(Large-scale pre-trained models )进行微调已经成为了NLP领域各种任务的标准解决方案,即Pre-train+Fine-Tune范式。这种范式在数据密集场景大获成功,比如权威语言理解评测数据集GLUE上,排名前50都是这种范式的模型。
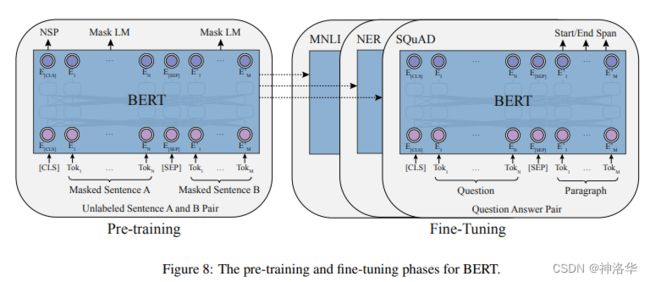
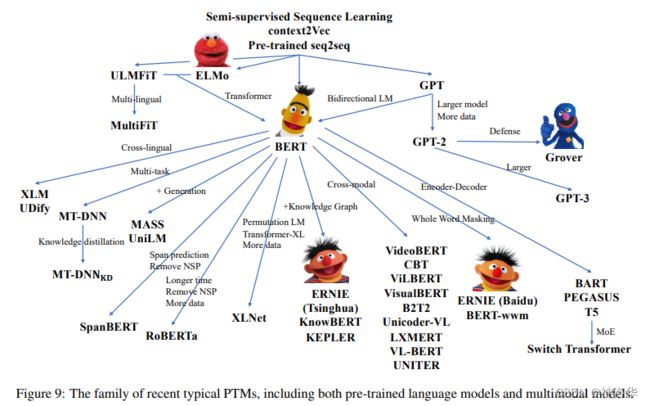
2.3 预训练时代新范式prompt-based learning
prompt综述:《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》(2021.7.28)- 论文笔记:《Pre-train, Prompt, and Predict: 自然语言处理中prompting方法总结》、《Prompt统一NLP新范式Pre-train, Prompt, and Predict》
2.3.1 前言
既然标准范式如此成功,那么为什么要提出Prompt Tuning呢?
主要就是因为Pre-train+Fine-Tune的标准范式在小样本场景效果不好,很容易过拟合。由此,后续研究者提出了新的范式:PromptTuning。PromptTuning在小样本学习大放异彩,取得了更好的效果。
那到底什么是prompt呢?
预训练语言模型(比如BERT),含有很全面的语言知识,并没有针对特定的下游任务,所以直接迁移学习的时候,可能模型不够明白你到底要解决什么问题,要提取哪部分知识,最后效果也就不够好。标准范式pre-train, fine-tune转变为新范式pre-train, prompt, and predict之后,不再是通过目标工程使语言模型(LMs)适应下游任务,而是在文本提示(prompt)的帮助下,重新制定下游任务,使其看起来更像原始LMs训练期间解决的任务。 所以说,Prompt的核心思想,就是通过人工提示,把预训练模型中特定的知识挖掘出来。
传统的监督学习训练模型接收输入 x x x,并将输出 y y y预测为 P ( y ∣ x ) P(y|x) P(y∣x) ,
prompt-based learning则是直接建模文本概率的语言模型。为了使用这些模型执行预测任务,使用模板将原始输入 x x x修改为具有一些未填充槽的文本字符串提示 x ′ {x}' x′,然后使用语言模型重构未填充信息以获得最终字符串 ,从中可以导出最终输出 。
下面就介绍新范式的三种主要算法:PET、P-Tuning、EFL。
2.3.2 PET:基于人工模板释放预训练模型潜力
论文《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》
(2020.1.21)
1. PET(PatternExploitingTraining)核心思想:

比如上新闻分类示例。如果是传统做法就是一个多分类任务。改用PET方法之后,就人工设计一个PET模板下面是[MASK][MASK]新闻。,然后把这个模板和原句子上拼接起来作为一个整体,让模型预测被MASK掉的字符。这样就将一个分类任务转变为一个MLM任务,和模型预训练的任务是一样的。而且通过这种人工设计的模板(明确的提示要进行新闻分类),可以充分挖掘出预训练模型的知识,做出更精准的预测。
2. 模型效果
下面是 RoBERTa (large)使用PET方法和传统方法在四个数据集上的精度对比:
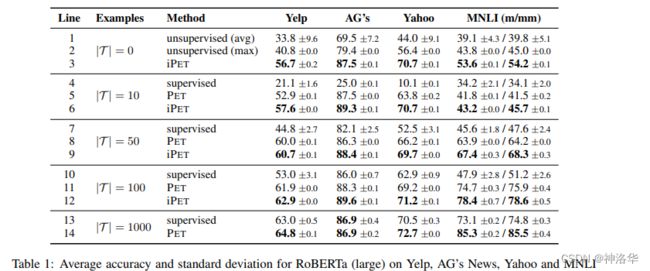
画出来就是:
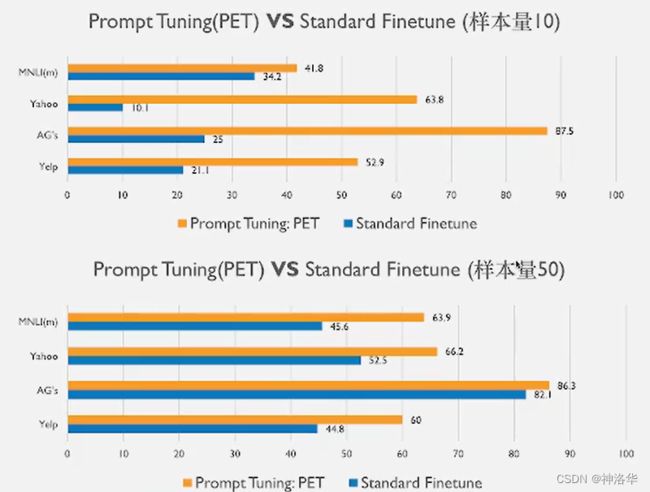
可见尤其在小样本数据集上,PET方法表现明显更好。
3. PET优缺点
-
优点:
- 使用人工模板给模型明确提示,释放预训练模型知识潜力
- 不引入随机初始化参数,避免过拟合(应该是不用额外的分类层)
-
局限性:
- 稳定性差:使用不同模板最终模型精度差很多,比如下面的例子,准确率相差近20%。
- 模板表示无法全局优化

2.3.3 P-Tuning:连续空间可学习模板
论文《GPT Understands, Too》
(2021.5.18)
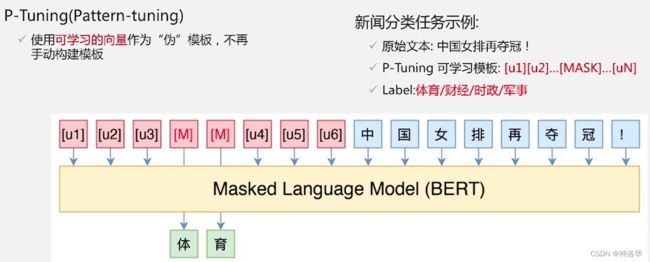
1. 核心思想
针对PET方法中模板需要手工设计,精度不稳定且模板无法优化的问题, P-Tuning提出了可学习的伪模板。例如下图例子中的可学习模板——[u1][u2]...[MASK]...[uN]。
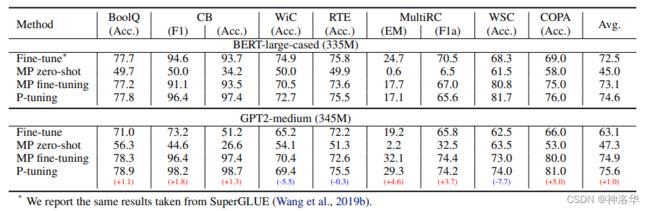
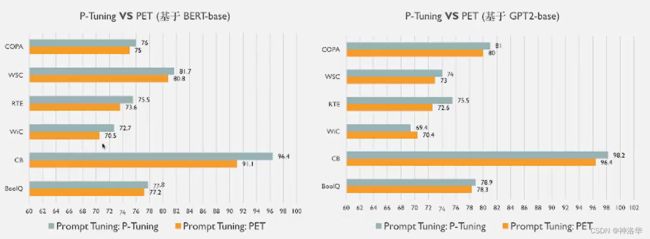
2. 模型效果:普遍由于PET
下面是BER-large-cased和GPT2-medium两个模型在各种NLP任务上,微调、PET、PET微调和 P-Tuning的效果对比:
画出一部分就是:
3. P-Tuning优缺点
- 优点:
- 使用了可学习模板参数,让模型可以在全局角度进行优化,以学到更好的模板表示
- 缓解人工模板的带来的不稳定性
- 局限性:
- 超多分类任务场景时(比如200类),预测难度大
- 蕴含等任务,不适合用基于模板的方式解决,其构造的模板不符合自然语言习惯。
蕴含任务:判断下面两句话的逻辑关系。

构造模板之后就是:

2.3.4 EFL:将所有任务都转为蕴含任务
论文《Entailment as Few-Shot Learner》
(2021.4.29)
1. 核心思想
EFL(Entailment as Few-Shot Learner):所有目标任务转化为2分类蕴含任务(Yes/No),不仅可以处理更多的任务,而且二分类问题大大简化了模型预测的难度。示例如下:
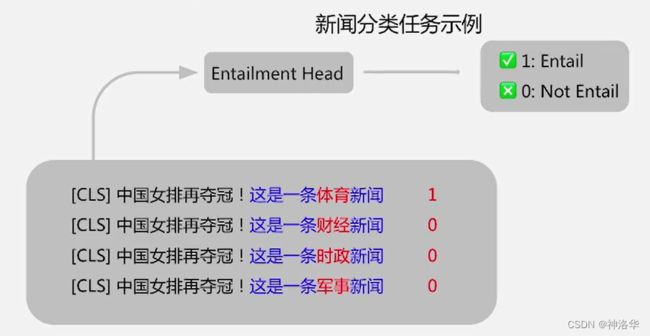
由于这条新闻是体育新闻,所以只有第一句话标签应该是1,其它都是0。也就是模型只需要判断每句话的逻辑关系是对的还是错的。
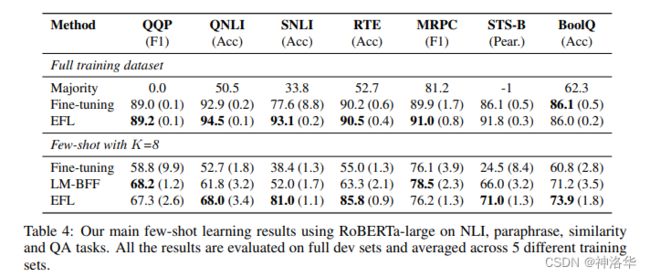
2. 模型效果
下面是RoBERTa-large模型在7个任务上使用Fine-tuning、PET(LM-BFF )和EFL方法的效果对比:
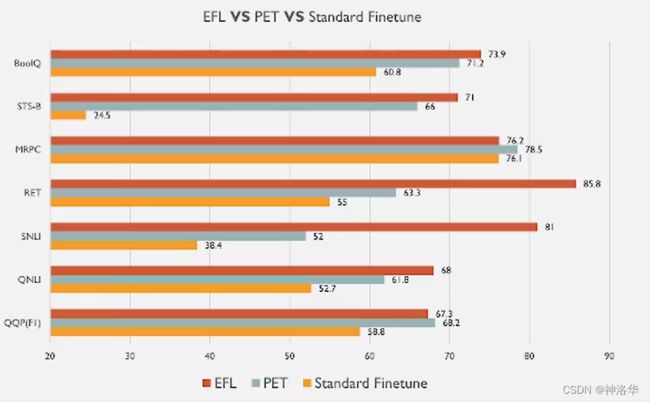
画出下部分就是:
3. EFT优缺点
- 优点:
- 统一视角:所有任务简化为2分类
- 缩小预测空间,降低预测难度
- 局限性:
- 增加模型在预测期间的复杂度。之前的算法每条数据预测一次就行,用了EFL就需要重复预测多次。
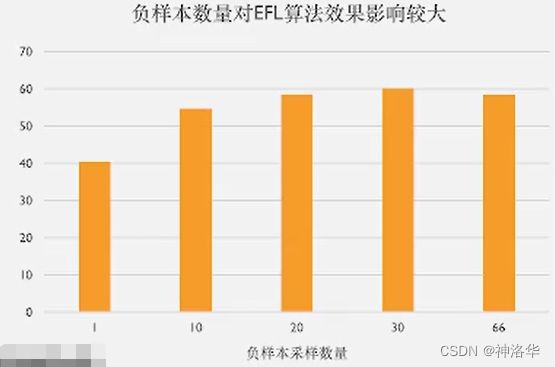
- 负样本数量很重要。
比如下面对比一个论文分类任务进行试验(共67类),一条数据就可以构造一个正样本,66个负样本。随着每条数据采集负样本的数量提升,模型准确率也逐步上升,到30左右饱和。一般负样本采样数为类别的一半效果比较好。
2.4 R-Drop策略:显著提升模型效果(附代码示例)
- 论文:《R-Drop: Regularized Dropout for Neural Networks》(NeurIPS 2021 ),代码
- 论文笔记《R-Drop:提升有监督任务性能最简单的方法》
2.4.1 R-Drop算法原理
SimCSE(EMNLP 2021.4)通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA,微软在六月底发布的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop(Regularized Dropout),它将“Dropout两次”的思想用到了有监督任务中,在神经机器翻译、摘要生成、语言理解、和图像分类等多个任务中被广泛证明有效,是一种通用的优化策略。
R-Drop算法核心思想:通过drop两次这种隐式的数据增强,引入KL距离约束来提升模型效果(KL散度就是衡量两个分布之间的差异,在这里是减少了模型参数的自由度)
为了避免模型过拟合,我们通常使用诸如 Dropout 等较为成熟的正则化策略,而本文作者是将模型进行两次Dropout。具体来说,将同一个模型,同样的输入,进行两次Dropout 前向传播。由于Dropout的存在,同一个输入x会得到两个不同的输出特征,相当于进行了一次隐式的数据增强,效果一般是要更好的。
同时我们得到两个不同但差异很小的概率分布 P 1 ( y ∣ x ) P_{1}(y|x) P1(y∣x)和 P 2 ( y ∣ x ) P_{2}(y|x) P2(y∣x),并在这两个分布之间加了一个约束 D K L ( P 1 ∣ ∣ P 2 ) D_{KL}(P_{1}||P_{2} ) DKL(P1∣∣P2),使得这两个分布要尽可能的相似。通过在原来的交叉熵损失中加入这两个分布的KL散度损失,来共同进行反向传播,然后更新参数。(下面这张图右侧表示模型经过两次dropout之后相当于得到了两个网络)
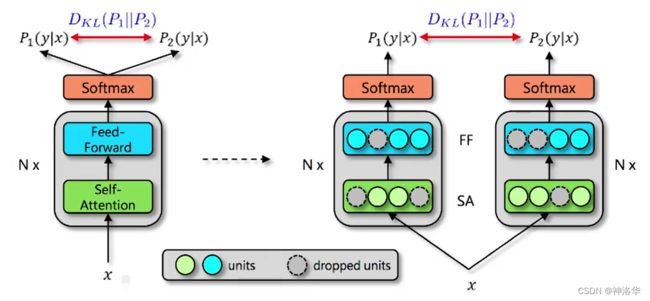
2.4.2 训练过程
模型的训练目标包含两个部分,一个是两次输出之间的KL散度,如下:
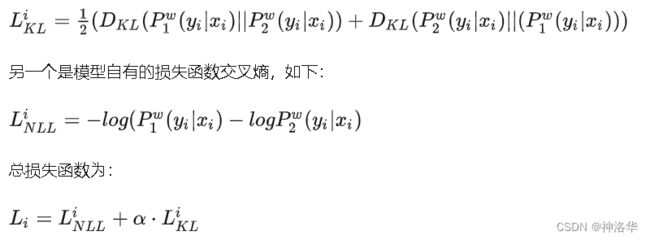
在训练过程中,为了节省训练时间,并不是将同一个输入输入两次,而是将输入句子复制一遍,然后拼接到一起,即 [ x , x ‘ ] [x,x`] [x,x‘] ,这样就相当于将batch size扩大了一倍,这个可以节省大量的训练时间,当然相比于原始的模型,这个会使得每个step的训练时间增加了,因为模型的训练复杂度提高了,所以需要更多的时间去收敛。训练如下:

2.4.3 R-Drop策略效果
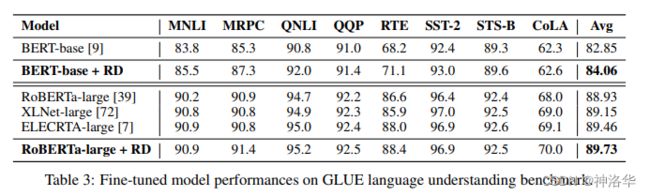
1. 在GLUE稳定涨点
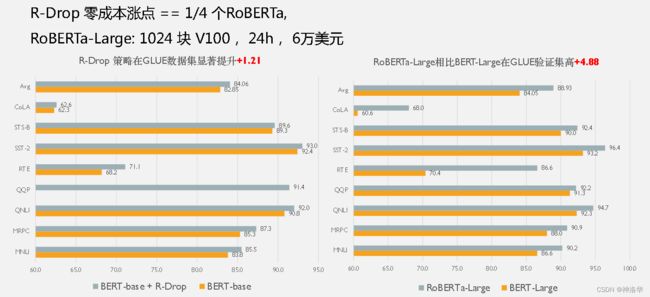
下面是BERT-base和RoBERTa-Large使用R-Drop策略后的效果对比,第一行是平均结果,可见使用这个策略后模型精度明显提升(如果是RoBERTa-Large从头预训练一次,大概要花6万美元)。
可视化:
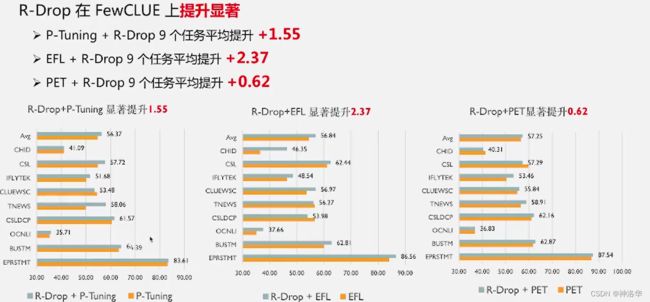
2. Few-CLUE上明显涨点
另外,在P-Tuning、EFL、PET三种小样本算法基础上加入R-Drop策略,Few-CLUE(中文小样本权威评测基准)精度明显提升。。
2.4.4 RDrop 代码使用示例
RDropLoss API
下面代码来自示例PaddleNLP/examples/few_shot/pet/pet.py,只需要加入三行代码就可以使用Rdrop:
mlm_loss_fn = ErnieMLMCriterion()
rdrop_loss = ppnlp.losses.RDropLoss() # 第一行导入
for epoch in range(1, args.epochs + 1):
model.train()
for step, batch in enumerate(train_data_loader, start=1):
......
prediction_scores = model(input_ids=src_ids,token_type_ids=token_type_ids,masked_positions=new_masked_positions)
......
if args.rdrop_coef > 0:
# 第二行,让模型进行第二次dropout得到另一个输出
prediction_scores_2 = model(input_ids=src_ids,token_type_ids=token_type_ids,
masked_positions=new_masked_positions)
ce_loss = (mlm_loss_fn(prediction_scores, masked_lm_labels) +
mlm_loss_fn(prediction_scores_2, masked_lm_labels)) * 0.5
# 第三、四行,计算两次结果的rdrop_loss,将这个loss加到总的损失中。
kl_loss = rdrop_loss(prediction_scores, prediction_scores_2)
loss = ce_loss + kl_loss * args.rdrop_coef
2.4.5 总结
本质上来说,R-Drop与MixUp、Manifold-MixUp和Adversarial Training(对抗训练)一样,都是一种数据增强方法,这种方法可以套用到任何有监督/半监督的训练中,通用且实践意义很强,尤其在小样本学习场景中用的非常多。
另外,当R-Drop应用于微调大规模预训练模型(例如ViT、RoBERTa大型和BART)时,产生了显著的改进甚至超过了设计Transformer 的高级变体。
下面是一个电商平台评论的情感分类任务EPRSTMT,只有2个类别,每类16个样本 ,一共32个。在百度的ERNIE-1.0模型上使用各种范式的精度对比(Standard Finetune是标准的预训练+微调范式):
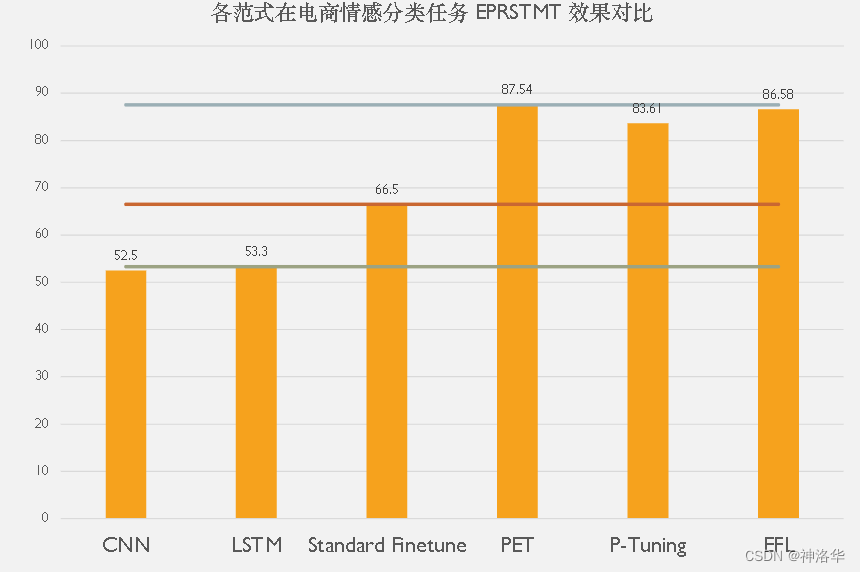
基于PaddleNLP Few-Shot可以轻松参加FewCLUE并获得好成绩。
- PaddleNLP内置FewCLUE竞赛9个数据集
- 内置预训练时代微调新范式的3大典型算法
- 打通了FewCLUE竞赛训练、评估、预测全流程
- 之前有开发者基于PaddleNLPFew-Shot策略库参与FewCLUE竞赛获得复赛第4
2.4.6 总结
PromptTuning新范式与StandardFine-tune范式通用技术结合有巨大潜力,比如数据增强(R-Drop)、知识蒸馏、
三、FasterTransformer:针对Transformer的高性能加速
- PaddleNLP:FastGeneration 预测、《FastGeneration》、FasterTransformer API说明、《文本生成高性能加速教程》、 FasterTransformer完整源代码
- NVIDIA:FasterTransformer项目地址、视频《Faster Transformer介绍》
- 原始Transformer代码可参考我之前帖子《Transformer代码解读(Pytorch)》
3.1 Transformer性能瓶颈
Transformer计算量主要在paddle.nn.MultiHeadAttention部分的自注意力计算上。
- query、key、value
- 计算weights=softmax(query* key/sqrt(dmodel))
- 计算linear(weights* value)
以上计算需要20个算子,性能分析如下:
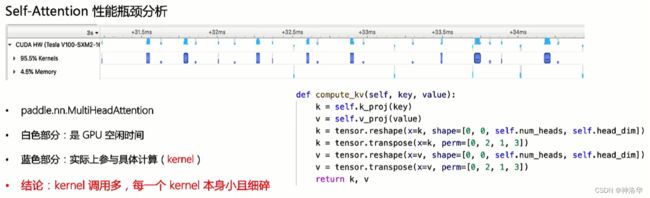
- 每个API在框架底层都会调用对应的算子,算子调用完成计算的对应的CUDA kernel(上图蓝色部分)。
- 上图可以看到,GPU大多时候是空闲的。这是因为每次具体计算前都有API→算子→kernel的过程,而这个过程是在CPU上完成的,也就是上图白色空闲部分。
- 上图代码中,除了实际参与计算的线性层部分(Q、K、V相关计算),还有一些必不可少的reshape操作等,统称为功能性计算。
由此可见,原生的self-attention实现,kernel计算粒度很细,而且还会引入一些功能性算子,导致整个计算模块中对kernel调用次数很多,所以需要优化(融合kernel,减少算子调用次数,减少GPU空闲时间)。
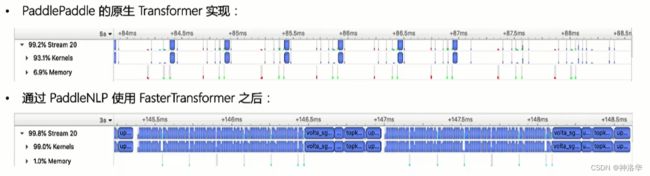
下面先放出FasterTransformer优化后,和Transformer的Nsight profiler对比图,可见优化后CUDA kernel执行粒度更紧密。
3.2 FasterTransformer整体结构
FasterTransformer(NVIDIA)算法结构和原版Transformer基本一致,但是从模型框架角度对Transformer进行了加速,主要方法有:
- 半精度优化:使用f精度p16和int8加快推理预测,且节省显存。
- 算子融合。对除矩阵乘法外的所有算子,都尽量进行了合并,减少了GPU kernel调度和显存读写。
- decoing:融合decoder、embedding,position encodiing和beams search/sampling解码策略。
- GELU激活函数、层正则化、softmax等高频调用操作的优化
下图Faster Transformer结构中:
encoder:下图左侧部分,由self attention+FFNN层组成decoder:右侧黄色部分,由self attention+encoder-decoder-cross attention+FFNN三部分组成decoding:右侧整个蓝色部分是Faster Transformer中提出的decoding结构,包括embedding层、position encoding、decoder、log probability(计算logist概率分布)、解码策略层(Beam Search等)。
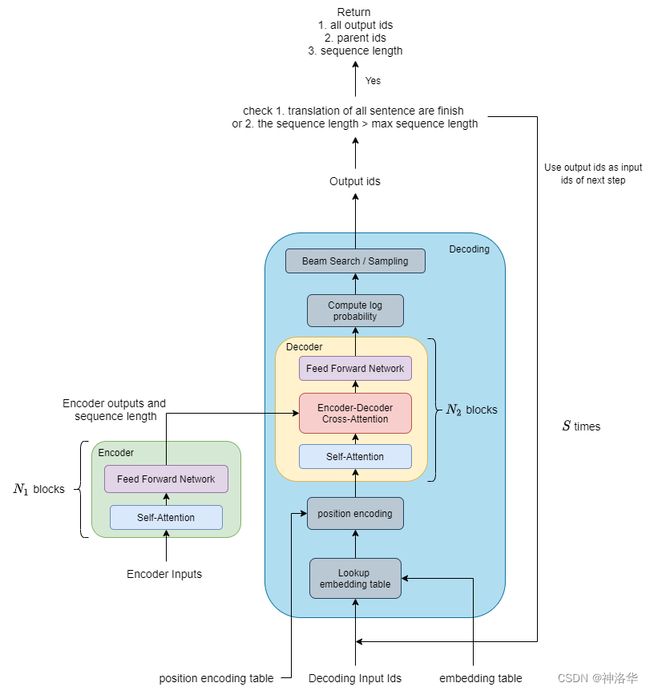
encoder-decoding
3.3 优化策略:融合kernel
3.3.1 encoder融合
GEMM(GeneralMatrixMultiplication):经过cuBLAS高度优化的一个用于矩阵乘的kernel,无需再做优化。剩下的就是对 除去GEMM的部分做最大限度的融合。FasterTransformer就是将两个GEMM之间的计算尽可能的融合成一个kernel。下面是FasterTransformer的encoder(虚线框部分)计算示意图,其中每个蓝色方块都是一个GEMM kernel。
- 第一层:GEMM矩阵乘法层。本来应该是将输入矩阵分别经过三个权重矩阵将其转换为Q、K、V(线性层实现),但是实际中是将三个权重矩阵拼在一起,得到拼在一起的QKV矩阵,所以只需经过一次乘法就能完成计算。
- 第二层:三和蓝色的bias模块,表示添加QKV偏置的三种算法
- 结论:
FasterTransformer encoder有6个(或8个,因为有三种bias kernel)GEMM kernel和6个自定义CUDA kernel,总共12个。而PaddlePaddle实现原生的paddle.nn.TransformerEncoderLayer需要调用38个算子,是做encoder融合之后的三倍。融合之后的encoder层,在某些配置下计算性能提升超过100%。
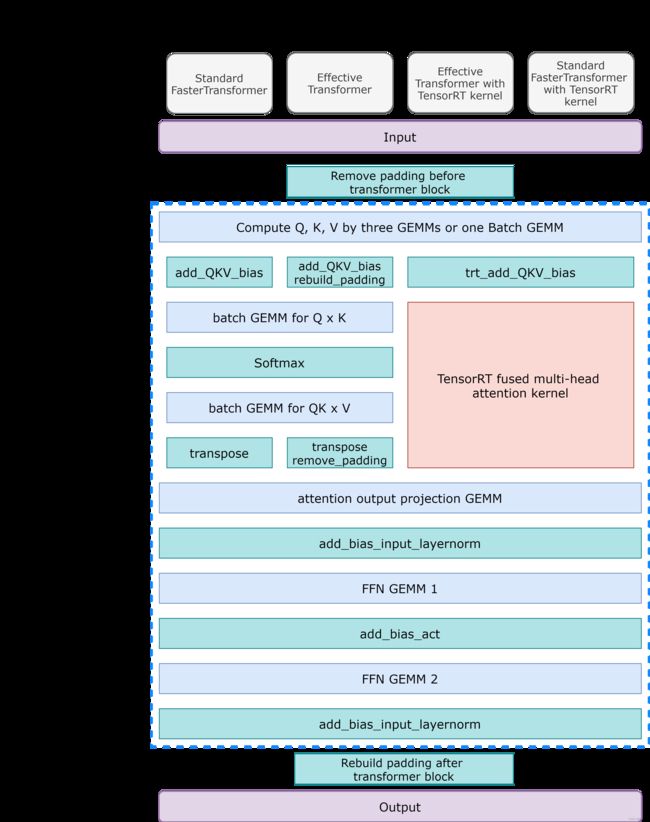
encoder_flowchart
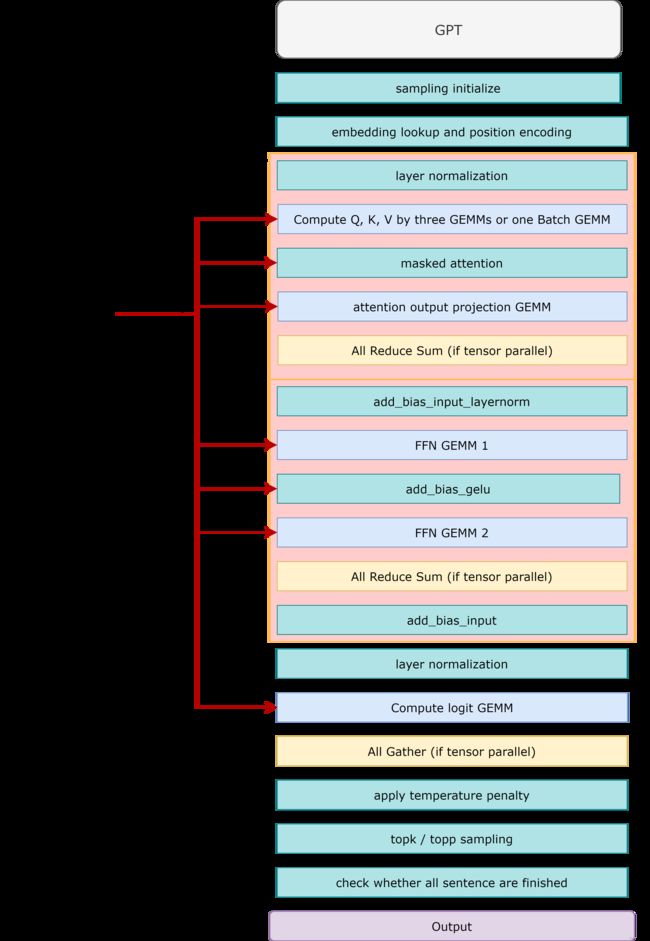
3.3.2 decoder融合
decoder比encoder多了一个encoder-decoder-cross-attention层,其它结构都一样,所以优化策略也一样,都是讲GEMM之外的kernel尽可能的融合。这里以GPT举例,图中虚线框就是decoder部分:
- kernel融合
FasterTransformer decoder共有6个(或8个)GEMM kernel和7个自定义CUDA kernel,总共13个。而原生实现EncoderLayer需要38个算子,所以 融合后的decoder性能也提升了100%以上。
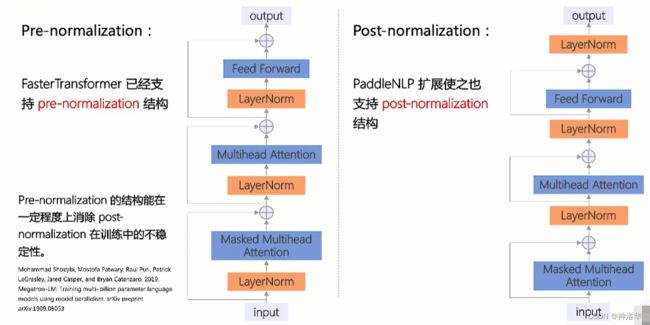
- Pre-normalization&Post-normalization:FasterTransformer已经支持
pre-normalization,PaddleNLP扩展使之同样支持post-normalization。在transformer系列模型里面,这两种结构都能看到。
3.3.3 decoding 融合
3.3.3.1 解码策略(Greedy Search、Beam Search、T2T Beam Search)
1. 解码过程
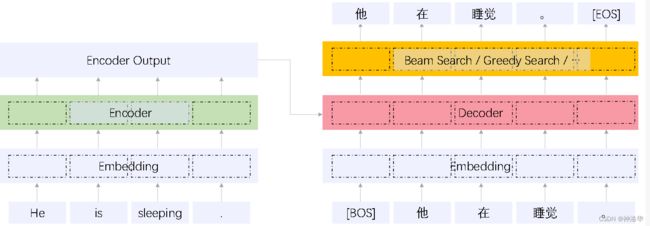
decoing模块基于log probability层输出一个概率分布,然后使用解码策略输出最后的结果。下面详细介绍一下解码过程
下图中,解码时以[BOS]标识符作为解码的开始。[BOS]在第一个self attention层的输出,加上encoder模块最后层的输出,一起输入encoder-decoder-cross-attention层(图中粉红色)计算自注意力做交互,然后经过FFNN层,最后得到一个softmax之后的输出概率,这个概率代表输出词表的概率分布情况。而解码策略,就是基于这个词表的概率分布,选择合适的单词作为输出。这个输出加入到下一个时间步的输入中,循环此过程,直至解码出[EOS],表示句子解码完成。
所以解码是一个循环过程,每次带入之前的解码输出结果,完成当前步的解码预测。而解码策略通过所有词的预测概率分布,选择最终的输出结果。
2. 解码策略
- 贪婪解码/搜索(
Greedy decoding/search):- 模型每次都选择概率最大的词作为输出,即每个时间步只产生一个输出,期望用局部最优找到全局最优。
- 缺点是解码路径/结果是固定的,同样的输入只会得到同样的解码结果,在有的任务中生成不够多样化(比如对话系统)
- 集束搜索(
Beam Search):每个时间步保留beam_size(束宽)个最高概率的输出词,然后在下一个时间步,重复执行这个过程。最终,返回top_beams个候选结果,并从中选择最优的输出结果。- beam_size=1就是贪婪搜索
- 以上两种策略解码停止条件是:输出[EOS]或达到指定的最大输出长度
- Beam Search比Greedy Search有更大的搜索空间,虽然不一定能找到全局最优的结果,但可以找到一个相对更优的结果,一般相比Greedy Search更好。
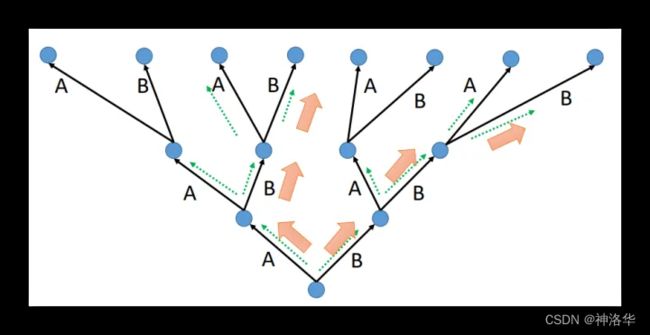
从下往上,每个时间步生成两个最大概率的结果(均以A、B表示)继续传播
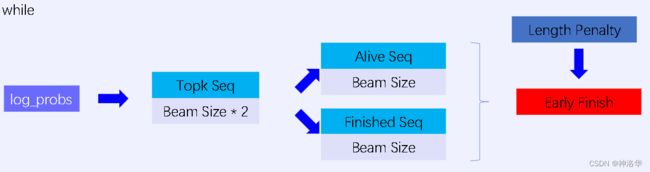
T2T Beam Search:提出了Alive Seq和Finished Seq的概念。假设beam_size=2- 每个时间步得到输出概率log_peobs之后,保留beam_size*2的结果作为
Topk Seq。 - 将Topk Seq分为
Alive Seq和Finished Seq两个候选序列,大小都为beam_size;并保证Alive Seq中没有终止符[EOS],可以继续生成。 - 结合Length Penalty判断
Alive Seq中最高得分的结果分支,是否已经低于Finished Seq中的结果分支。如果是,则提前结束循环(Early Finish),否则Alive Seq会代入到下一步的循环迭代中。
- 每个时间步得到输出概率log_peobs之后,保留beam_size*2的结果作为
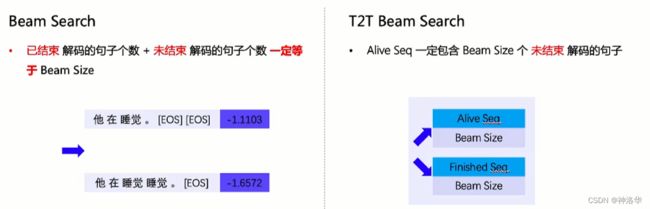
对比Beam Search和T2T Beam Search:
Beam Search:每当某个分支生成终止符[EOS],则解码的分支会少一个,所以每个时间步生成的结果可能小于beam_sizeT2T Beam Search:Alive Seq中是不包含终止符的,所以每个时间步都生成beam_size个结果,其搜索空间更大,在一些任务中会有更好的效果。
3.3.3.2 decoding优化
在实际测试transformer过程中,会发现encoder时间占比约10%,而decoding时间占比约90%,比encoder多得多,所以需要进一步优化。
- CUDA kernel融合
- 之前是单次迭代,即每次迭代完就结束当前算子,然后重新调用一次算子。
- decoding将整个循环解码融融合成一个算子,大大提高了模型的性能(在一个算子中用for循环完成整个迭代过程)。
- 解码策略优化
- paddleNLP支持多种解码策略,比如Beam search、T2T beam search、Sampling(引入多样性变化,多在对话任务中使用)
除了融合kernel之外,Faster Transformer还做了一些其它的性能优化。
3.4 优化策略总结
Faster Transformer优化总结:
- 融合kernel:上面已经讲过了针对encoder、decoder、decoding的kernel融合优化;
- 半精度优化:使用精度p16和int8加快推理预测,节省显存,且针对float32和float16,设置不同的grid/block数目等参数以实现在不同精度情况下GPU最佳的配置
- 更快的CUDA API:例如使用
__expf替换expf(前者是后者的数学近似),损失很小的精度但是有更快的速度(经过测试不影响一些机器翻译和对话的结果); - Decoding通用性:支持多种解码策略,以适应不同的场景
3.5 Faster Transformer的使用和总结
- FasterTransformer API:
classFasterTransformer(src_vocab_size, trg_vocab_size, max_length, num_encoder_layers,
num_decoder_layers, n_head, d_model, d_inner_hid, dropout,
weight_sharing,attn_dropout=None, act_dropout=None, bos_id=0,
eos_id=1, pad_id=None, decoding_strategy='beam_search', beam_size=4,
topk=1, topp=0.0, max_out_len=256, diversity_rate=0.0,
decoding_lib=None,use_fp16_decoding=False,alpha=0.6
enable_faster_encoder=False, use_fp16_encoder=False, rel_len=False)
定义好一些超参数,就可以得到FasterTransformer的一个实例模型。其中decoding_strategy参数是字符串格式,可以是beam_search、beam_search_v2(也就是T2T beam search)、topk_sampling和topp_sampling。
Just InTime自动编译:FasterTransformer本身是基于C++和CUDA C实现,在实例化时会检测对应的路径下是否有对应的动态库,如果没有的话,会进行自动编译(自动编译FasterTransformer、PaddlePaddle自定义op、载入编译的动态库)。下面是编译的部分截图:

- 加速效果测试
下面是使用Transformer bsased model,beam search解码策略,然后在V100 GPU上进行英德机器翻译任务的测试(PaddlePaddle2.1.2),可见随着batch_size的增大,GEMM矩阵乘法的时间占比也增大,加速比在减少。但即使是batch_size=64,使用fp32也有近10倍的加速。
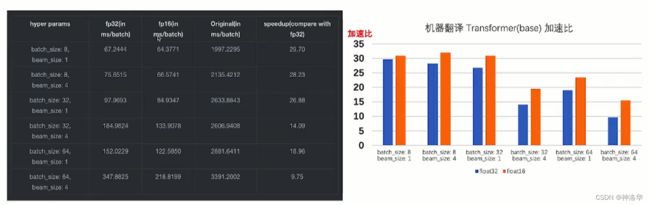
第二、三列是分别使用fp32和fp16时
FasterTransformer的性能(ms/batch),第四列是原生实现的transformer。
- 总结
PaddleNLP通过PaddlePaddle自定义op(算子)的形式接入了FasterTransformer,并支持多种transformer模型,用于各种NLP任务,详见《文本生成高性能加速》。

PaddleNLP用法:
