spring史上最全笔记
Spring笔记
目录
概念:
优点
IOC 控制反转
控制什么?
谁来控制?
反转?
依赖注入DI?
IOC和DI关系
IOC本质
★获取IOC容器
★bean的三种创建实例的方式
FactoryBean
★获取IOC容器中的bean的三种方式:
2、根据bean的类型获取对象 常用 getBean(Student.class);
3、根据bean的id和类型获取对象 getBean("student", Student.class)
★DI:依赖注入
Set依赖注入
构造器依赖注入
p命名空间
bean的作用域
饿汉懒汉单例
Bean生命周期:
基于xml的自动装配
★基于注解管理bean
实验一:标记与扫描
①注解
②扫描
③新建Maven Module
★④标识组件的常用注解
⑥创建组件
★⑤扫描组件
⑥测试
⑦组件所对应的bean的id
★实验二:基于注解的自动装配
①场景模拟
②@Autowired注解
③@Autowired注解其他细节
AOP概念及相关术语
概述
作用
AOP主要干什么:抽和套
相关术语
①横切关注点
②通知
③切面
④目标对象
⑤代理对象
⑥连接点
⑦切入点
基于注解的AOP
基于注解AOP的实现
动态代理:
在Spring的配置文件中配置:
各种通知
切入点表达式:
获取连接点信息
切面的优先级
基于xml的实现Aop(了解)
声明式事物
JdbcTemplate
简介
准备工作
测试
声明式事务概念
Spring事物:
事物的传播特性:
编程式事务
声明式事务
基于注解的声明式事务
测试无事务情况
声明式事物的配置步骤:
加入事务
@Transactional注解标识的位置
事务属性:只读
事务属性:超时
事务属性:回滚策略
事务属性:事务隔离级别
事务属性:事务传播行为
基于xml声明式事务(了解)
接下来三个月所学
框架:spring;springmvc;mybatisplus(orm)实体类和数据库映射;这三个简称SSM
springboot;
数据库:redis(非关系型数据库)
概念:
Spring是一款轻量级框架,
核心:IOC 和 AOP 它能够集成其他优秀框架,比如mybtayis,springmvc等。
IOC:控制反转,把以前手动创建的对象交给spring创建对象
DI:依赖注入,事IOC的另外一种说法,常用的注入方式有set注入和构造器注入
Spring:春天------>给软件行业带来了春天!
2002,首次推出了Spring框架的雏形:interface21框架!
Spring框架即以interface21框架为基础,经过重新设计,并不断丰富其内涵,于2004年3月24日发布了1.0正式版。
Spring理念:使现有的技术更加容易使用,本身是一个大杂烩,整合了现有的技术框架!
SSH:Struct2 + Spring + Hibernate!
SSM:SpringMVC + Spring + Mybatis!
优点
- Spring是一个开源的免费的框架(容器)!
- Spring是一个轻量级的、非入侵式的框架!
- 控制反转(IOC),面向切面编程(AOP)!
- 支持事务的处理,对框架整合的支持!
IOC 控制反转
总结:IOC是一个容器管理bean的,IOC就是将对象由Spring去创建,管理,装配!
bean:配置一个bean对象,将对象交给IOC容器管理
控制什么?
控制创建对象的方式;
谁来控制?
原本应用程序的对象是通过程序本身控制创建,
加入Spring后,对象由Spring来创建;
反转?
程序本身不再创建对象了,而是被动接收Spring创建的对象;
依赖注入DI?
就是利用set方法进行注入;
IOC和DI关系
DI(依赖注入)是实现IOC(控制反转)这个编程思想的一种方式;
IOC本质
- IOC控制反转 inversion of control
- IOC是一种编程思想,由主动编程变成被动的接收对象
- 通过 new ClassPathXMLApplicationContext去浏览底层代码
- IOC是Spring框架的核心内容
- IOC是一种通过描述(XML或注解)并通过第三方去生产或获取特定对象的方式。
★获取IOC容器
ApplicationContext:上下文 ClassPathXmlApplicationContext:读取配置来用的
ApplicationContext ioc = new ClassPathXmlApplicationContext("applicationContext.xml");
★bean的三种创建实例的方式

FactoryBean
/*
* FactoryBean是一个接口,需要创建一个实现类实现该接口
* 其中有三个方法
* getObject():通过一个对象交给IOC容器管理
* getObjectType():设置所提供对象的类型
* isSingleton():所提供的对象是否单例,默认true:单例 false:多例
* 当把FactoryBean的实现类配置bean时,会将当前类中getObject()所返回的对象交给IOC容器管理
* */
public class UserFactoryBean implements FactoryBean {
@Override
public Users getObject() throws Exception {
return new Users();
}
@Override
public Class getObjectType() {
return Users.class;
}
@Override
public boolean isSingleton() {
return true;
}
}
//配置bean
//bean拿到的是getObject()方法里面的对象
★获取IOC容器中的bean的三种方式:
getBean():获取类对象的
bean是一个组件,class参数是组件对象
bean:配置一个bean对象,将对象交给IOC容器管理
属性:
id:bean的唯一标识,不能重复
class:设置bean对象所对应的类型
这是.xml配置文件中的bean组件
通过反射创建对象的com.springYKA.entity.Student(包+类名=全类名)
- 根据bean的id获取对象 getBean("student")
Student student1 = (Student) ioc.getBean("student");
2、根据bean的类型获取对象 常用 getBean(Student.class);
Student student2 = ioc.getBean(Student.class);
* 注意:根据类型获取bean时,要求IOC容器中有且只要一个类型匹配bean
若同一个类型匹配多个bean,以下代码此时抛出异常:NoUniqueBeanDefinitionException
若没有任何一个类型匹配的bean,以下此时抛出异常:NoSuchBeanDefinitionException
空的
3、根据bean的id和类型获取对象 getBean("student", Student.class)
Student student3 = ioc.getBean("student", Student.class);
* 结论:
* 根据类型来获取bean时,在满足bean唯一性的前提下
* 其次只是看:【对象 instanceof 指定的类型】的返回结果
* 只要返回的时true就可以认定为和类型匹配 能够获取到
* 即通过备案的类型,bean所继承的类的类型,bean所实现的接口类型都可以获取bean
* People people = ioc.getBean(People.class);这是个接口,通过接口去获取Student对象
★DI:依赖注入
Set依赖注入
bean是一个组件,class参数是组件对象
property标签:bean的属性标签 通过组件类的setXxx()方法给组件对象设置属性
name属性:设置需要赋值的属性名;指定属性名(这个属性是getXxx()、setXxx()方法定义的,和成员变量无关)
value属性:指定属性值,设置为属性所赋的值
字面量类型:用value给属性赋值
private String name;
private Integer age;
private String sex;类类型:
private Class clazz;为类类型的属性赋值 类类型的用ref获取
ref:引用IOC容器中某个bean的id 引用外部bean的id 关联某个类的,指向关联类的id
设置时间类型
正确设置时间date类型
private Class clazz;
两种常用方式:
1、引用外部bean的id 通过ref:引用IOC容器中某个bean的id
2、内部bean:只能在当前bean内部使用,不能直接通过IOC容器获取
抽烟
喝酒
烫头
米饭
面条
馒头
香蕉
苹果
草莓
内部
集合属性赋值
private List list;
private Set set;
private Map map;
外部集合类型的bean
1
2
3
n01
//类类型引用方式
n02
//两种写法
构造器依赖注入

1
2
3
11
22
33
44
55
66
p命名空间
引入p命名空间后,可以通过以下方式为bean的各个属性赋值
bean的作用域
Springbean的作用域:单例,原型,session,request global session后面三个为服务器作用域
单例模式是指spring在创建实例化对象的时候,所有的对象都指向一个实例。有懒汉饿汉之分 地址一样
多例:bean在ioc容器中可以有多个实例,地址不一样
在Spring中可以通过配置bean标签的scope属性来指定bean的作用域范围,各取值含义参加下表:
| 取值 |
含义 |
创建对象的时机 |
| singleton(默认) |
在IOC容器中,这个bean的对象始终为单实例 |
IOC容器初始化时 |
| prototype |
这个bean在IOC容器中有多个实例 |
获取bean时 |
如果是在WebApplicationContext环境下还会有另外两个作用域(但不常用):
| 取值 |
含义 |
| request |
在一个请求范围内有效 |
| session |
在一个会话范围内有效 |

饿汉懒汉单例
//饿汉单例
public class HungryBones {
private static HungryBones hungryBones = new HungryBones();
private HungryBones() {
}
public static HungryBones getInstance(){
return hungryBones;
}
}
//懒汉单例
public class Lazybones {
private static Lazybones lazybones = null;
private Lazybones() {
}
public static Lazybones getInstance(){
if(lazybones == null){
lazybones = new Lazybones();
}
return lazybones;
}
}测试:
public static void main(String[] args) {
//懒汉测试
Lazybones instance = Lazybones.getInstance();
Lazybones instance2 = Lazybones.getInstance();
System.out.println(instance);
System.out.println(instance2);
//饿汉测试
HungryBones instance3 = HungryBones.getInstance();
HungryBones instance4 = HungryBones.getInstance();
System.out.println(instance3);
System.out.println(instance4);
}Bean生命周期:
* 生命正确步骤:
* 1、实例化(无参构造器)
* 2、依赖注入
* 3、后置处理器postProcessBeforeInitialization方法
* 4、初始化,需要通过bean的init-method属性指定初始化的方法
* 5、后置处理器postProcessAfterInitialization方法
* 6、IOC容器关闭时摧毁,需要通过bean的destroy-method属性指定销毁的方法
*
* bean的后置处理器会在生命周期的初始化前后添加额外的操作,
* 需要实现BeanPostProcessor接口,且配置到IOC容器中,
* 需要注意的是,bean后置处理器不是单独针对某一个bean生效,而是针对IOC容器中所有bean都会执行
*
* 注意:
* 若bean的作用域为单例时,生命周期的前三个步骤会在获取IOC容器时执行
* 若bean的作用域为多例时,生命周期的前三个步骤会在获取bean时执行,销毁不执行配置bean
//后置处理器
//后置处理器
public class MyBeanProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName)
throws BeansException {
System.out.println("☆☆☆" + beanName + " = " + bean);
System.out.println("后置处理器postProcessBeforeInitialization 初始化之前");
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName)
throws BeansException {
System.out.println("★★★" + beanName + " = " + bean);
System.out.println("后置处理器postProcessAfterInitialization 初始化之后");
return bean;
}
}测试
//ConfigurableApplicationContext是ApplicationContext的接口,其中扩展了刷新和关闭容器的方法
ConfigurableApplicationContext ac =new ClassPathXmlApplicationContext("spring-lifecycle.xml");获取IOC容器
Users bean = ac.getBean(Users.class);//获取bean
ac.close();//关闭IOC容器基于xml的自动装配
为类类型和接口的属性自动赋值
*自动装配:
* 根据指定的策略,在IOC容器中匹配某个bean,
自动为bean中的类类型的属性或接口的属性赋值,与字面量无关
*可以通过bean标签中的autowire属性设置自动装配的策略
* 自动装配策略:
* 1、no,default;表示不装配,即bean中的属性不会自动匹配某个bean为属性赋值,此时属性使用默认值
* 2、byType:根据要赋值的属性的类型,在IOC容器中匹配某个bean,为属性赋值
* 注意:
* A:若通过类型没有找到任何一个类型匹配的bean,此时不装配,属性使用默认值
* B:若通过类型找到了多个类型匹配的bean,此时会抛出异常:NoUniqueBeanDefinitionException
* 总结:当使用byType实现自动装配时,IOC容器中有且只能有一个类型匹配的bean能够为属性赋值
* 3、byName:将要赋值的属性的属性名作为bean的idIOC容器中匹配某个bean,为属性赋值 属性名和bean的id名达成一致才能赋值
* 总结:当类型匹配的bean有多个时,此时可以使用buName实现自动装配
★基于注解管理bean
实验一:标记与扫描
①注解
和 XML 配置文件一样,注解本身并不能执行,注解本身仅仅只是做一个标记,具体的功能是框架检测
到注解标记的位置,然后针对这个位置按照注解标记的功能来执行具体操作。
本质上:所有一切的操作都是Java代码来完成的,XML和注解只是告诉框架中的Java代码如何执行。
②扫描
Spring 为了知道程序员在哪些地方标记了什么注解,
就需要通过扫描的方式,来进行检测。然后根据注解进行后续操作。
③新建Maven Module

★④标识组件的常用注解
* @Component:将类标识为 普通 组件(bean)
* @Controller:将类标识为 控制层 组件(bean)
* @Service:将类标识为 业务层 组件(bean)
* @Repository:将类标识为 持久层 组件(bean)
@Configuration:注解配置,相当于把当前类生成一个XML配置文件
@Bean:一般作用在返回值是类的方法上,相当于是xml文件中的bean标签四个注解的区别
通过查看源码我们得知,@Controller、@Service、@Repository这三个注解只是在@Component注解的基础上起了三个新的名字。
对于Spring使用IOC容器管理这些组件来说没有区别。所以@Controller、@Service、@Repository这三个注解只是给开发人员看的,让我们能够便于分辨组件的作用。
注意:虽然它们本质上一样,但是为了代码的可读性,为了程序结构严谨我们肯定不能随便胡乱标记。
⑥创建组件
创建控制层组件
@Controller
public class UserController {
}创建接口UserService
public interface UserService {
}创建业务层组件UserServiceImpl
@Service
public class UserServiceImpl implements UserService {
}创建接口UserDao
public interface UserDao {
}创建持久层组件UserDaoImpl
@Repository
public class UserDaoImpl implements UserDao {
}★⑤扫描组件
情况一:最基本的扫描方式
情况二:指定要排除的组件
AOP只要干什么:抽和套,抽横切关注点封装到切面中他就是一个通知,在通过切入点定位在连接点
基于注解的AOP
基于注解AOP的实现
- 将目标对象和切面交给IOC容器管理(注解+扫描)
2、将切面类通过注解@Aspect标识为一个切面
3、开启AspectJ的自动代理,为目标对象自动生成代理,
通过注解(@Before)找到的代理类
在spring的配置文件设置
动态代理:
- ★jdk动态代理:要求必须有接口,最终生成的代理类和目标类实现相同的接口,
如果目标对象实现了接口则默认使用jdk代理,如果没有则使用cglib代理
在com.sun.porxy包下,类名为$proxy2
JDK动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。现在都推荐面向接口编程,我们做的项目都是各种接口+实现类,所以是不是觉得这种代理方式和现在的接口编程很符合呢!
所以一个spring项目有接口和实现类,如果不在spring配置文件中特殊配置的话(就是默认配置),默认的动态代理方式就是JDK动态代理。但是,如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。
JDK动态代理举例:
目标类(实现类)可以认作为厨师张三,张三能够具体实现接口的所有功能,比如老板让张三做饭,当AOP代理的时候,会根据张三所实现的接口,再创造一个张三A(代理对象)作为张三的分身,这时候张三和张三A具有相同的接口(多态的体现),两者长得一模一样,这时候张三A就可以在张三做饭之前把菜给洗干净了,然后张三本人来做饭。。但是在老板(调用者)看来,自始至终都是张三(目标类)一个人在洗菜做饭。
但是张三(目标类)知道,在他动手做饭之前他的代理对象帮他做了一些事情,代理对象也可以在他做饭之后帮他洗碗等等。
所以目标类要是没有实现接口,程序就不能根据接口再实现一个代理对象,也就不能代替目标类(实现类)去做一些事情。
这种代理方式,只有在通过接口调用方法的时候才会有效!
注意如果目标类实现接口了,获取bean应该通过接口的方式获取
//因为目标对象实现了接口,所以用到的是jdk代理,即代理类也实现了相同的接口
//因为CalculatorImpl.class无法通过IOC容器获取目标对象
//所以Calculator.class,获取的是代理类
Calculator bean = aop.getBean(Calculator.class);
如果写出:
CalculatorImpl bean = aop.getBean(CalculatorImpl.class);
就必须在切面类中强转为cglib代理:@EnableAspectJAutoProxy//强制使用cglib- cglib动态代理:最终生成的代理类会继承目标类,并且和目标类在相同包下
CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
CGLIB代理举例:
我们把目标类比作李刚(化名),代理的时候,程序会根据制造一个子类来继承目标类,那么这个子类就是代理对象(李刚的儿子),所以李刚的儿子就可以能替他爸收钱(因为他爸是李刚哈哈),因为多态,所以程序识别不出来,然后目标类再替人办事,在外人看来,就是李刚在收钱办事。但是李刚有很多特权他儿子是没权限的,也就是目标类中有final方法,子类是无法继承的,那么这个代理对象就不能代理这部分功能。
3、AspectJ:本质上是静态代理,将代理逻辑“织入”被代理的目标类编译得到的字节码文件,所以最终效果是动态的。weaver就是织入器。Spring只是借用了AspectJ中的注解。

在Spring的配置文件中配置:
各种通知
在切面中,需要通过指定的注解将方法标识为通知方法
前置通知:使用@Before注解标识,在目标对象方法执行之前执行
后置通知:使用@After注解标识,在目标对象方法的finally字句中执行,前面报错也执行
返回通知:使用@AfterReturning注解标识,在目标对象方法返回值之后执行
/*
* 在返回通知中若要获取目标对象方法的返回值
* 只需要通过 @AfterReturning 注解的returning属性
* 就可以将 通知方法的某个参数 指定为 接收目标对象方法的返回值参数
* */
//公共切入点
*@Pointcut("execution(* com.YKA.spring.aop_annotation.CalculatorImpl.*(..))")
public void pointCut(){
}
@AfterReturning(value = "pointCut()" , returning = "result")
public void afterReturnAdvanceMethod(JoinPoint joinPoint , Object result){}异常通知:使用@AfterThrowing注解标识,在目标对象方法出现异常后执行
环绕通知:使用@Around注解标识,使用try...catch...finally结构围绕整个目标对象的目标方法
包括上面四种通知对应的所有位置,顶替上面四个通知,不会一块使用的
//环绕通知包括了前四种通知,不可能会一块使用的
@Around("pointCut()")
//环绕通知的方法一定要和目标对象方法的返回值一致
public Object aroundAdvanceMethod(ProceedingJoinPoint proceedingJinPoint){
Object result = null;
try {
System.out.println("环绕通知-->前置通知");
//表示目标对象方法的执行,执行目标对象方法
result = proceedingJinPoint.proceed();
System.out.println("环绕通知-->返回通知,返回值:"+result);
} catch (Throwable e) {
e.printStackTrace();
}finally {
System.out.println("环绕通知-->后置通知");
}
return result;
}切入点表达式:
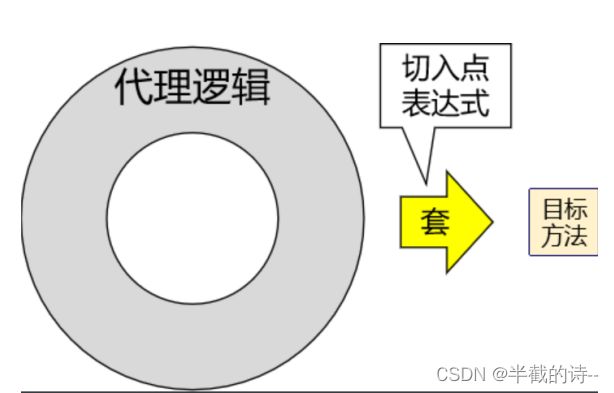
* 切入表达式:设置在标识通知的注解的value属性中
execution(连接点位置)
* execution(public int com.YKA.spring.aop_annotation.CalculatorImpl.add(int,int))
* 简写:execution(* com.YKA.spring.aop_annotation.CalculatorImpl.*(..))
* 第一个*表示任意的访问修饰符和返回值
* 第二个*表示类任意方法
* ..表示方法中任意的参数列表
* 类的地方也可以使用*,表示包下所以的类
* 重(chong)用切入点表达式:
* @Pointcut("execution(* com.YKA.spring.aop_annotation.CalculatorImpl.*(..))")
public void pointCut(){}
* 使用方式:@Before("pointCut()")
获取连接点信息
获取连接点的信息
* 在通知方法的参数位置,设置JoinPoint类型参数,就可以获取连接点所对应方法的信息
*@Before("pointCut()")
public void before(JoinPoint joinPoint){
//获取连接点所对应方法的签名信息,就是当前这个目标对象
Signature signature = joinPoint.getSignature();
signature.getName():获取方法名
//获取连接点所对应方法的参数
Object[] args = joinPoint.getArgs();
System.out.println("LoggerAspect, 方法名:"+signature.getName()+",
参数:"+Arrays.toString(args));
}切面的优先级
相同目标方法上同时存在多个切面时,切面的优先级控制切面的内外嵌套顺序。
优先级高的切面:外面
优先级低的切面:里面
使用@Order注解可以控制切面的优先级:
@Order注解的value属性设置优先级,默认值Integer的最大值,优先级最低
@Order(较小的数):优先级高
@Order(较大的数):优先级低

基于xml的实现Aop(了解)
声明式事物
JdbcTemplate
简介
Spring 框架对 JDBC 进行封装,使用 JdbcTemplate 方便实现对数据库操作
准备工作
①加入依赖
org.springframework
spring-context
5.3.1
org.springframework
spring-orm
5.3.1
org.springframework
spring-test
5.3.1
junit
junit
4.12
test
mysql
mysql-connector-java
8.0.16
com.alibaba
druid
1.0.31
②创建jdbc.properties
jdbc.driverClassName=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/buba?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&&rewriteBatchedStatements=true
jdbc.username=root
jdbc.password=123456③配置Spring的配置文件
测试
①在测试类装配 JdbcTemplate
测试类加两个注解为了方便:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:spring-jdbc.xml")
加上注解就不用在:ApplicationContext ioc = new ClassPathXmlApplicationContext("spring-factory.xml");
//指定当前测试类在spring的测试坏境中执行,此时就可以通过注入的方式直接获取IOC容器中bean
@RunWith(SpringJUnit4ClassRunner.class)
//设置spring测试坏境的配置文件
@ContextConfiguration("classpath:spring-jdbc.xml") //classpath:类路径,不加会报错
public class JdbcTemplateTest {
@Autowired
private JdbcTemplate jdbcTemplate;
}②测试增删改功能
@Test
//测试增删改功能
public void testUpdate(){
String sql = "insert into t_emp values(null,?,?,?)";
int result = jdbcTemplate.update(sql, "张三", 23, "男");
System.out.println(result);
}③查询一条数据为实体类对象
@Test
//查询一条数据为一个实体类对象
public void testSelectEmpById(){
String sql = "select * from t_emp where id = ?";
Emp emp = jdbcTemplate.queryForObject(sql, new BeanPropertyRowMapper<>(Emp.class), 1);
System.out.println(emp);
}④查询多条数据为一个list集合
@Test
//查询多条数据为一个list集合
public void testSelectList(){
String sql = "select * from t_emp";
List list = jdbcTemplate.query(sql, new BeanPropertyRowMapper<>(Emp.class));
list.forEach(emp -> System.out.println(emp));
} ⑤查询单行单列的值
@Test
//查询单行单列的值
public void selectCount(){
String sql = "select count(id) from t_emp";
Integer count = jdbcTemplate.queryForObject(sql, Integer.class);
System.out.println(count);
}声明式事务概念
Spring事物:
事物的四大特性:原子性,一致性,隔离性,持久性
事物的传播特性:
REQUIRED:支持当前事物,如果不存在,就新建一个(默认)
SUPPORTS:如果存在,就不使用事物
Requires_new: 如果有事务存在,挂起当前事务创建一个新的事务。
Mandatory:支持当前事务,如果不存在抛出异常。
Not_supported以非事务方式运行,如果有事务存在,挂起当前事务。
Never:以非事务方式运行,如果有事务存在,抛出异常
Nested:如果当前事务存在,则嵌套事务执行
事务的管理方式是采用Aop管理的
编程式事务
事务功能的相关操作全部通过自己编写代码来实现:
Connection conn = ...;
try {
// 开启事务:关闭事务的自动提交
conn.setAutoCommit(false);
// 核心操作
// 提交事务
conn.commit();
}catch(Exception e){
// 回滚事务
conn.rollBack();
}finally{
// 释放数据库连接
conn.close();
}编程式的实现方式存在缺陷:
细节没有被屏蔽:具体操作过程中,所有细节都需要程序员自己来完成,比较繁琐。
代码复用性不高:如果没有有效抽取出来,每次实现功能都需要自己编写代码,代码就没有得到复用。
声明式事务
事务的管理方式是采用Aop管理的
既然事务控制的代码有规律可循,代码的结构基本是确定的,所以框架就可以将固定模式的代码抽取出来,进行相关的封装。
封装起来后,我们只需要在配置文件中进行简单的配置即可完成操作。
好处1:提高开发效率
好处2:消除了冗余的代码
好处3:框架会综合考虑相关领域中在实际开发环境下有可能遇到的各种问题,进行了健壮 性、性能等各个方面的优化
所以,我们可以总结下面两个概念:
编程式:自己写代码实现功能
声明式:通过配置让框架实现功能
基于注解的声明式事务
测试无事务情况
①创建测试类
/指定当前测试类在spring的测试坏境中执行,此时就可以通过注入的方式直接获取IOC容器中bean
@RunWith(SpringJUnit4ClassRunner.class)
//设置spring测试坏境的配置文件
@ContextConfiguration("classpath:tx-annotation.xml") //classpath:类路径,不加会报错
public class TxByAnnotationTest {
@Autowired
private BookController bookController;
@Test
public void testBuyBook(){
bookController.buyBook(1, 1);
}
}②模拟场景
用户购买图书,先查询图书的价格,再更新图书的库存和用户的余额
假设用户id为1的用户,购买id为1的图书
用户余额为50,而图书价格为80
购买图书之后,用户的余额为-30,数据库中余额字段设置了无符号,因此无法将-30插入到余额字段
此时执行sql语句会抛出SQLException
③观察结果
因为没有添加事务,图书的库存更新了,但是用户的余额没有更新
显然这样的结果是错误的,购买图书是一个完整的功能,更新库存和更新余额要么都成功要么都失败
声明式事物的配置步骤:
事务的原理是AOP
* 1、在spring的配置文件中配置事物管理器(相当于是切面)
* 2、开启事物的注解驱动(相当于是切面中通知方法)
* 在需要被事物管理的方法上,添加@Transactional注解(相当于连接点),该方法就会被事物管理
* @Transactional注解标识的位置:
* 1、标识在方法上
* 2、表示在类上,则类中的所有方法都会被事物管理加入事务
①添加事务配置
事务的管理方式是采用Aop管理的
②添加事务注解
因为service层表示业务逻辑层,一个方法表示一个完成的功能,因此处理事务一般在service层处理
出现异常自动回滚
@Transactional
public void buyBook(Integer bookId, Integer userId) {
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
//System.out.println(1/0);
}在BookServiceImpl的buybook()添加注解@Transactional
③观察结果
由于使用了Spring的声明式事务,更新库存和更新余额都没有执行
@Transactional注解标识的位置
@Transactional标识在方法上,咋只会影响该方法
@Transactional标识的类上,咋会影响类中所有的方法
事务属性:只读
①介绍
对一个查询操作来说,如果我们把它设置成只读,就能够明确告诉数据库,这个操作不涉及写操作。这样数据库就能够针对查询操作来进行优化。只读只针对查询语句
②使用方式
@Transactional(readOnly = true)
public void buyBook(Integer bookId, Integer userId) {
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
//System.out.println(1/0);
}③注意
对增删改操作设置只读会抛出下面异常:
Caused by: java.sql.SQLException: Connection is read-only. Queries leading to data modification
are not allowed
事务属性:超时
①介绍
事务在执行过程中,有可能因为遇到某些问题,导致程序卡住,从而长时间占用数据库资源。而长时间占用资源,大概率是因为程序运行出现了问题(可能是Java程序或MySQL数据库或网络连接等等)。
此时这个很可能出问题的程序应该被回滚,撤销它已做的操作,事务结束,把资源让出来,让其他正常程序可以执行。
概括来说就是一句话:超时回滚,释放资源。
②使用方式
@Transactional(timeout = 3)//设置时间,如果执行时超出时间,自动强制回滚
public void buyBook(Integer bookId, Integer userId) {
try {
TimeUnit.SECONDS.sleep(5);//测试休眠5秒,上面设置的是3秒,所以没有执行完就会报错
} catch (InterruptedException e) {
e.printStackTrace();
}
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
//System.out.println(1/0);
}③观察结果
执行过程中抛出异常:
org.springframework.transaction.TransactionTimedOutException: Transaction timed out:
deadline was Fri Jun 04 16:25:39 CST 2022
事务属性:回滚策略
①介绍
声明式事务默认只针对运行时异常回滚,编译时异常不回滚。
可以通过@Transactional中相关属性设置回滚策略
前两个一般不用,因为所有运行时异常都会进行回滚
前两个是指定一个或多个异常,出现该异常回滚
后两个是指定一个或多个异常,出现该异常不会回滚
rollbackFor属性:需要设置一个Class类型的对象
rollbackForClassName属性:需要设置一个字符串类型的全类名
noRollbackFor属性:需要设置一个Class类型的对象,数组类型
rollbackFor属性:需要设置一个字符串类型的全类名
②使用方式
@Transactional(noRollbackFor = ArithmeticException.class)
//@Transactional(noRollbackForClassName = "java.lang.ArithmeticException")
public void buyBook(Integer bookId, Integer userId) {
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
System.out.println(1/0);
}③观察结果
虽然购买图书功能中出现了数学运算异常(ArithmeticException),但是我们设置的回滚策略是,当
出现ArithmeticException不发生回滚,因此购买图书的操作正常执行
事务属性:事务隔离级别
①介绍
数据库系统必须具有隔离并发运行各个事务的能力,使它们不会相互影响,避免各种并发问题。一个事
务与其他事务隔离的程度称为隔离级别。SQL标准中规定了多种事务隔离级别,不同隔离级别对应不同
的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱。
隔离级别一共有四种:
读未提交:READ UNCOMMITTED:允许Transaction01读取Transaction02未提交的修改。
读已提交:READ COMMITTED:要求Transaction01只能读取Transaction02已提交的修改。
可重复读:REPEATABLE READ:
确保Transaction01可以多次从一个字段中读取到相同的值,即Transaction01执行期间禁止其它
事务对这个字段进行更新。
串行化:SERIALIZABLE:
确保Transaction01可以多次从一个表中读取到相同的行,在Transaction01执行期间,禁止其它
事务对这个表进行添加、更新、删除操作。可以避免任何并发问题,但性能十分低下。
各个隔离级别解决并发问题的能力见下表:
| 隔离级别 |
脏读 |
不可重复读 |
幻读 |
| READ UNCOMMITTED |
有 |
有 |
有 |
| READ COMMITTED |
无 |
有 |
有 |
| REPEATABLE READ |
无 |
无 |
有 |
| SERIALIZABLE |
无 |
无 |
无 |
各种数据库产品对事务隔离级别的支持程度:
| 隔离级别 |
Oracle |
MySQL |
| READ UNCOMMITTED |
× |
√ |
| READ COMMITTED |
√(默认) |
√ |
| REPEATABLE READ |
× |
√(默认) |
| SERIALIZABLE |
√ |
√ |
②使用方式
@Transactional(isolation = Isolation.DEFAULT)//使用数据库默认的隔离级别
@Transactional(isolation = Isolation.READ_UNCOMMITTED)//读未提交
@Transactional(isolation = Isolation.READ_COMMITTED)//读已提交
@Transactional(isolation = Isolation.REPEATABLE_READ)//可重复读
@Transactional(isolation = Isolation.SERIALIZABLE)//串行化事务属性:事务传播行为
①介绍
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
②测试
创建接口CheckoutService:
public interface CheckoutService {
void checkout(Integer[] bookIds, Integer userId);
}创建实现类CheckoutServiceImpl:没有添加传播行为
@Service
public class CheckoutServiceImpl implements CheckoutService {
@Autowired
private BookService bookService;
@Override
@Transactional
//一次购买多本图书
public void checkout(Integer[] bookIds, Integer userId) {
for (Integer bookId : bookIds) {
bookService.buyBook(bookId, userId);
}
}
}BookServiceImpl类:设置了传播行为
@Service
public class BookServiceImpl implements BookService {
@Autowired
private BookDao bookDao;
@Override
//事物注解
@Transactional(
//事物属性
//readOnly = true 只读属性
//timeout = 3 超时属性 设置3秒,执行三秒后还没执行完,就强制回滚
//noRollbackFor = ArithmeticException.class 回滚属性 //如果出现算术异常就不会回 滚,正常进行修改操作
propagation = Propagation.REQUIRES_NEW //事物传播特性,创建一个新事物
)
public void buyBook(Integer userId, Integer bookId) {
//根据id查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId,price);
// System.out.println(1/0);
}
}在BookController中添加方法:
@Autowired
private CheckoutService checkoutService;
public void checkout(Integer[] bookIds, Integer userId){
checkoutService.checkout(bookIds, userId);
}在数据库中将用户的余额修改为100元
③观察结果
可以通过@Transactional中的propagation属性设置事务传播行为
修改BookServiceImpl中buyBook()上,注解@Transactional的propagation属性
@Transactional(propagation = Propagation.REQUIRED),默认情况,表示如果当前线程上有已经开
启的事务可用,那么就在当前事务中运行,调用的哪个方法就用该方式上的事物。
经过观察,购买图书的方法buyBook()在checkout()中被调用,checkout()上有事务注解,因此在此事务中执行。所购买的两本图书的价格为80和50,而用户的余额为100,因此在购买第二本图书时余额不足失败,导致整个checkout()回滚,即只要有一本书买不了,就都买不了
@Transactional(propagation = Propagation.REQUIRES_NEW),表示不管当前线程上是否有已经开启的事务,都要开启新事务。
同样的场景,每次购买图书都是在buyBook()的事务中执行,因此第一本图书购买成功,事务结束,第二本图书购买失败,只在第二次的buyBook()中回滚,购买第一本图书不受影响,即能买几本就买几本
基于xml声明式事务(了解)