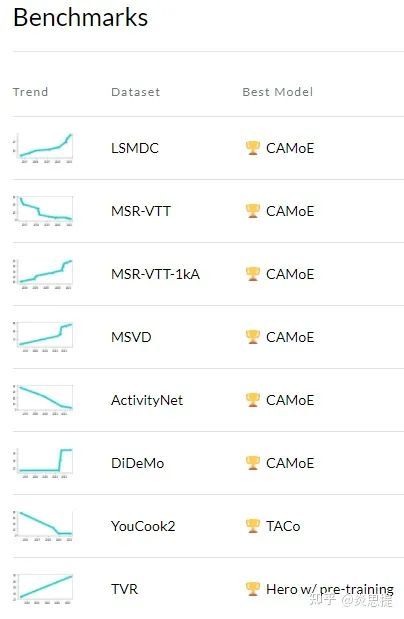
CAMoE——屠榜 video retrieval challenge
关注公众号,发现CV技术之美
作者:炎思提
原文:https://zhuanlan.zhihu.com/p/425226244
本文转自知乎,已获作者授权,请勿二次转载。
✎ 编 者 言
来自今年九月arXiv上一篇关于视频检索文章。作者来自国科大和快手,提出CAMoE模型,投稿AAAI。实验结果非常恐怖,在几乎所有主流数据集上达到SoTA,其中video retrieval challenge刷榜6个数据集,而文章所作改变非常小,主体上仅修改了loss,而且代码量仅1行。本文工作我认为非常有意义,因此将详细描述文章各个模块和步骤,最后给出思考。
详细信息如下:

论文名称:Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
论文链接:https://arxiv.org/abs/2109.04290
项目链接:https://github.com/starmemda/CAMoE/
video retrieval challenge
01
Overall structure
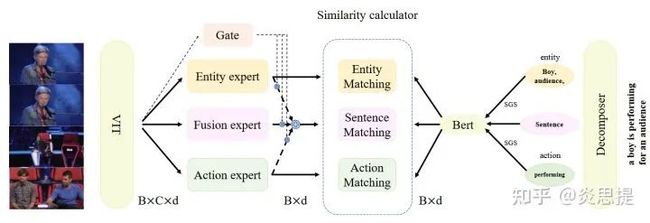
语义方面:使用POS和SGS分别解析语句和整合语句,应用CLIP预训练的Bert进行语义提取。这里的Bert应该是CLIP中的使用的Bert。
视觉方面:使用CLIP预训练的ViT提取feature。分流成三路,使用三种expert加一个Gate模块。这里的Gate只对fusion expert做限制,因为作者认为由于fusion expert采集了整体的信息,导致加入到网络的信息太丰富,这会导致其余两个entity和action expert的学习任务太simple,所以要对fusion做限制。
最后整体进行similarity的计算,得到
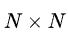 的相似度矩阵,取矩阵对角线之和为loss值。
的相似度矩阵,取矩阵对角线之和为loss值。
02
Sentence generation strategy
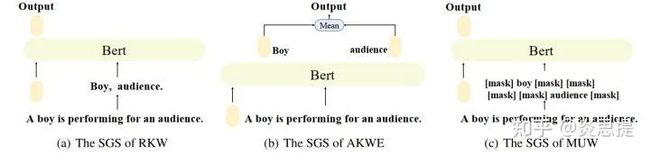
文章测试了三种生成Entity和action embedding的结构。
将词性分割后提取出的单词直接输入Bert,输出CLS embedding
整句输入,将对应词性的单词平均
mask掉无关词,句子长度不变。CLS embedding作为输出
03
Visual Frames Aggregation Scheme
B个视频为一个Batch,每个视频提取C帧,每一帧为d维向量,所以我们编码的数据为 ![]() .作者同样采用三种聚合方式。注意这里聚合的方式是聚合C方向,保留d和B,最后得到
.作者同样采用三种聚合方式。注意这里聚合的方式是聚合C方向,保留d和B,最后得到 ![]() .
.
采用mean pooling,但这个mean pooling不是检测里那种,而是直接将x从C的方向上压缩平均


Squeeze-and-Excitation attention(se attention):简言之,给mean pooling加入一个重要性分数score。

self-attention:这个就不介绍了吧。
04
Loss function
original loss function:
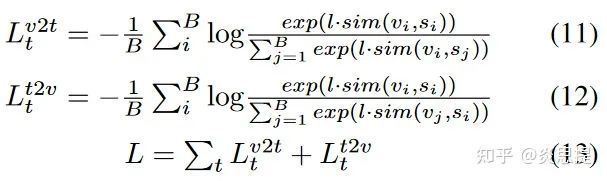
用图像理解,就是对着下面这幅图按列取softmax,再按行取softmax,最后将对角线上的概率求和,得到loss:

Dual -softmax loss function
这个function可以被视作是本文的灵魂。式子如下:
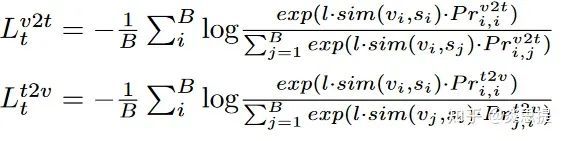
其中P_r计算式如下:
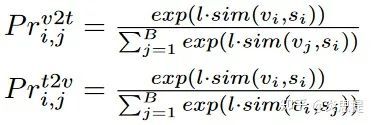
看起来非常繁琐,但是仔细一看,其实非常简单,代码一行就能解决。以下图中的数据为例,我用尽量简洁的语言描述:
首先,我们假设对角线上的概率表征与GT的匹配程度。就是说对角线是一个视频文本pair。
当我们需要求解video→text的匹配程度,按照原来的loss求解,是对相似度矩阵每一行做softmax,如图,得到的概率最大值都为第一列。即每一个视频都选择了第一个文本作为最优的描述sentence。
但是作者在求解video→text的匹配程度时,是先求解text→video的匹配程度(概率矩阵),即按列做softmax。这个时候我们可以看到图中第一个文本选择第一个视频作为最优,第二个选择了第二个视频,第三个还是选择了第一个视频。接着将这个概率矩阵与原矩阵相乘,得到revise后的相似度矩阵,最后求解video→text,也就是按行做softmax得到最后的概率矩阵。
结果是,经过逆向任务revise后,正向任务的精确程度提升了。对角线上是最高概率。

而实现的代码更简单,作者git仓库中github.com/starmemda/CA只有一个文件,代码如下:
from torch import nn
import torch.nn.functional as F
import torch
class dual_softmax_loss(nn.Module):
def __init__(self,):
super(dual_softmax_loss, self).__init__()
def forward(self, sim_matrix, temp=1000):
sim_matrix = sim_matrix * F.softmax(sim_matrix/temp, dim=0)*len(sim_matrix) #With an appropriate temperature parameter, the model achieves higher performance
logpt = F.log_softmax(sim_matrix, dim=-1)
logpt = torch.diag(logpt)
loss = -logpt
return loss05
Experiment
文章中在三个数据集上做了实验,全部SoTA。下图是在LSMDC(最多数据量)和MSVD(最难数据集)上的表现:
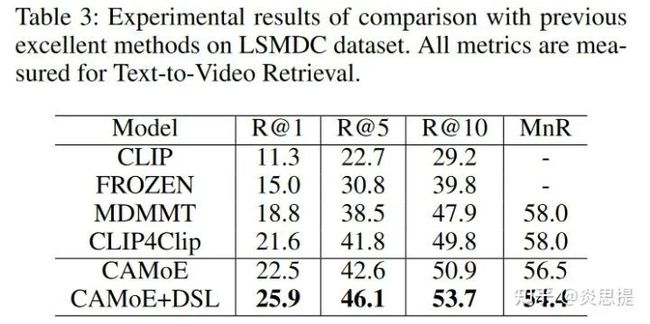

其实看到这样的结果,对于它达到SoTA我并不意外,因为结合了CLIP的模型,借助于大规模数据集,再对自己的模型进行一些调优达到SoTA并不难,但是加入了Dual-softmax loss后,模型提高了2~3个点的确令人吃惊,也倍感欣喜。因为从直觉上来看,DSL确实使得T2V和V2T两个任务的交互更加紧密,也更容易抑制过拟合。
Ablation study
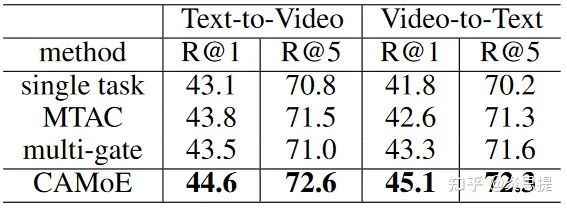
消融实验
消融实验中,V2T的表现优于T2V。作者解释:文本标注可能会有歧义。例如:狗在玩耍——视频1,猫和狗在一起玩耍——视频2.那么用视频去选择句子时,模型就会直接偷懒,因为“狗在玩耍”一定是比“猫和狗在一起玩耍”的内容范围要更大的,那么既然选第一句一定不会错,那么为啥还要费力去选择第二句呢?而视频出现歧义的可能性几乎没有,所以这也是为什么V2T的表现优于T2V的原因。对于作者这个观点我也很赞同。
Visualization
相似度最高的点明显更加聚集到了对角线附近。
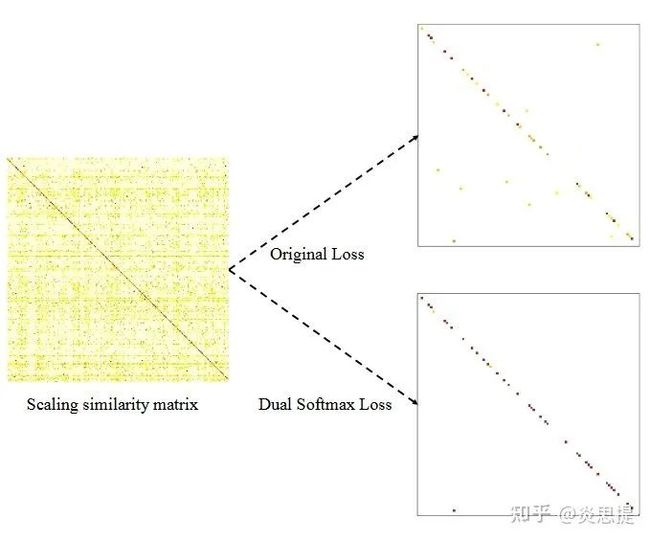
可视化结果
06
Reflection
这篇文章给我很大的震撼,不仅在于其极强的performance,更在于他所作的工作非常优美。总结一下,表现在下面两点:
观点和动机:
作者的观察和解释我认为很有趣,也很有意义。文章最大的亮点在于如何将正向检索和逆向检索综合,使得两者进行互补,从而引入了DSL。而文中对一些现象的解释我觉得也很有道理,非常符合直觉。
实现方式:
通过修改loss,直接就优化了模型,而且代码量极少,非常容易迁移到其余存在正逆向的任务上。但这一点,也是我认为本文的一点不足。对于DSL提出的理论依据不够强,只凭借直觉多少有点玄虚。
其次,是我自己对这个模型的一些思考。
我认为这个模型最大的亮点,最本质的解释就是加入了先验。比如在T2V任务中,我们引入了V2T,其本质就是我们认为V2T任务是一个值得我们信赖的任务,我们认为其携带的信息能够指导T2V任务,这也是本文最大的假设,最后也证明这个先验确实不错。从这个角度出发,我们对模型的改进其实不仅仅是对输入进行先验的补充,其实可以把思路扩展到如何对网络内部已经产生的结果,将其假设为先验,加入到模型的优化中,这一点与Resnet又有一点相似了。
总结来说,文章做的很漂亮,结果和解释也对的上,期待AAAI2022能见到本文。

END
欢迎加入「视频检索」交流群备注:VTR
