TensorFlow----Keras库
目录
1.网络层类
2.网络容器
3.模型装配
4.模型训练
5.模型测试
6.模型保存
(1)张量方式
(2)网络方式
(3)SavedModel方式
7.自定义网络
(1)自定义网络层
(2)自定义网络
8.测量工具
(1)构造测量器
(2)写入数据
(3)读取统计信息
(4)清除状态
9.可视化
(1)模型端
(2)浏览器端
参考来源:主页 - Keras 中文文档
Keras 提供了一系列高层的神经网络相关类和函数,如经典数据集加载函数、 网络层
类、 模型容器、 损失函数类、 优化器类、 经典模型类等
导入keras,只能从tensorflow中导入,否则导入的是标准的Keras库 :
from tensorflow import keras1.网络层类
对于常见的网络层,一般直接使用层方式来完成模型的搭建,在 tf.keras.layers 命名空间中提供了大量常见网络层的类,如全连接层、 激活函数层、 池化层、 卷积层、 循环神经网络层
网络层类,只需要在创建时指定网络层的相关参数, 并调用__call__方法即可完成前向计算。在调用__call__方法时, Keras 会自动调用每个层的前向传播逻辑,这些逻辑一般实现在类的
call 函数中
eg: 通过 layers.Softmax(axis)类搭建 Softmax 网络层
import tensorflow as tf
from tensorflow import keras # 导入keras,只能从tf中导入,否则导入的是标准的Keras库
from tensorflow.keras import layers # 导入网络层类
# 创建 Softmax 层,并调用__call__方法完成前向计算
x = tf.constant([2., 1.0, 0.1]) # 创建张量
layer = layers.Softmax(axis=-1) # 创建Softmax层
out = layer(x) # 向前计算,其实是调用的call
print(out)
直接调用tf.nn.softmax()函数也是一样的效果
out = tf.nn.softmax(x)2.网络容器
对于常见的网络,需要手动调用每一层的类实例完成前向传播运算,当网络层数变得
较深时, 这一部分代码显得非常臃肿。可以通过 Keras 提供的网络容器 Sequential 将多个
网络层封装成一个大网络模型,只需要调用网络模型的实例一次即可完成数据从第一层到
最末层的顺序传播运算
eg: 2层的全连接层和激活函数层
import tensorflow as tf
from tensorflow import keras # 导入keras,只能从tf中导入,否则导入的是标准的Keras库
from tensorflow.keras import layers, Sequential
# 封装一个大型网络
network = Sequential([
layers.Dense(3, activation=None), # 全连接层,不用激活函数
layers.ReLU(), # 激活函数层
layers.Dense(2, activation=None),
layers.ReLU() # 激活函数层
])
x = tf.random.normal([4, 3])
out = network(x) # 调用call(),输入从第一层开始, 逐层传播至输出层,并返回输出层的输出
network.build(input_shape=(4, 4)) # 创建网络层参数
network.summary() # 打印出网络结构和参数量
通过 add()方法继续追加新的网络层, 实现动态创建网络的功能
layers_num = 2 # 堆叠 2 次
network = Sequential([]) # 先创建空的网络容器
for _ in range(layers_num):
network.add(layers.Dense(3)) # 添加全连接层
network.add(layers.ReLU()) # 添加激活函数层注意,在通过Sequential容器创建对应层数的网络结构,在完成网络创建时, 网络层类并没有创建内部权值张量等成员变量,此时通过调用类的 build 方法并指定输入大小,即可自动创建所有层的内部张量。
通过 summary()函数可以方便打印出网络结构和参数量
输出结果:
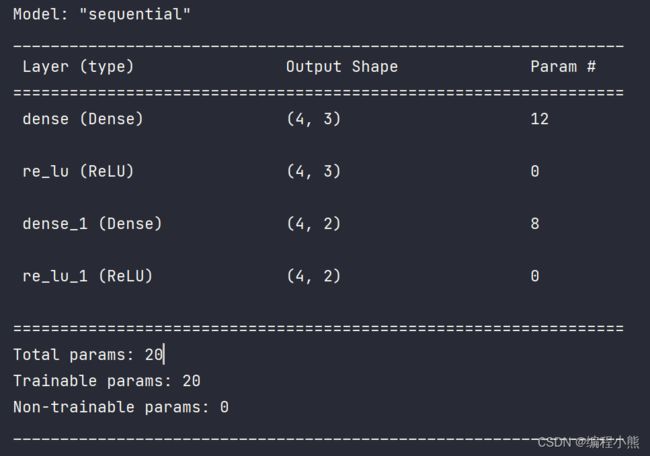
Layer 列为每层的名字,这个名字由 TensorFlow 内部维护,与 Python 的对象名并不一样。 Param#列为层的参数个数, Total params 项统计出了总的参数量, Trainable params
为总的待优化参数量, Non-trainable params 为总的不需要优化的参数量
当通过 Sequential 容量封装多个网络层时, 每层的参数列表将会自动并入Sequential 容器的参数列表中。 Sequential 对象的 trainable_variables 和 variables 包含了所有层的待优化张量列表
和全部张量列表
# 打印网络的待优化参数名与shape
for item in network.trainable_variables:
print(item.name, item.shape)
'''
dense/kernel:0 (3, 3)
dense/bias:0 (3,)
dense_1/kernel:0 (3, 2)
dense_1/bias:0 (2,)
'''3.模型装配
在训练网络时,一般的流程是通过前向计算获得网络的输出值, 再通过损失函数计算网络误差,然后通过自动求导工具计算梯度并更新,同时间隔性地测试网络的性能
对于这种常用的训练逻辑,可以直接通过 Keras 提供的模型装配与训练等高层接口实现
在 Keras 中,有 2 个比较特殊的类: keras.Model 和 keras.layers.Layer 类。其中 Layer类是网络层的母类,定义了网络层的一些常见功能,如添加权值、 管理权值列表等。
Model 类是网络的母类,除了具有 Layer 类的功能,还添加了保存模型、加载模型、 训练
与测试模型等便捷功能
Sequential 也是 Model 的子类, 因此具有 Model 类的所有功能
在创建网络后,正常的流程是循环迭代数据集多个 Epoch,每次按批产生训练数据、 前向计
算,然后通过损失函数计算误差值,并反向传播自动计算梯度、 更新网络参数
在 Keras 中提供了 compile()和 fit()函数方便实现上述逻辑。 首先通过compile 函数指定网络使用的优化器对象、 损失函数类型, 评价指标等设定,这一步称为装配。
# 导入优化器,损失函数模块
from tensorflow.keras import optimizers,losses
# 模型装配
# 采用 Adam 优化器,学习率为 0.01; 采用交叉熵损失函数,包含 Softmax
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'] # 设置测量指标为准确率
)4.模型训练
模型装配完成后,可通过 fit()函数送入待训练的数据集和验证用的数据集,这一步称为模型训练
# 指定训练集为 train_db,验证集为 val_db,训练 5 个 epochs,每 2 个 epoch 验证一次
# 返回训练轨迹信息保存在 history 对象中
history = network.fit(train_db, epochs=5, validation_data=val_db,
validation_freq=2)其中 train_db 为 tf.data.Dataset 对象;epochs 参数指定训练迭代的 Epoch 数量;validation_data 参数指定用于验证(测试)的数据集和验证的频率validation_freq
上述代码即可实现网络的训练与验证的功能, fit 函数会返回训练过程的数据记录history, 其中 history.history 为字典对象,包含了训练过程中的 loss、 测量指标等记录项,可以直接查看这些训练数据:history.history
fit()函数的运行代表了网络的训练过程,因此会消耗相当的训练时间,并在训练结束后才返回,训练中产生的历史数据可以通过返回值对象取得
可以看到通过 compile&fit 方式实现的代码非常简洁和高效,大大缩减了开发时间
5.模型测试
Model 基类除了可以便捷地完成网络的装配与训练、验证,还可以预测和测试。通过 Model.predict(x)方法即可完成模型的预测
x,y = next(iter(db_train))
print('predict x:', x.shape) # 打印当前 batch 的形状
out = network.predict(x) # 模型预测,预测结果保存在 out 中
print(out)out 即为网络的输出,通过上述代码即可使用训练好的模型去预测新样本的标签信息
可以通过 Model.evaluate()测试模型的性能指标
network.evaluate(db_test) # 模型测试,测试在 db_test 上的性能表
6.模型保存
模型训练完成后,需要将模型保存到文件系统上,从而方便后续的模型测试与部署工作。 如果能够间断地保存模型状态到文件系统,即使发生宕机等意外,也可以从最近一次的网络状态文件中恢复,从而避免浪费大量的训练时间和计算资源
(1)张量方式
网络的状态主要体现在网络的结构以及网络层内部张量数据上,因此在拥有网络结构源文件的条件下,直接保存网络张量参数到文件系统上是最轻量级的一种方式
通过调用 Model.save_weights(path)方法即可将当前的网络参数保存到 path 文件上
# 保存模型参数到文件上
network.save_weights('weights.ckpt')
....
# 重新搭建相同的网络结构
...
# 从参数文件中读取数据并写入当前网络
network.load_weights('weights.ckpt')这种保存与加载网络的方式最为轻量级, 文件中保存的仅仅是张量参数的数值,并没有其它额外的结构参数。 但是它需要使用相同的网络结构才能够正确恢复网络状态,因此一般在拥有网络源文件的情况下使用
(2)网络方式
通过 Model.save(path)函数可以将模型的结构以及模型的参数保存到 path 文件上,在需要网络源文件的条件下,通过 keras.models.load_model(path)即可恢复网络结构和网络参数
# 保存模型结构与模型参数到文件
network.save('model.h5')
del network # 删除网络对象
# 从文件恢复网络结构与网络参数
network = keras.models.load_model('model.h5')model.h5 文件除了保存了模型参数外,还应保存了网络结构信息,不需要提前创建模型即可直接从文件中恢复出网络 network 对象
(3)SavedModel方式
通过 tf.saved_model.save (network, path)即可将模型以 SavedModel 方式保存到 path 目录中
# 保存模型结构与模型参数到文件
tf.saved_model.save(network, 'model-savedmodel')
del network # 删除网络对象
network = tf.saved_model.load('model-savedmodel')
用户无需关心文件的保存格式,只需要通过 tf.saved_model.load 函数即可恢复出模型对象
7.自定义网络
对于需要创建自定义逻辑的网络层,可以通过自定义类来实现。在创建自定义网络层类时,需要继承自 layers.Layer 基类; 创建自定义的网络类时,需要继承自 keras.Model 基类, 这样建立的自定义类才能够方便的利用 Layer/Model 基类提供的参数管理等功能,同时也能够与其他的标准网络层类交互使用
(1)自定义网络层
对于自定义的网络层, 至少需要实现初始化__init__方法和前向传播逻辑 call 方法
假设需要一个没有偏置向量的全连接层,即 bias 为0, 同时固定激活函数为 ReLU 函数
# 自定义网络层
class MyDence(layers.Layer):
# 自定义类的初始化
def __init__(self, inp_dim, outp_dim):
# 继承父类,并定义新功能 super
super(MyDence, self).__init__()
# 创建权值张量并添加到类管理列表中,设置为需要优化
self.kernel = self.add_variable('w', [inp_dim, outp_dim], trainable=True)
# self.bias = self.add_variable('b', [outp_dim])
# 自定义类的向前计算逻辑
def call(self, inputs, training=None):
# X@W
out = inputs @ self.kernel
# 添加激活函数relu
out = tf.nn.relu(out)
return out
# 创建自定义层类的实例化
net = MyDence(4, 3) # 输入为4,输出为3个节点首先创建类,并继承自 Layer 基类。 创建初始化方法,并调用母类的初始化函数, 由于是全连接层, 因此需要设置两个参数:输入特征的长度 inp_dim 和输出特征的长度outp_dim,并通过 self.add_variable(name, shape)创建 shape 大小,名字为 name 的张量,并设置为需要优化,加入到类管理列表中
完成自定义类的初始化工作后,然后设计自定义类的前向运算逻辑,只需要完成 = @矩阵运算,并通过固定的 ReLU 激活函数即可
自定义类的前向运算逻辑实现在 call(inputs, training=None)函数中,其中 inputs代表输入, 由用户在调用时传入; training 参数用于指定模型的状态: training 为 True 时执行训练模式, training 为 False 时执行测试模式,默认参数为 None,即测试模式。
由于全连接层的训练模式和测试模式逻辑一致,此处不需要额外处理。对于部份测试模式和训练模
式不一致的网络层,需要根据 training 参数来设计需要执行的逻辑
(2)自定义网络
在完成了自定义的全连接层类的实现,通过Sequential容器封装一个网络模型
# 自定义网络类
class MyModel(keras.Model):
# 网络类网络层的搭建
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = MyDence(28*28, 256)
self.fc2 = MyDence(256, 128)
self.fc3 = MyDence(128, 64)
self.fc4 = MyDence(64, 32)
self.fc5 = MyDence(32, 10)
# 网络类向前计算逻辑
def call(self, inputs, training=None):
x = self.fc1(inputs)
x = self.fc2(x)
x = self.fc3(x)
x = self.fc4(x)
x = self.fc5(x)
return xSequential 容器适合于数据按序从第一层传播到第二层,再从第二层传播到第三层,以此规律传播的网络模型。对于复杂的网络结构,例如第三层的输入不仅是第二层的输出,还有第一层的输出,此时使用自定义网络更加灵活。
创建自定义网络类,首先创建类, 并继承自 Model 基类,分别创建对应的网络层对象,搭建网络结构,然后自定义网络的向前计算逻辑
8.测量工具
在网络的训练过程中,经常需要统计准确率、 召回率等测量指标,除了可以通过手动计算的方式获取这些统计数据外, Keras 提供了一些常用的测量工具,位于 keras.metrics 模块中,专门用于统计训练过程中常用的指标数据
在 keras.metrics 模块中,提供了较多的常用测量器类, 如统计平均值的 Mean 类,统计准确率的 Accuracy 类,统计余弦相似度的 CosineSimilarity 类
Keras 的测量工具的使用方法一般有 4 个主要步骤: 新建测量器, 写入数据,读取统计数据和清零测量器
统计误差值:
(1)构造测量器
# 新建平均测量器,适合 Loss 数据
loss_meter = metrics.Mean()(2)写入数据
通过测量器的 update_state 函数可以写入新的数据,测量器会根据自身逻辑记录并处理采样数据
# 记录采样的数据,通过 float()函数将张量转换为普通数值
# 在每个 Step 结束时采集一次 loss 值
loss_meter.update_state(float(loss))上述采样代码放置在每个 Batch 运算结束后, 测量器会自动根据采样的数据来统计平均值
(3)读取统计信息
在采样多次数据后, 可以选择在需要的地方调用测量器的 result()函数,来获取统计值。
# 打印统计期间的平均 loss
print(step, 'loss:', loss_meter.result())(4)清除状态
由于测量器会统计所有历史记录的数据,因此在启动新一轮统计时, 有必要清除历史状态。通过 reset_states()即可实现清除状态功能。
在每次读取完平均误差后, 清零统计信息,以便下一轮统计的开始
if step % 100 == 0:
# 打印统计的平均 loss
print(step, 'loss:', loss_meter.result())
loss_meter.reset_states() # 打印完后, 清零测量器
9.可视化
在网络训练的过程中,通过 Web 端远程监控网络的训练进度,可视化网络的训练结果, 对于提高开发效率和实现远程监控是非常重要的。
TensorFlow 提供了一个专门的可视化工具,叫做TensorBoard, 它通过 TensorFlow 将监控数据写入到文件系统, 并利用 Web后端监控对应的文件目录, 从而可以允许用户从远程查看网络的监控数据
(1)模型端
在模型端,需要创建写入监控数据的 Summary 类, 并在需要的时候写入监控数据。 首先通过 tf.summary.create_file_writer 创建监控对象类实例,并指定监控数据的写入目录
监控误差数据和可视化图片数据
# 创建监控类,监控数据将写入 log_dir 目录
summary_writer = tf.summary.create_file_writer(log_dir)
with summary_writer.as_default(): # 写入环境
# 当前时间戳 step 上的数据为 loss,写入到名为 train-loss 数据库中
tf.summary.scalar('train-loss', float(loss), step=step)
# 写入测试准确率
tf.summary.scalar('test-acc', float(total_correct / total),
step=step)
# 可视化测试用的图片,设置最多可视化 9 张图片
tf.summary.image("val-onebyone-images:", val_images,
max_outputs=9, step=step)通过 tf.summary.scalar 函数记录监控数据,并指定时间戳 step 参数。这里的 step 参数类似于每个数据对应的时间刻度信息, 也可以理解为数据曲线的坐标
通过 tf.summary.image 函数写入监控图片数。运行模型程序,相应的数据将实时写入到指定文件目录中
(2)浏览器端
在运行程序时, 监控数据被写入到指定文件目录中。如果要实时远程查看、可视化这些数据,还需要借助于浏览器和 Web 后端。首先是打开 Web 后端, 通过在 cmd 终端运行tensorboard --logdir path 指定 Web 后端监控的文件目录 path, 即可打开 Web 后端监控进程
打开网址即可看到