Pytorch 自定义激活函数前向与反向传播 sigmoid
文章目录
-
- Sigmoid
-
- 公式
- 求导过程
- 优点:
- 缺点:
- 自定义Sigmoid
- 与Torch定义的比较
- 可视化
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
%matplotlib inline
plt.rcParams['figure.figsize'] = (7, 3.5)
plt.rcParams['figure.dpi'] = 150
plt.rcParams['axes.unicode_minus'] = False #解决坐标轴负数的铅显示问题
Sigmoid
公式
sigmoid ( x ) = σ ( x ) = 1 1 + e − x \text{sigmoid}(x)= \sigma(x) = \frac{1}{1+e^{-x}} sigmoid(x)=σ(x)=1+e−x1
求导过程
σ ′ ( x ) = [ ( 1 + e − x ) − 1 ] ′ = ( − 1 ) ( 1 + e − x ) − 2 ( − 1 ) e − x = ( 1 + e − x ) − 2 e − x = e − x ( 1 + e − x ) 2 = 1 + e − x − 1 ( 1 + e − x ) 2 = 1 + e − x ( 1 + e − x ) 2 − 1 ( 1 + e − x ) 2 = 1 ( 1 + e − x ) ( 1 − 1 ( 1 + e − x ) ) = σ ( x ) ( 1 − σ ( x ) ) \begin{aligned} \sigma'(x) =&[(1+e^{-x})^{-1}]' \\ =&(-1)(1+e^{-x})^{-2}(-1)e^{-x}\\ =&(1+e^{-x})^{-2}e^{-x}\\ =&\frac{e^{-x}}{(1+e^{-x})^2} \\ =&\frac{1+e^{-x}-1}{(1+e^{-x})^2} \\ =&\frac{1+e^{-x}}{(1+e^{-x})^2} - \frac{1}{(1+e^{-x})^2} \\ =&\frac{1}{(1+e^{-x})}(1-\frac{1}{(1+e^{-x})}) \\ =&\sigma(x)(1-{\sigma(x)}) \end{aligned} σ′(x)========[(1+e−x)−1]′(−1)(1+e−x)−2(−1)e−x(1+e−x)−2e−x(1+e−x)2e−x(1+e−x)21+e−x−1(1+e−x)21+e−x−(1+e−x)21(1+e−x)1(1−(1+e−x)1)σ(x)(1−σ(x))
用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid作为激活函数有以下优缺点:
优点:
- 输出范围有限,数据在传递的过程中不容易发散。
- 输出范围为(0,1),所以可以用作输出层,输出表示概率。
- 抑制两头,对中间细微变化敏感,对分类有利。
- 在特征相差比较复杂或是相差不是特别大时效果比较好。
缺点:
- 梯度消失(Gradient Vanishing)会导致backpropagate时,w的系数太小,w更新很慢。所以对初始化时要特别注意,避免过大的初始值使神经元进入饱和区。
- 输出不是zero-center 这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in ),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。 如果你是按batch去训练,那么每个batch可能得到不同的符号(正或负),那么相加一下这个问题还是可以缓解
- 指数运算耗时,计算效率低
自定义Sigmoid
class SelfDefinedSigmoid(torch.autograd.Function):
@staticmethod
def forward(ctx, inp):
result = torch.divide(torch.tensor(1), (1 + torch.exp(-inp)))
ctx.save_for_backward(result)
return result
@staticmethod
def backward(ctx, grad_output):
# ctx.saved_tensors is tuple (tensors, grad_fn)
result, = ctx.saved_tensors
return grad_output * result * (1 - result)
class Sigmoid(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
out = SelfDefinedSigmoid.apply(x)
return out
与Torch定义的比较
# self defined
torch.manual_seed(0)
sigmoid = Sigmoid() # SelfDefinedSigmoid
inp = torch.randn(5, requires_grad=True)
out = sigmoid((inp + 1).pow(2))
print(f'Out is\n{out}')
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nFirst call\n{inp.grad}")
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
Out is
tensor([0.9984, 0.6223, 0.8005, 0.9213, 0.5018],
grad_fn=)
First call
tensor([ 0.0080, 0.3322, -0.3765, 0.2275, -0.0423])
Second call
tensor([ 0.0159, 0.6643, -0.7530, 0.4549, -0.0845])
Call after zeroing gradients
tensor([ 0.0080, 0.3322, -0.3765, 0.2275, -0.0423])
# torch defined
torch.manual_seed(0)
inp = torch.randn(5, requires_grad=True)
out = torch.sigmoid((inp + 1).pow(2))
print(f'Out is\n{out}')
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nFirst call\n{inp.grad}")
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
Out is
tensor([0.9984, 0.6223, 0.8005, 0.9213, 0.5018], grad_fn=)
First call
tensor([ 0.0080, 0.3322, -0.3765, 0.2275, -0.0423])
Second call
tensor([ 0.0159, 0.6643, -0.7530, 0.4549, -0.0845])
Call after zeroing gradients
tensor([ 0.0080, 0.3322, -0.3765, 0.2275, -0.0423])
从上面结果,可以看出与torch定义sigmoid得到是一样的结果
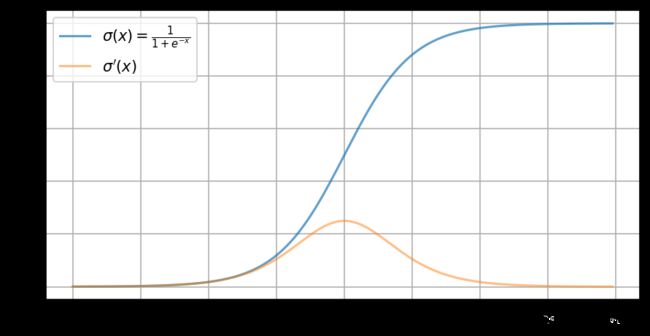
可视化
# visualization
inp = torch.arange(-8, 8, 0.1, requires_grad=True)
out = sigmoid(inp)
out.sum().backward()
inp_grad = inp.grad
plt.plot(inp.detach().numpy(),
out.detach().numpy(),
label=r"$\sigma(x)=\frac{1}{1+e^{-x}} $",
alpha=0.7)
plt.plot(inp.detach().numpy(),
inp_grad.numpy(),
label=r"$\sigma'(x)$",
alpha=0.5)
plt.grid()
plt.legend()
plt.show()