PyTorch搭建GoogLeNet模型(在CIFAR10数据集上准确率达到了85%)
PyTorch搭建GoogLeNet模型
之所以命名为GoogLeNet而不是GoogleNet,是为了致敬为MINST数据集设计的LeNet-5模型,LeNet-5模型在MNIST数据上达到了99%的准确率。
本文的模型在部分层的卷积核、步长、padding参数的设置上有所调整,大体上按照下述模型框架设计的。(图片所示的模型框架是专为ImageNet数据集设计的)
1. 模型构建流程
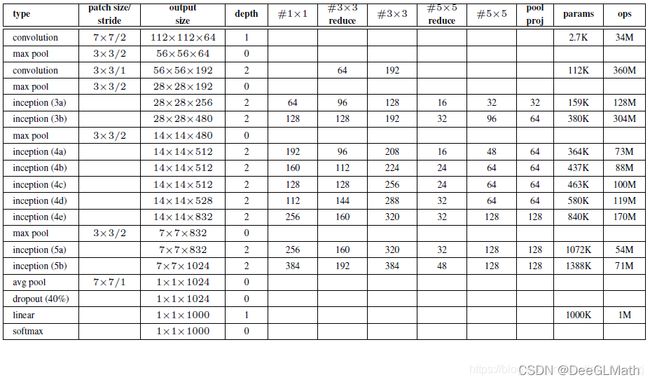
2. 模型各层的对照表
3. Inception结构

4. 完整代码
# import packages
import torch
import torchvision
# Device configuration.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
num_epochs = 40 # To decrease the training time of model.
batch_size = 100
num_classes = 10
learning_rate = 0.0006
# Transform configuration and Data Augmentation.
transform_train = torchvision.transforms.Compose([torchvision.transforms.Pad(2),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(32),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
transform_test = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# Load downloaded dataset.
train_dataset = torchvision.datasets.CIFAR10('data/CIFAR/', download=False, train=True, transform=transform_train)
test_dataset = torchvision.datasets.CIFAR10('data/CIFAR/', download=False, train=False, transform=transform_test)
# Data Loader.
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
*arg 和 **kwargs:https://zhuanlan.zhihu.com/p/50804195
# Define BasicConv2d
class BasicConv2d(torch.nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = torch.nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = torch.nn.BatchNorm2d(out_channels)
self.relu = torch.nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
# Define InceptionAux.
class InceptionAux(torch.nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.avgpool = torch.nn.AvgPool2d(kernel_size=2, stride=2)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
self.fc1 = torch.nn.Sequential(torch.nn.Linear(2 * 2 * 128, 256))
self.fc2 = torch.nn.Linear(256, num_classes)
def forward(self, x):
out = self.avgpool(x)
out = self.conv(out)
out = out.view(out.size(0), -1)
out = torch.nn.functional.dropout(out, 0.5, training=self.training)
out = torch.nn.functional.relu(self.fc1(out), inplace=True)
out = torch.nn.functional.dropout(out, 0.5, training=self.training)
out = self.fc2(out)
return out
# Define Inception.
class Inception(torch.nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = torch.nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1))
self.branch3 = torch.nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2))
self.branch4 = torch.nn.Sequential(torch.nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
(4 - 2 + 2 * 0) / 2 + 1
2.0
# Define GooLeNet.
class GoogLeNet(torch.nn.Module):
def __init__(self, num_classes, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=4, stride=2, padding=3)
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=2, stride=1, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = torch.nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = torch.nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = torch.nn.AdaptiveAvgPool2d((1, 1))
self.dropout = torch.nn.Dropout(0.4)
self.fc = torch.nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 32 x 32
x = self.conv1(x)
# N x 64 x 18 x 18
x = self.maxpool1(x)
# N x 64 x 9 x 9
x = self.conv2(x)
# N x 64 x 9 x 9
x = self.conv3(x)
# N x 192 x 9 x 9
x = self.maxpool2(x)
# N x 192 x 8 x 8
x = self.inception3a(x)
# N x 256 x 8 x 8
x = self.inception3b(x)
# N x 480 x 8 x 8
x = self.maxpool3(x)
# N x 480 x 4 x 4
x = self.inception4a(x)
# N x 512 x 4 x 4
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 4 x 4
x = self.inception4c(x)
# N x 512 x 4 x 4
x = self.inception4d(x)
# N x 528 x 4 x 4
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 4 x 4
x = self.maxpool4(x)
# N x 832 x 2 x 2
x = self.inception5a(x)
# N x 832 x 2 x 2
x = self.inception5b(x)
# N x 1024 x 2 x 2
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 10 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
torch.nn.init.constant_(m.bias, 0)
elif isinstance(m, torch.nn.Linear):
torch.nn.init.normal_(m.weight, 0, 0.01)
torch.nn.init.constant_(m.bias, 0)
# Make model.
model = GoogLeNet(num_classes, False, True).to(device)
# model = GoogLeNet(num_classes, True, True).to(device) # Auxiliary Classifier
# Loss ans optimizer.
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# For updating learning rate.
def update_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# Train the model
import gc
total_step = len(train_loader)
curr_lr = learning_rate
for epoch in range(num_epochs):
gc.collect()
torch.cuda.empty_cache()
model.train()
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# If open the InceptionAux
# (logits, aux_logits2, aux_logits1) = model(images)
# loss0 = criterion(logits, labels)
# loss1 = criterion(aux_logits1, labels)
# loss2 = criterion(aux_logits2, labels)
# loss = loss0 + 0.3 * loss1 + 0.3 * loss2
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Decay learning rate
if (epoch+1) % 20 == 0:
curr_lr /= 3
update_lr(optimizer, curr_lr)
Epoch [1/40], Step [100/500], Loss 1.6228
Epoch [1/40], Step [200/500], Loss 1.5007
Epoch [1/40], Step [300/500], Loss 1.4659
Epoch [1/40], Step [400/500], Loss 1.4783
Epoch [1/40], Step [500/500], Loss 1.1357
Epoch [2/40], Step [100/500], Loss 0.9992
Epoch [2/40], Step [200/500], Loss 1.2076
Epoch [2/40], Step [300/500], Loss 1.1688
Epoch [2/40], Step [400/500], Loss 1.0960
Epoch [2/40], Step [500/500], Loss 0.8147
Epoch [3/40], Step [100/500], Loss 0.9568
Epoch [3/40], Step [200/500], Loss 0.9512
Epoch [3/40], Step [300/500], Loss 1.0539
Epoch [3/40], Step [400/500], Loss 0.7281
Epoch [3/40], Step [500/500], Loss 0.8431
Epoch [4/40], Step [100/500], Loss 0.5680
Epoch [4/40], Step [200/500], Loss 0.6493
Epoch [4/40], Step [300/500], Loss 0.9822
Epoch [4/40], Step [400/500], Loss 0.9635
Epoch [4/40], Step [500/500], Loss 0.7227
Epoch [5/40], Step [100/500], Loss 0.6532
Epoch [5/40], Step [200/500], Loss 0.6582
Epoch [5/40], Step [300/500], Loss 0.6496
Epoch [5/40], Step [400/500], Loss 0.6586
Epoch [5/40], Step [500/500], Loss 0.8176
Epoch [6/40], Step [100/500], Loss 0.6869
Epoch [6/40], Step [200/500], Loss 0.6382
Epoch [6/40], Step [300/500], Loss 0.6537
Epoch [6/40], Step [400/500], Loss 0.6584
Epoch [6/40], Step [500/500], Loss 0.6276
Epoch [7/40], Step [100/500], Loss 0.4683
Epoch [7/40], Step [200/500], Loss 0.6172
Epoch [7/40], Step [300/500], Loss 0.5780
Epoch [7/40], Step [400/500], Loss 0.5502
Epoch [7/40], Step [500/500], Loss 0.5467
Epoch [8/40], Step [100/500], Loss 0.6881
Epoch [8/40], Step [200/500], Loss 0.4092
Epoch [8/40], Step [300/500], Loss 0.5866
Epoch [8/40], Step [400/500], Loss 0.4576
Epoch [8/40], Step [500/500], Loss 0.4820
Epoch [9/40], Step [100/500], Loss 0.4671
Epoch [9/40], Step [200/500], Loss 0.6133
Epoch [9/40], Step [300/500], Loss 0.5239
Epoch [9/40], Step [400/500], Loss 0.6642
Epoch [9/40], Step [500/500], Loss 0.6208
Epoch [10/40], Step [100/500], Loss 0.4827
Epoch [10/40], Step [200/500], Loss 0.4640
Epoch [10/40], Step [300/500], Loss 0.4378
Epoch [10/40], Step [400/500], Loss 0.6229
Epoch [10/40], Step [500/500], Loss 0.5179
Epoch [11/40], Step [100/500], Loss 0.4840
Epoch [11/40], Step [200/500], Loss 0.4091
Epoch [11/40], Step [300/500], Loss 0.3483
Epoch [11/40], Step [400/500], Loss 0.4948
Epoch [11/40], Step [500/500], Loss 0.2806
Epoch [12/40], Step [100/500], Loss 0.5213
Epoch [12/40], Step [200/500], Loss 0.5422
Epoch [12/40], Step [300/500], Loss 0.4831
Epoch [12/40], Step [400/500], Loss 0.5259
Epoch [12/40], Step [500/500], Loss 0.3391
Epoch [13/40], Step [100/500], Loss 0.4835
Epoch [13/40], Step [200/500], Loss 0.3826
Epoch [13/40], Step [300/500], Loss 0.4028
Epoch [13/40], Step [400/500], Loss 0.4639
Epoch [13/40], Step [500/500], Loss 0.4185
Epoch [14/40], Step [100/500], Loss 0.4188
Epoch [14/40], Step [200/500], Loss 0.3471
Epoch [14/40], Step [300/500], Loss 0.3098
Epoch [14/40], Step [400/500], Loss 0.4166
Epoch [14/40], Step [500/500], Loss 0.4801
Epoch [15/40], Step [100/500], Loss 0.4966
Epoch [15/40], Step [200/500], Loss 0.3176
Epoch [15/40], Step [300/500], Loss 0.2048
Epoch [15/40], Step [400/500], Loss 0.3426
Epoch [15/40], Step [500/500], Loss 0.3094
Epoch [16/40], Step [100/500], Loss 0.2408
Epoch [16/40], Step [200/500], Loss 0.3371
Epoch [16/40], Step [300/500], Loss 0.2291
Epoch [16/40], Step [400/500], Loss 0.4520
Epoch [16/40], Step [500/500], Loss 0.2764
Epoch [17/40], Step [100/500], Loss 0.2889
Epoch [17/40], Step [200/500], Loss 0.3893
Epoch [17/40], Step [300/500], Loss 0.4300
Epoch [17/40], Step [400/500], Loss 0.2569
Epoch [17/40], Step [500/500], Loss 0.2740
Epoch [18/40], Step [100/500], Loss 0.2945
Epoch [18/40], Step [200/500], Loss 0.3096
Epoch [18/40], Step [300/500], Loss 0.2456
Epoch [18/40], Step [400/500], Loss 0.2742
Epoch [18/40], Step [500/500], Loss 0.2463
Epoch [19/40], Step [100/500], Loss 0.1934
Epoch [19/40], Step [200/500], Loss 0.2200
Epoch [19/40], Step [300/500], Loss 0.2032
Epoch [19/40], Step [400/500], Loss 0.3054
Epoch [19/40], Step [500/500], Loss 0.3052
Epoch [20/40], Step [100/500], Loss 0.3198
Epoch [20/40], Step [200/500], Loss 0.2043
Epoch [20/40], Step [300/500], Loss 0.3647
Epoch [20/40], Step [400/500], Loss 0.2212
Epoch [20/40], Step [500/500], Loss 0.1774
Epoch [21/40], Step [100/500], Loss 0.1742
Epoch [21/40], Step [200/500], Loss 0.1880
Epoch [21/40], Step [300/500], Loss 0.1749
Epoch [21/40], Step [400/500], Loss 0.2414
Epoch [21/40], Step [500/500], Loss 0.1903
Epoch [22/40], Step [100/500], Loss 0.0815
Epoch [22/40], Step [200/500], Loss 0.0840
Epoch [22/40], Step [300/500], Loss 0.1252
Epoch [22/40], Step [400/500], Loss 0.2355
Epoch [22/40], Step [500/500], Loss 0.1801
Epoch [23/40], Step [100/500], Loss 0.1161
Epoch [23/40], Step [200/500], Loss 0.1108
Epoch [23/40], Step [300/500], Loss 0.1015
Epoch [23/40], Step [400/500], Loss 0.1139
Epoch [23/40], Step [500/500], Loss 0.1588
Epoch [24/40], Step [100/500], Loss 0.1270
Epoch [24/40], Step [200/500], Loss 0.1178
Epoch [24/40], Step [300/500], Loss 0.1644
Epoch [24/40], Step [400/500], Loss 0.1219
Epoch [24/40], Step [500/500], Loss 0.1364
Epoch [25/40], Step [100/500], Loss 0.0894
Epoch [25/40], Step [200/500], Loss 0.0416
Epoch [25/40], Step [300/500], Loss 0.1091
Epoch [25/40], Step [400/500], Loss 0.0897
Epoch [25/40], Step [500/500], Loss 0.1110
Epoch [26/40], Step [100/500], Loss 0.1806
Epoch [26/40], Step [200/500], Loss 0.1066
Epoch [26/40], Step [300/500], Loss 0.1281
Epoch [26/40], Step [400/500], Loss 0.0586
Epoch [26/40], Step [500/500], Loss 0.0412
Epoch [27/40], Step [100/500], Loss 0.0441
Epoch [27/40], Step [200/500], Loss 0.1327
Epoch [27/40], Step [300/500], Loss 0.2291
Epoch [27/40], Step [400/500], Loss 0.1622
Epoch [27/40], Step [500/500], Loss 0.1124
Epoch [28/40], Step [100/500], Loss 0.0657
Epoch [28/40], Step [200/500], Loss 0.1392
Epoch [28/40], Step [300/500], Loss 0.2948
Epoch [28/40], Step [400/500], Loss 0.1069
Epoch [28/40], Step [500/500], Loss 0.0430
Epoch [29/40], Step [100/500], Loss 0.1348
Epoch [29/40], Step [200/500], Loss 0.0936
Epoch [29/40], Step [300/500], Loss 0.1506
Epoch [29/40], Step [400/500], Loss 0.0264
Epoch [29/40], Step [500/500], Loss 0.1103
Epoch [30/40], Step [100/500], Loss 0.0328
Epoch [30/40], Step [200/500], Loss 0.0373
Epoch [30/40], Step [300/500], Loss 0.0803
Epoch [30/40], Step [400/500], Loss 0.0917
Epoch [30/40], Step [500/500], Loss 0.1522
Epoch [31/40], Step [100/500], Loss 0.0370
Epoch [31/40], Step [200/500], Loss 0.1148
Epoch [31/40], Step [300/500], Loss 0.0661
Epoch [31/40], Step [400/500], Loss 0.0637
Epoch [31/40], Step [500/500], Loss 0.2393
Epoch [32/40], Step [100/500], Loss 0.1432
Epoch [32/40], Step [200/500], Loss 0.0670
Epoch [32/40], Step [300/500], Loss 0.1534
Epoch [32/40], Step [400/500], Loss 0.0737
Epoch [32/40], Step [500/500], Loss 0.0523
Epoch [33/40], Step [100/500], Loss 0.0312
Epoch [33/40], Step [200/500], Loss 0.0768
Epoch [33/40], Step [300/500], Loss 0.0540
Epoch [33/40], Step [400/500], Loss 0.0678
Epoch [33/40], Step [500/500], Loss 0.0810
Epoch [34/40], Step [100/500], Loss 0.1169
Epoch [34/40], Step [200/500], Loss 0.0748
Epoch [34/40], Step [300/500], Loss 0.0773
Epoch [34/40], Step [400/500], Loss 0.0415
Epoch [34/40], Step [500/500], Loss 0.0752
Epoch [35/40], Step [100/500], Loss 0.0430
Epoch [35/40], Step [200/500], Loss 0.0956
Epoch [35/40], Step [300/500], Loss 0.0386
Epoch [35/40], Step [400/500], Loss 0.0273
Epoch [35/40], Step [500/500], Loss 0.0358
Epoch [36/40], Step [100/500], Loss 0.0961
Epoch [36/40], Step [200/500], Loss 0.0075
Epoch [36/40], Step [300/500], Loss 0.0848
Epoch [36/40], Step [400/500], Loss 0.0240
Epoch [36/40], Step [500/500], Loss 0.0349
Epoch [37/40], Step [100/500], Loss 0.1203
Epoch [37/40], Step [200/500], Loss 0.0422
Epoch [37/40], Step [300/500], Loss 0.0276
Epoch [37/40], Step [400/500], Loss 0.0475
Epoch [37/40], Step [500/500], Loss 0.0345
Epoch [38/40], Step [100/500], Loss 0.0540
Epoch [38/40], Step [200/500], Loss 0.0615
Epoch [38/40], Step [300/500], Loss 0.0584
Epoch [38/40], Step [400/500], Loss 0.0357
Epoch [38/40], Step [500/500], Loss 0.0734
Epoch [39/40], Step [100/500], Loss 0.0697
Epoch [39/40], Step [200/500], Loss 0.0483
Epoch [39/40], Step [300/500], Loss 0.1183
Epoch [39/40], Step [400/500], Loss 0.0415
Epoch [39/40], Step [500/500], Loss 0.1576
Epoch [40/40], Step [100/500], Loss 0.0091
Epoch [40/40], Step [200/500], Loss 0.0561
Epoch [40/40], Step [300/500], Loss 0.0736
Epoch [40/40], Step [400/500], Loss 0.0255
Epoch [40/40], Step [500/500], Loss 0.1081
# Test the mdoel.
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the model on the test images: {} %'.format(100 * correct / total))
Accuracy of the model on the test images: 85.88 %
# Accuracy of the model on the test images: 86.69 %
# Save the model checkpoint.
torch.save(model.state_dict(), 'GoogLeNet.ckpt')
# torch.save(model.state_dict(), 'GoogLeNet(Aux).ckpt')