【机器学习】KNN算法实战项目三:金融贷款策略分类
KNN算法实战项目三:金融贷款策略分类
- 3 金融贷款策略中的KNN分类
-
- 3.1 模块导入与数据加载
- 3.2 数据EDA
-
- 3.2.1 数据预处理
- 3.2.2 数据可视化
- 3.2.3 特征工程
- 3.3 模型创建与应用
- 3.4 模型对比
手动反爬虫: 原博地址 https://blog.csdn.net/lys_828/article/details/122630788
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
3 金融贷款策略中的KNN分类
3.1 模块导入与数据加载
导入常用模块以及忽略警告提醒
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
import matplotlib
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
加载借贷数据集
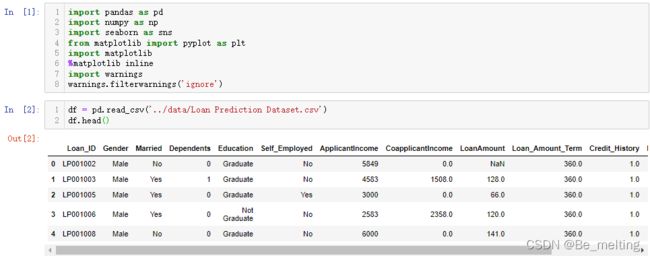
df = pd.read_csv('../data/Loan Prediction Dataset.csv')
df.head()
输出结果如下。
3.2 数据EDA
3.2.1 数据预处理
首先查看各字段的基本详情,以及数值字段的分布情况,通过info和describe方法进行,代码及输出结果如下。

通过info方法可以看到有些字段是存在着缺失值,然后对比describe就可以知道哪些是连续字段,哪些是分类字段。
进一步可以查看各字段的缺失值情况,代码及输出结果如下。
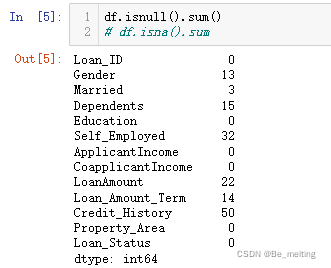
对于分类任务首先要知道标签字段,这里就应对着Credit_History字段,可以通过unique方法进行分类情况查询。其中1标签贷款违约,0代表着未违约。

缺失值处理。缺失值的处理需要根据缺失值数量占总体样本的比例决定,如果缺失数据达到10%以上,最好用修复的方式解决;如果占比小于3%,可以直接忽略。此外数据修复时,针对连续型数据,一般采用平均值的方式填充,分类数据一般采用众数填充。
(1)先解决连续型数据的缺失值问题。首先需要知道一下总体样本的数量,很多方式都可以获取,比如通过shape或者len都可以,代码及输出结果如下。

采用均值的方式进行填充,获取均值的方式直接通过mean的方式,以LoanAmount字段为例,代码如下。
df.LoanAmount.mean()
df.LoanAmount=df.LoanAmount.fillna(df.LoanAmount.mean())
df.isna().sum()
输出结果如下。

剩余数值字段的处理方式一致,代码及输出结果如下。

(2)再处理分类字段的数据。获取众数的方式可以使用mode方法,比如获取性别中众数,代码如下。
df['Gender'].mode()[0]
df['Gender'].value_counts()
输出结果如下。可以通过value_counts的方法进行核实,Male属于数量较多的一类。

按照此方式进行其余分类字段的处理,代码如下。
df['Gender'] = df["Gender"].fillna(df['Gender'].mode()[0])
df['Married'] = df["Married"].fillna(df['Married'].mode()[0])
df['Dependents'] = df["Dependents"].fillna(df['Dependents'].mode()[0])
df['Self_Employed'] = df["Self_Employed"].fillna(df['Self_Employed'].mode()[0])
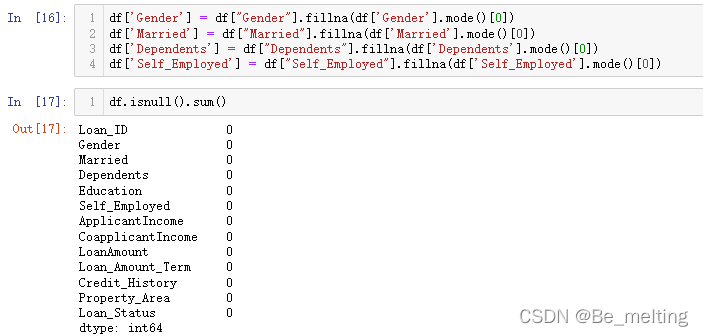
df.isnull().sum()
输出结果如下。最后所有的字段均处理完毕。
3.2.2 数据可视化
(1)分类字段。可以快速使用countplot方法进行绘制,总共有七个分类字段,可以依次进行绘图。
a)性别字段计数统计,代码及输出结果如下。男性来做信贷的人比女性高4倍左右。

b)婚姻字段计数统计,代码及输出结果如下。结婚的比例是未婚的一倍。

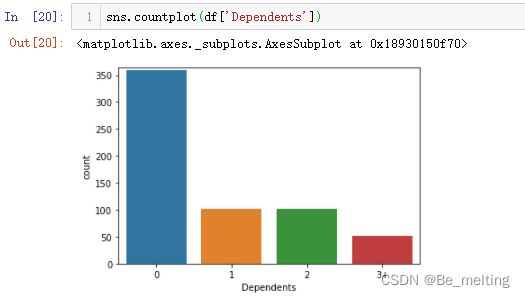
c)家属人数字段计数统计,代码及输出结果如下。单身人员最多。
d)教育水平字段计数统计,代码及输出结果如下。教育程度高的借款比例高。
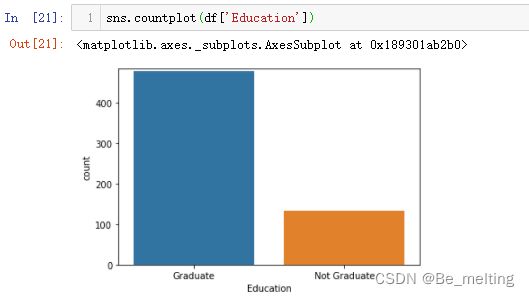
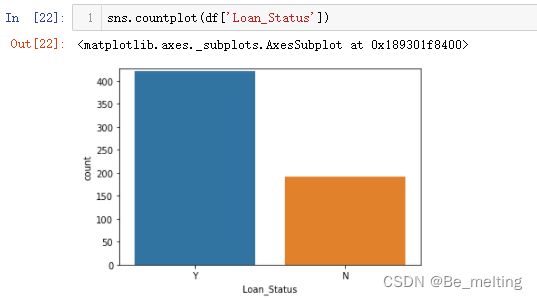
e)借贷状态字段计数统计,代码及输出结果如下。被批准的贷款数量要比未批准的一倍还多。
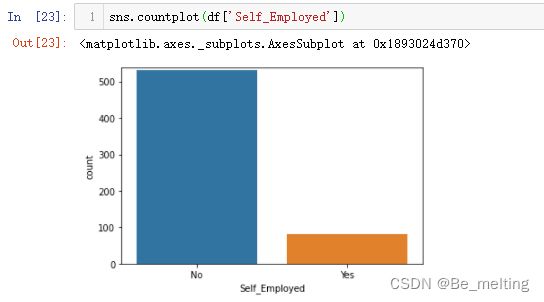
f)是否为自营者字段计数统计,代码及输出结果如下。其中上班的人员要远高于自营者。
g)人员所属地区字段计数统计,代码及输出结果如下。城镇人员、农村人员以及城乡结合部人员分布较为平均。

(2)连续字段。用于可视化展示的方式较多,比如绘制直方图,散点图、密度图以及箱型图等。案例中一共有五个连续字段,依次进行数据可视化。
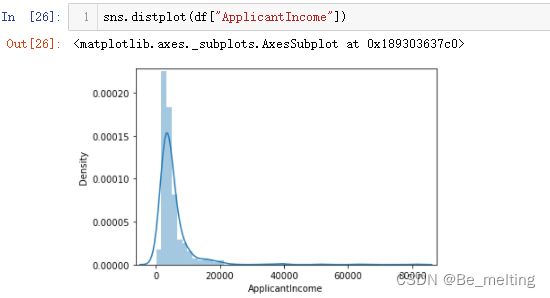
a)申请人工资情况分布,代码及输出结果如下。主体人员的收入都是在1万以内的,其它范围的收入人员很少。

除了直方图也可以借助密度图进行展示,直接使用distplot方法即可。注意对比两图的y轴的刻度范围,上面的是频数,下面的是百分比。
b)家庭其他人员收入情况分布,代码及输出结果如下。
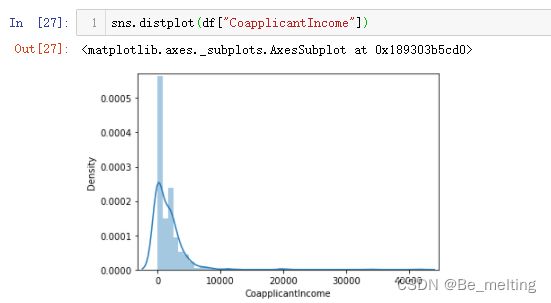
c)借贷金额情况分布,代码及输出结果如下。峰值是在10万左右,注意x轴的单位是千。

d)借款周期情况分布,代码及输出结果如下。存在两个高峰,一个是160-180(10年贷款期限),还有一个是360-380(30年贷款期限)。

e)借贷人员比例情况分布,代码及输出结果如下。其中绝大部分人员是接过贷款,还有一部分人员是未借过。

3.2.3 特征工程
对于申请人收入和家庭其余人员收入字段可以进行合并成为总收入,代码如下。
df['Total_Income'] = df['ApplicantIncome'] + df['CoapplicantIncome']
df.head()
输出结果如下。

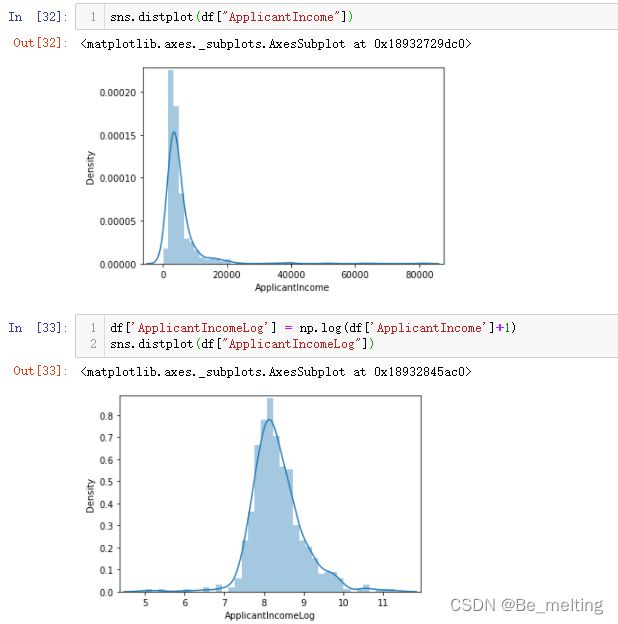
除了新增字段外,对于一些偏态的数据字段也需要进行对数转化,常常使用处理方式为log(x+1),代码如下。
sns.distplot(df["ApplicantIncome"])
df['ApplicantIncomeLog'] = np.log(df['ApplicantIncome']+1)
sns.distplot(df["ApplicantIncomeLog"])
输出结果如下。经过转化后,数据分布呈现出正态分布的趋势。
对于剩余偏态分布的字段也可以采用同样的方式处理,代码及输出结果如下。

接下来可以使用热力图查看关联关系,代码如下。
corr = df.corr()
plt.figure(figsize=(15,10))
sns.heatmap(corr, annot = True, cmap="BuPu")
输出结果如下。

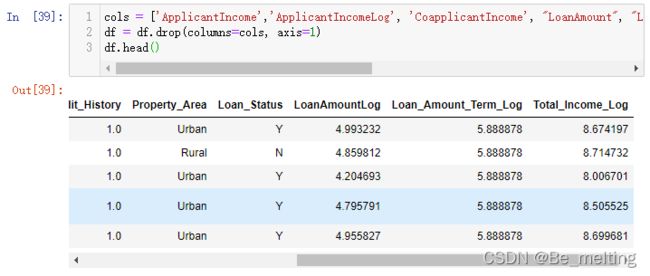
然后就可以删除一些不必要的字段,有了总收入后,就可以删除申请者收入与家庭其他人员收入字段,保留经过对数转化后的字段,代码如下。
cols = ['ApplicantIncome','ApplicantIncomeLog', 'CoapplicantIncome', "LoanAmount", "Loan_Amount_Term", "Total_Income", 'Loan_ID', 'CoapplicantIncomeLog']
df = df.drop(columns=cols, axis=1)
df.head()
输出结果如下。
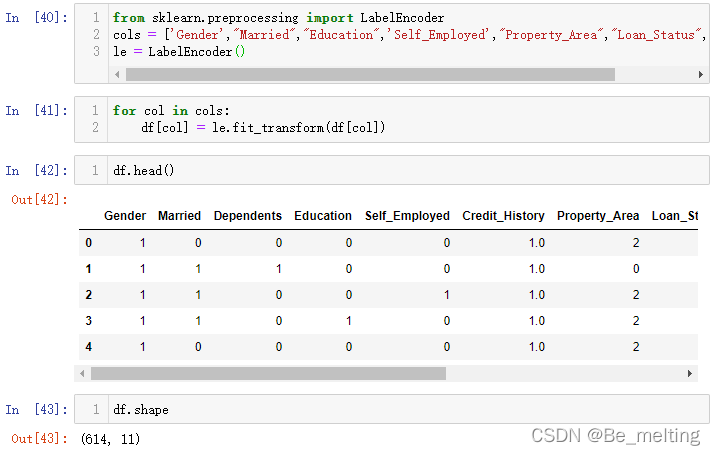
连续数据偏态经过对数转换,那么对于分类数据就需要进行编码花处理,代码如下。
from sklearn.preprocessing import LabelEncoder
cols = ['Gender',"Married","Education",'Self_Employed',"Property_Area","Loan_Status","Dependents"]
le = LabelEncoder()
for col in cols:
df[col] = le.fit_transform(df[col])
df.head()
df.shape
输出结果如下。
至此整个数据EDA的过程就全部结束,接下来就是进行数据建模。
3.3 模型创建与应用
划分特征数据和标签数据,训练集和测试集。
X = df.drop(columns=['Loan_Status'], axis=1)
y = df['Loan_Status']
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
输出结果如下。

创建模型与模型评估,代码如下。
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(x_train, y_train)
print("Accuracy is", model.score(x_test, y_test)*100)
输出结果如下。

3.4 模型对比
模型的好坏可以通过多个模型pk结果进行判断好坏。为了方便模型的创建和评估,可以将流程封装为函数,代码如下。
def classify(model, x, y):
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model.fit(x_train, y_train)
print("Accuracy is", model.score(x_test, y_test)*100)
score = cross_val_score(model, x, y, cv=5)
print("Cross validation is",np.mean(score)*100)
输出结果如下。

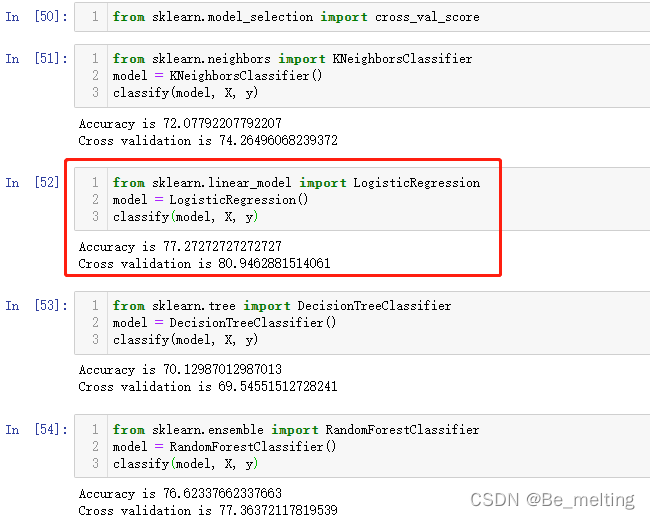
然后以四个分类模型进行对比:KNN、逻辑回归、决策树、随机森林,代码如下。
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
classify(model, X, y)
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
classify(model, X, y)
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
classify(model, X, y)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
classify(model, X, y)
输出结果如下。当前数据最合适的模型是逻辑回归。
除了模型之间的对比,也可以通过调整KNN中的K值,来比较不同K值下的模型评估,具体的方式在项目二中有详细介绍,可以尝试实现。