ImageNet数据集用法
1. 数据下载
1.1 方法一:官网下载
ImageNetwww.image-net.org/
在官方网站注册账号,注册时最好使用教育邮箱(.edu )之后。按照流程申请,收到邮件之后可以就可以在 Download界面里下数据啦~
推荐下载12年的数据,因为比较经典。不如果你如果凑巧财力雄厚,也可以考虑最顶上那个ImageNet21k,它相比12年的数据大的离谱。
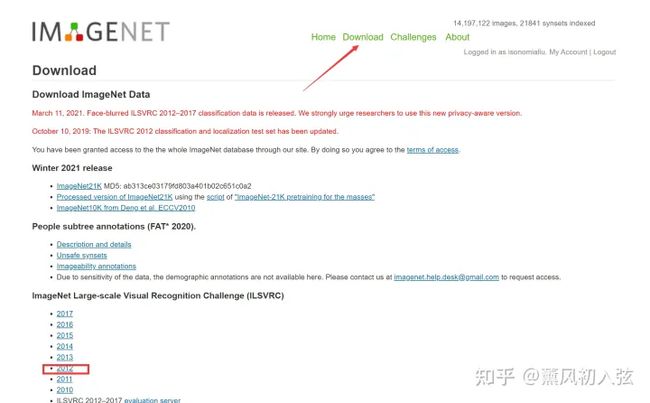
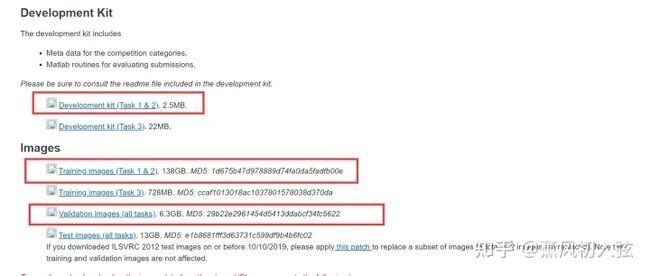
点进去之后,下载如下三个压缩包(图片分类任务用这三个足够了)
1.2 方法二
如果你觉得这么下不方便/网速太慢容易断,可以在这个网址自行找12年的版本下载(别全下了呀)
ImageNet 10 图像识别数据集 - 数据集下载 - 超神经hyper.ai/datasets/4889
2. 数据解压
下载完毕后把 Development kit 留着备用,我们会得到训练集与验证集的两个压缩包,分别是 ILSVRC2012_img_train.tar 和 ILSVRC2012_img_val.tar。
首先创建两个用于放训练集和测试集的文件夹,然后解压:
mkdir train
mkdir val
tar xvf ILSVRC2012_img_train.tar -C ./train
tar xvf ILSVRC2012_img_val.tar -C ./val对于train的压缩包,解压之后其实还是1000个tar压缩包(对应1000个类别),需要再次解压,解压脚本unzip.sh如下(PS:可能需要自己改一下目录 dir ):
dir=./train
for x in `ls $dir/*tar` do
filename=`basename $x .tar`
mkdir $dir/$filename
tar -xvf $x -C $dir/$filename
done
rm *.tar执行脚本之后,我们就获得了1000个文件夹和对应的图片数据啦~截至目前,我们已经把所有的 JPEG 图片搞了出来。
3. 数据标签
对于训练集,不同类别的数据躺在不同的文件夹里,用起来很方便(同一文件夹的视为一类)。但是验证集没有对应的标签,需要额外处理。
验证集的标签在 Development kit (文件名为 ILSVRC2012_devkit_t12.tar.gz)中的ILSVRC2012_devkit_t12\data\ILSVRC2012_validation_ground_truth.txt 中:

但是新的问题又来了,那就是这个数字和文件夹的名字虽然是一一对应的,但还是需要额外的映射……好在映射关系储存在和txt文件同目录下的 meta.mat 文件中。我们希望验证集的文件结构长得和训练集一样,即 :
- /val
- /n01440764
- images
- /n01443537
- images
- /n01440764
因此,我们首先解压 devkit 压缩包,把我们需要的东西取出来:
tar -xzf ILSVRC2012_devkit_t12.tar.gz
之后,在imagenet目录(devkit和val的根目录下)创建并运行如下 python 脚本
from scipy import io
import os
import shutil
def move_valimg(val_dir='./val', devkit_dir='./ILSVRC2012_devkit_t12'):
"""
move valimg to correspongding folders.
val_id(start from 1) -> ILSVRC_ID(start from 1) -> WIND
organize like:
/val
/n01440764
images
/n01443537
images
.....
"""
# load synset, val ground truth and val images list
synset = io.loadmat(os.path.join(devkit_dir, 'data', 'meta.mat'))
ground_truth = open(os.path.join(devkit_dir, 'data', 'ILSVRC2012_validation_ground_truth.txt'))
lines = ground_truth.readlines()
labels = [int(line[:-1]) for line in lines]
root, _, filenames = next(os.walk(val_dir))
for filename in filenames:
# val image name -> ILSVRC ID -> WIND
val_id = int(filename.split('.')[0].split('_')[-1])
ILSVRC_ID = labels[val_id-1]
WIND = synset['synsets'][ILSVRC_ID-1][0][1][0]
print("val_id:%d, ILSVRC_ID:%d, WIND:%s" % (val_id, ILSVRC_ID, WIND))
# move val images
output_dir = os.path.join(root, WIND)
if os.path.isdir(output_dir):
pass
else:
os.mkdir(output_dir)
shutil.move(os.path.join(root, filename), os.path.join(output_dir, filename))
if __name__ == '__main__':
move_valimg()
4. 用Pytorch加载
使用 torchvision.datasets.ImageFolder() 就可以直接加载处理好的数据集啦!
import os
import torch
import torchvision.datasets as datasets
root = 'data/imagenet'
def get_imagenet(root, train = True, transform = None, target_transform = None):
if train:
root = os.path.join(root, 'train')
else:
root = os.path.join(root, 'val')
return datasets.ImageFolder(root = root,
transform = transform,
target_transform = target_transform)