【翻译】Robust High-Resolution Video Matting with Temporal Guidance

Robust High-Resolution Video Matting with Temporal Guidance 论文地址
RobustVideoMatting 代码地址
论文阅读笔记
版权声明:本文为CSDN博主「Kaleidoscope-」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_45929156/article/details/128537177
0. 摘要
我们介绍了一种强大的、实时的、高分辨率的人类视频消光方法,实现了新的最先进的性能。我们的方法比以前的方法要轻得多,可以在Nvidia GTX 1080Ti GPU上以76 FPS的速度处理4K,以104 FPS的速度处理高清。与大多数现有的将视频逐帧作为独立图像进行消融的方法不同,我们的方法使用了一个递归架构来利用视频中的时间信息,并在时间一致性和消融质量方面取得了明显的改善。此外,我们提出了一种新的训练策略,使我们的网络在消光和分割目标上都得到加强。这极大地提高了我们模型的稳健性。我们的方法不需要任何辅助输入,如修剪图或预先捕获的背景图像,因此它可以广泛地应用于现有的人类消光应用。我们的代码可在https://peterl1n.github.io/RobustVideoMatting/这里获得。
1. 介绍
消光是指从输入帧中预测α消光和前景颜色的过程。从形式上看,一帧I可以被看作是前景F和背景B通过α系数的线性组合。
I = α F + ( 1 − α ) B ( 1 ) I = αF+(1-α)B \qquad(1) I=αF+(1−α)B(1)
通过提取α和F,我们可以将前景物体合成一个新的背景,达到背景替换的效果。
背景替换有许多实际应用。许多正在兴起的用例,如视频会议和娱乐视频创作,都需要在没有绿幕道具的情况下对人类主体进行实时的背景替换。神经模型被用于这个具有挑战性的问题,但目前的解决方案并不总是稳健的,而且经常产生伪影。我们的研究重点是提高此类应用的垫层质量和稳健性。
大多数现有的方法[18, 22, 34],尽管是为视频应用而设计的,但将单个帧作为独立的图像来处理。这些方法忽略了视频中最广泛存在的特征:时间信息。时间信息可以改善视频的消光性能,原因有很多。首先,它允许预测更连贯的结果,因为模型可以看到多个帧和它自己的预测结果。这大大减少了瑕疵,提高了感知质量。第二,时间信息可以提高消光的稳健性。在个别帧可能是模糊的情况下,例如,前景颜色变得与背景中的一个经过的物体相似,模型可以通过参考以前的帧来更好地猜测边界。第三,时间信息允许模型随着时间的推移了解更多关于背景的信息。当相机移动时,由于视角的变化,被摄者背后的背景就会显现出来。即使摄像机被固定住了,被遮挡的背景仍然经常由于被摄者的移动而显现出来。对背景有一个更好的了解可以简化消光任务。因此,我们提出了一个循环架构来利用时间信息。我们的方法极大地提高了消光质量和时间一致性。它可以应用于所有的视频,而不需要任何辅助输入,如手动注释的三段式或预先拍摄的背景图像。
此外,我们提出了一个新的训练策略,以同时在消光和语义分割目标上执行我们的模型。大多数现有的方法[18, 22, 34]是在合成垫子数据集上训练的。这些样本通常看起来是假的,并阻止了网络对真实图像的推广。以前的工作[18, 22]试图用分割任务训练的权重来初始化模型,但模型在垫层训练中仍然过度到合成分布。还有一些人尝试在无标签的真实图像上进行对抗性训练[34]或半监督学习[18],作为额外的适应步骤。我们认为,人类的消解任务与人类的分割任务密切相关。同时进行分割目标的训练可以有效地调节我们的模型,而无需额外的适应步骤。
我们的方法优于之前最先进的方法,同时更轻更快。我们的模型只使用了58%的参数,并能在Nvidia GTX 1080Ti GPU上以4K 76 FPS和HD 104 FPS的速度实时处理高分辨率视频。
2. 相关工作
基于Trimap的 matting。 经典的(非学习型)算法[1, 5, 7, 10, 20, 21, 38]需要手动的trimap注释来解决trimap的未知区域。这类方法在Wang和Cohen的调查中有所回顾[43]. Xu等人[45]首次将一个深度网络用于基于trimap的消解,最近的许多研究继续采用这种方法。FBA[9]是其中一个最新的研究。基于Trimap的方法通常是与物体无关的(不限于人类)。它们适合于交互式照片编辑应用,用户可以选择目标对象并提供人工指导。为了将其扩展到视频,Sun等人提出了DVM[39],它只需要在第一帧上进行修剪,并能将其传播到视频的其余部分。
基于背景的消光。 Soumyadip等人提出了背景消光(BGM)[34],它需要一个额外的预先捕获的背景图像作为输入。这种信息作为一种隐含的方式来选择前景,并提高了消隐的准确性。Lin和Ryabtsev等人进一步提出了BGMv2[22],改进了性能,并将重点放在实时高分辨率上。然而,背景消融不能处理动态背景和大型摄像机的移动。
分割。 语义分割是为每个像素预测一个类别标签,通常没有辅助输入。其二元分割掩码可用于定位人类主体,但直接使用它进行背景替换将导致强烈的伪影。尽管如此,分割任务与无辅助设置中的消光任务类似,分割方面的研究启发了我们的网络设计。DeepLabV3[3]提出了ASPP(Atrous Spatial Pyramid Pooling)模块,并在其编码器中使用扩张卷积来提高性能。这一设计被许多后续作品所采用,包括MobileNetV3[15],它将ASPP简化为LR-ASPP。
无辅助的消光。 没有任何辅助输入的全自动消光也已被研究。像[29, 46]这样的方法适用于任何前景物体,但不太稳健,而像[18, 35, 47]这样的方法是专门为人像训练的。MODNet[18]是最新的人像消融方法。相比之下,我们的方法是经过训练的,可以很好地在整个人体上工作。
视频矩阵。 很少有神经消融方法是为视频设计的。MODNet[18]提出了一个后处理技巧,即比较相邻帧的预测来抑制抖动,但它不能处理快速移动的身体部分,而且模型本身仍然将帧作为独立的图像来操作。BGM[34]探讨了将几个相邻的帧作为额外的输入通道,但这只提供短期的时间线索,其效果不是研究的重点。DVM[45]是视频原生的,但专注于利用时间信息来传播trimap注释。相反,我们的方法专注于利用时间信息来提高无辅助设置中的消光质量。
递归结构。 递归神经网络已被广泛用于序列任务。两个最流行的架构是LSTM(长短时记忆)[13]和GRU(门控递归单元)[6],它们也被采用于视觉任务,如ConvLSTM[36]和ConvGRU[2]。以前的工作已经探索了在各种视频视觉任务中使用递归架构,并显示了与基于图像的对应物相比的改进性能[42, 28, 41]。我们的工作采用了递归架构来处理消光任务。
高分辨率消融。 PointRend[19]的分割和BGMv2[22]的消光已经探索了基于补丁的重新整合。它只对选择性的斑块进行卷积。另一种方法是使用引导滤波[11],这是一种后处理滤波器,以高分辨率帧为指导,对低分辨率预测进行联合升采样。深度引导滤波(DGF)[44]是作为一个可学习的模块提出的,它可以和网络一起进行端到端的训练,而不需要手动超参数。尽管基于滤波器的上采样功能较弱,但我们还是选择了它,因为它的速度更快,而且得到了所有推理框架的支持。
3. 模型结构
我们的架构包括一个提取单个帧特征的编码器,一个汇总时间信息的递归解码器,以及一个用于高分辨率上采样的深度引导滤波器模块。图2显示了我们的模型架构。
3.1. Feature-Extraction Encoder(特征提取编码器)
我们的编码器模块遵循最先进的语义分割网络的设计[3, 4, 15],因为准确定位人像主体的能力是垫层任务的基础。我们采用MobileNetV3-Large[15]作为我们高效的主干,然后采用MobileNetV3提出的LR-ASPP模块来完成语义分割任务。值得注意的是,MobileNetV3的最后一个模块使用了扩张的卷积,没有下采样的步长。编码器模块对单个帧进行操作,并在 1 2 1\over 2 21、 1 4 1\over4 41、 1 8 1\over8 81、 1 16 1\over16 161尺度上提取特征,供递归解码器使用。

图2:我们的网络由一个特征提取编码器、一个递归解码器和深度引导滤波(DGF)模块组成。为了处理高分辨率的视频,首先对编码器-解码器网络的输入进行降采样,然后用DGF对结果进行升采样。
3.2. Recurrent Decoder(递归解码器)
我们决定使用一个递归结构,而不是使用注意力或简单的前馈多帧作为额外的输入通道,有几个原因。递归机制可以学习在连续的视频流中保留和遗忘哪些信息,而其他两种方法必须依靠一个固定的规则,在每个设定的时间间隔内删除旧的和插入新的信息到有限的内存池中。适应性地保留长期和短期时间信息的能力使递归机制更适合于我们的任务。
我们的解码器采用了多尺度的ConvGRU来聚合时间信息。我们选择ConvGRU是因为它比ConvLSTM的门数更少,参数更有效。从形式上看,ConvGRU被定义为。

其中,运算符∗和⊙分别代表卷积和元正积;tanh和σ分别代表双曲切线和sigmoid函数。w和b是卷积核和偏置项。隐藏状态h t既作为输出,也作为下一个时间步骤的递归状态h t-1。初始递归状态h 0是一个全零张量。
如图2所示,我们的解码器由一个瓶颈块、上采样块和一个输出块组成。
Bottleneck block(瓶颈块) 在LR-ASPP模块之后以 1 16 1\over16 161的特征尺度运行。一个ConvGRU层只对一半的通道进行分割和串联操作。这大大减少了参数和计算,因为ConvGRU的计算量很大。
Upsampling block(上采样块) 在 1 8 1\over8 81、 1 4 1\over4 41 和 1 2 1\over2 21比例上重复。首先,它将前一模块的双线性升采样输出、编码器的相应比例的特征图和通过重复2×2平均池化降采样的输入图像连接起来。然后,在卷积之后,应用批量归一化[16]和ReLU[26]激活来进行特征合并和通道减少。最后,通过分割和串联对一半的通道应用ConvGRU。
Output block(输出块) 不使用ConvGRU,因为我们认为它在这个规模上是膨胀的,没有影响。该模块只使用常规的卷积法来重构结果。它首先将输入图像和前一个块的双线性升采样输出连接在一起。然后,它采用两次重复卷积、批量归一化和ReLU堆栈来产生最终的隐藏特征。最后,这些特征被投射到输出,包括单通道阿尔法预测、三通道前景预测和单通道分割预测。分割输出被用于分割训练目标,如后面第4节所述。
我们发现,通过分割和串联,将ConvGRU应用于一半的通道是有效和高效的。这种设计有助于ConvGRU专注于聚集时间信息,而另一个分割分支则转发了当前帧的空间特征。所有的卷积都使用3×3的内核,除了最后的投影使用1×1的内核。
我们修改了我们的网络,使其可以一次获得T个框架作为输入,每一层在传递到下一层之前都要处理所有的T个框架。在训练过程中,这使得批量归一化可以计算跨批次和时间的统计数据,以确保归一化的一致性。在推理过程中,T=1可用于处理实时视频,T>1可用于利用非递归层的更多GPU并行性,作为批处理的一种形式,如果允许帧被缓冲。我们的递归解码器是单向的,所以它可以用于直播和后期处理。
3.3. Deep Guided Filter Module(深度导引过滤模块)
我们采用[44]中提出的深度引导滤波(DGF)进行高分辨率预测。在处理4K和高清等高分辨率视频时,我们在通过编码器-解码器网络之前对输入帧进行降采样,降采样系数为s。然后,低分辨率的阿尔法、前景、最终的隐藏特征,以及高分辨率的输入帧被提供给DGF模块,以产生高分辨率的阿尔法和前景。如第4节所述,整个网络是端到端的训练。请注意,DGF模块是可选的,如果要处理的视频分辨率低,编码器-解码器网络可以独立运行。
我们的整个网络不使用任何特殊的运算符,可以部署到大多数现有的推理框架。更多的架构细节在补充文件中。
4. 训练
我们建议同时用消光和语义分割的目标来训练我们的网络,这有几个原因。
首先,人类消解任务与人类分割任务密切相关。不像基于trimap和基于背景的消光方法,它们被赋予额外的线索作为输入,我们的网络必须学会从语义上理解场景,并在定位人类主体方面具有鲁棒性。
第二,大多数现有的消光数据集只提供地面真实的阿尔法和前景,必须对背景图像进行合成。由于前景和背景具有不同的照明,这些合成有时看起来很假。另一方面,语义分割数据集的特点是真实的图像,其中人类主体包括在所有类型的复杂场景中。用语义分割数据集进行训练可以防止我们的模型过度适应合成分布。
第三,有更多的训练数据可用于语义分割任务。我们收获了各种公开可用的数据集,包括基于视频和图像的数据集,以训练一个强大的模型。
4.1. Matting Datasets(配套数据集)
我们的模型是在VideoMatte240K(VM)[22]、Distinctions-646(D646)[30]和Adobe Image Matting(AIM)[45]数据集中训练的。VM提供了484个4K/HD视频片段。我们将数据集分为475/4/5个片段,用于训练/评估/测试的分割。D646和AIM是图像矩阵数据集。我们只使用人类的图像,并将它们结合起来,形成420/15个训练/评价分片,用于训练。为了评估,D646和AIM分别提供11张和10张测试图像。
对于背景,[39]的数据集提供了适合于消光合成的高清背景视频。这些视频包括各种运动,如汽车通过、树叶摇晃和摄像机运动。我们选择了3118个不包含人类的片段,并从每个片段中提取前100帧。我们还按照[22]的方法抓取了8000张图像背景。这些图像有更多的室内场景,如商店和客厅。
我们对前景和背景都进行了运动和时间上的增强,以增加数据的多样性。运动增强包括随时间不断变化的平移、缩放、旋转、剪切、亮度、饱和度、对比度、色调、噪声和模糊。运动的应用有不同的缓和功能,这样的变化并不总是线性的。扩增也为图像数据集增加了人工运动。此外,我们还在视频上应用了时间上的增强,包括片段逆转、速度变化、随机暂停和跳帧。其他的离散增强,即水平flip、灰度和锐化,也被一致地应用于所有帧。
4.2. Segmentation Datasets(分割数据集)
我们使用视频分割数据集YouTubeVIS并选择2985个包含人类的片段。我们还使用图像分割数据集COCO[23]和SPD[40]。COCO提供了64111张包含人类的图像,而SPD提供了额外的5711张样本。我们应用了类似的增强,但没有运动,因为YouTubeVIS已经包含了大量的摄像机运动,而图像分割数据集不需要运动增强。
4.3. Procedures(流程)
我们的消解训练被分成四个阶段。它们被设计成让我们的网络逐步看到更长的序列和更高的分辨率,以节省训练时间。我们使用亚当优化器进行训练。所有阶段都使用批处理大小B=4,分在4个Nvidia V100 32G GPU上。
- 第一阶段:我们首先在低分辨率的虚拟机上训练,没有DGF模块15个epochs。我们设置了一个短的序列长度T=15帧,这样网络就能更快地得到更新。MobileNetV3骨干网用预训练的ImageNet[32]权重初始化,并使用1e-4的学习率,而网络的其他部分使用2e-4。我们在256和512像素之间对输入分辨率h、w的高度和宽度独立采样。这使得我们的网络对不同的分辨率和长宽比具有鲁棒性。
- 第二阶段:我们将T增加到50帧,将学习率降低一半,并保持第一阶段的其他设置,再训练我们的模型2个 epochs。这使我们的网络能够看到更长的序列并学习长期的依赖性。T = 50是我们在GPU上可以训练的最长时间。
- 第三阶段:我们安装DGF模块,在虚拟机上用高分辨率的样本训练1个历时。由于高分辨率会消耗更多的GPU内存,所以序列长度必须被设置为非常短。为了避免我们的循环网络对非常短的序列过度,我们在低分辨率长序列和高分辨率短序列上训练我们的网络。具体来说,低分辨率通道不采用DGF,并且有T=40和h,w∼(256,512)。高分辨率通道包含了低分辨率通道,并采用了DGF的下采样系数s = 0.25,T = 6,h, wˆ ∼ (1024, 2048) 。我们将DGF的学习率设置为2e-4,网络的其他部分设置为1e-5。
- 第四阶段:我们在D646和AIM的组合数据集上训练了5个历时。我们将解码器的学习率提高到5e-5,让我们的网络适应,并保持第三阶段的其他设置。
- 分割:我们的分割训练是在每个消光训练迭代之间交错进行的。我们在每次奇数迭代后对图像分割数据进行训练,而在每次偶数迭代后对视频分割数据进行训练。分割训练适用于所有阶段。对于视频分割数据,我们在每个消解阶段使用相同的B、T、h、w设置。对于图像分割数据,我们将其视为只有1帧的视频序列,因此T′=1。这使我们有空间应用更大的批量大小B ′ = B ×T。由于图像是作为第一帧的前馈,所以即使在没有递归信息的情况下,它也能迫使分割变得稳健。
4.4. 损失
(这里我放一下论文原稿,如果对翻译有疑问,可以直接对应原文检查,欢迎读者指正翻译不准确的地方)
我们对所有t∈[1, T]帧应用损失。为了学习前景概率 α t α_t αt和真实前景 α t ∗ α_t^* αt∗,我们使用L1损失 L l 1 α L^α_{l1} Ll1α和金字塔拉普拉斯损失 L l a p α L_{lap}^α Llapα,如[9,14]所报告的,以产生最佳结果。我们还应用了时间一致性损失 L t c α L_{tc}^α Ltcα,如[39]所使用的,以减少干扰。

为了学习前景 F t F_t Ft与前景 F t ∗ F_t^∗ Ft∗,我们按照[22]的方法,在 α t ∗ > 0 α_t^∗>0 αt∗>0的像素上计算L1损失 L l 1 F L_{l1}^F Ll1F和时间一致性损失 L t c F L_{tc}^F LtcF。

垫层总损失 L M L^M LM为:

对于语义分割,我们的网络只对人像类别进行训练。为了学习分割概率 S t S_t St与基础事实二元标签 S t ∗ S_t^∗ St∗的关系,我们计算二元交叉熵损失。
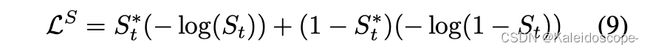
5. 实验评估
5.1. 对组成数据集的评价
我们通过将VM、D646和AIM数据集的每个测试样本合成到5个视频和5个图像背景中来构建我们的基准。每个测试片段有100帧。图像样本被应用于运动增强。
我们将我们的方法与最先进的基于三角图的方法(FBA[9])、基于背景的方法(BGMv2[22]与MobileNetV2[33]骨干)和无辅助方法(MODNet[18])进行比较。为了公平地比较它们的全自动矩阵,FBA使用了由语义分割方法DeepLabV3[3]和ResNet101[12]骨干的扩张和侵蚀产生的合成三角图;BGMv2只看到第一帧的真实背景;MODNet应用其邻帧平滑的技巧。我们试图在我们的数据上重新训练MODNet,但结果更糟,可能是由于训练过程中的问题,所以MODNet使用了它的常规权重;BGMv2已经在所有三个数据集上进行了训练;FBA在写作时还没有发布训练代码。
我们用MAD(平均绝对差异)、MSE(平均平方误差)、Grad(空间梯度)[31]和Conn(连通性)[31]来评价α与地面实况α的关系,并采用dtSSD[8]来评价时间上的一致性。对于F,我们只用MSE来衡量 α ∗ > 0 α^∗>0 α∗>0的像素。MAD和MSE的比例为1e 3,dtSSD的比例为1e 2,以提高可读性。F没有在VM上测量,因为它包含了有噪声的地面实况。MODNet不预测F,所以我们在输入帧上评估,作为其前景预测。这模拟了直接在输入上应用阿尔法哑光。
表1对使用低分辨率输入的方法进行了比较。我们的方法在这种情况下不使用DGF。我们的方法在所有的数据集上预测出更准确和一致的α。特别是,FBA受到不准确的合成trimap的限制。BGMv2对动态背景的表现很差。MODNet产生的结果不如我们的准确和一致。对于前景预测,我们的结果落后于BGMv2,但超过了FBA和MODNet。
表2进一步比较了我们的方法和MODNet在高分辨率上的表现。由于DGF必须与网络一起进行端到端的训练,我们修改了MODNet,使用非学习的快速引导滤波器(FGF)来对预测进行上采样。这两种方法都对编码器-解码器网络使用降采样尺度s = 0.25。我们去掉了Conn指标,因为它在高分辨率下计算起来过于庞大。我们的方法在所有指标上都优于MODNet。

表1: 低分辨率的比较。我们的阿尔法预测优于其他所有的预测。我们的前景预测落后于BGMv2,但胜过FBA和MODNet。请注意,FBA使用DeepLabV3的合成trimap;BGMv2只看到第一帧的地面真实背景;MODNet不预测前景,所以它是在输入图像上评估的。

表2:高分辨率的阿尔法比较。我们的比带快速引导滤波器(FGF)的MODNet好。
5.2. Evaluation on Real Videos(对真实视频的评估)
图3显示了对真实视频的定性比较。在图3a中,我们比较了所有方法的阿尔法预测,发现我们的方法能更准确地预测细微的细节,如头发丝。在图3b中,我们在随机的YouTube视频上进行实验。由于这些视频没有预先拍摄的背景,我们将BGMv2从比较中删除。我们发现,我们的方法对语义错误更加稳健。在图3c和3d中,我们进一步比较了手机和网络摄像头视频的实时消光与MODNet。我们的方法可以比MODNet更好地处理快速移动的身体部位。
5.3. Size and Speed Comparison(尺寸和速度比较)
表3和表4显示,我们的方法明显更轻,与MODNet相比,只有58%的参数。我们的方法在高清(1920 × 1080)上是最快的,但在512 × 288上比BGMv2慢一点,在4K(3840 × 2160)上比MODNet与FGF慢一点。我们的检查发现,DGF和FGF的性能差异非常小。我们的方法在4K上比MODNet慢,因为我们的方法除了预测阿尔法之外,还预测前景,所以在高分辨率下处理3个额外的通道会比较慢。我们使用[37]来测量GMACs(乘积操作),但它只测量卷积,而忽略了DGF和FGF中使用最多的调整大小和许多张量操作,所以GMACs只是一个粗略的近似值。我们的方法实现了高清104 FPS和4K 76 FPS,这对许多应用来说是实时的。

表3:我们的方法比所有比较的方法都要轻。尺寸以FP32的权重来衡量。

表4:模型性能比较。s表示降样比例。模型被转换为TorchScript并在测试前进行了优化(BatchNorm融合等)。FPS是以Nvidia GTX 1080Ti GPU上的FP32张量吞吐量来衡量。GMACs是一个粗略的近似值。
6. 消融研究
6.1. Role of Temporal Information(时间信息的作用)
图4显示了所有VM测试片段的平均α-MAD指标随时间的变化。我们的模型在前15帧的误差明显下降,然后指标保持稳定。MODNet即使采用了邻帧平滑技巧,其指标也有很大的波动。我们还试验了在我们的网络中通过零张量作为递归状态来禁用递归功能。质量和一致性如预期的那样恶化了。这证明了时间信息可以提高质量和一致性。
图3: 定性比较。与其他方法相比,我们的方法产生更详细的阿尔法。在对YouTube、手机和网络摄像头视频进行评估时,我们的方法始终比其他方法更强大。更多结果见补充说明。YouTube视频是从互联网上抓取的;手机视频来自一个公共数据集[17];一些网络摄像头的例子是记录的,而其他的则来自[24]。
图5在一个视频样本上比较了时间一致性和MODNet。我们的方法在扶手区域产生了一致的结果,而MODNet产生了flicker,这大大降低了感知质量。更多结果请见我们的补充报告。
我们进一步检查了递归的隐藏状态。在图6中,我们发现我们的网络已经自动学会了重建背景,因为它随着时间的推移而显现,并将这些信息保留在其递归通道中,以帮助未来的预测。它还使用其他递归通道来跟踪运动历史。我们的方法甚至试图在视频包含摄像机运动时重建背景,并且能够在镜头切割时忘记无用的记忆。更多的例子在补充文件中。
6.2. Role of Segmentation Training Objective(分割训练目标的作用)
表5显示,当对包含人类的COCO验证图像子集进行评估时,我们的方法和语义分割方法一样稳健,而且只针对人类类别。我们的方法达到了61.50 mIOU,考虑到模型大小的不同,这合理地介于MobileNetV3和DeepLabV3在COCO上训练的性能之间。我们还尝试通过阈值α>0.5作为二进制掩码来评估我们的阿尔法输出的鲁棒性,我们的方法仍然取得了60.88 mIOU,表明阿尔法预测也是鲁棒的。为了比较,我们用COCO的预训练权重初始化MobileNetV3编码器和LR-ASPP模块,并删除分割目标,从而训练一个单独的模型。该模型覆盖了合成的垫子数据,并对COCO的性能进行了显著的回归,仅达到38.24 mIOU。
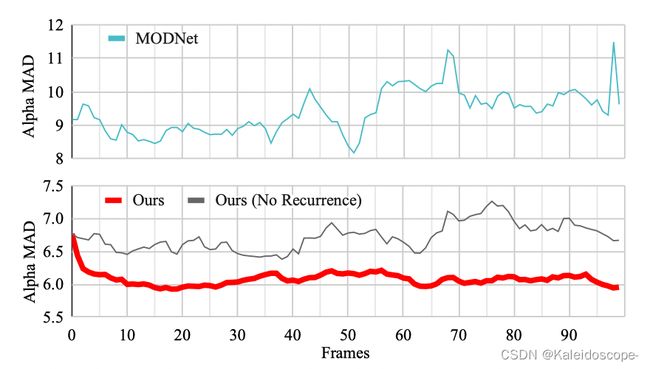
图4:在没有DGF的虚拟机上,平均αMAD随时间变化。我们的指标随着时间的推移而改善,并且是稳定的,这表明时间信息提高了质量和一致性。

图5:时间上的一致性比较。MODNet的结果在扶手上有flicker,而我们的是一致的。

图6: 递归隐藏状态下的两个例子通道。我们的网络学会了随着时间的推移重建背景,并在其循环状态中保持对运动历史的跟踪。

表5:COCO验证集的分割性能。用分割目标进行训练使我们的方法变得稳健,而只用预训练的权重进行训练则会退步。
6.3. Role of Deep Guided Filter(深度导引过滤器的作用)
表6显示,与FGF相比,DGF在尺寸和速度上只有很小的开销。DGF有一个更好的Grad度量,表明其高分辨率的细节更准确。DGF还产生了由dtSSD指标显示的更连贯的结果,可能是因为它考虑到了来自递归解码器的隐藏特征。MAD和MSE指标是不确定的,因为它们被分割层面的错误所支配,而DGF和FGF都没有纠正这些错误。

表6:在D646上切换DGF和FGF的比较。参数以百万为单位。FPS以HD计算。
6.4. Static vs. Dynamic Backgrounds(静态与动态背景)
表7比较了静态和动态背景下的性能。动态背景包括背景物体的移动和摄像机的移动。我们的方法可以处理这两种情况,在静态背景上的表现稍好,可能是因为如图6所示,重建像素对齐的背景比较容易。另一方面,BGMv2在动态背景上的表现很差,MODNet没有表现出任何偏好。Inmetric,BGMv2在静态背景上的表现优于我们的,但在现实中,当预拍的背景有错位时,预计它的表现会更糟。
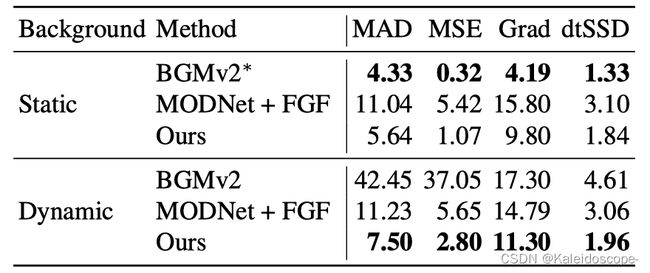
表7:比较静态和动态背景下的VM样本。我们的方法在静态背景上做得更好,但可以处理这两种情况。请注意,BGMv2接收的是地面真实的静态背景,但现实中的背景有错位。
6.5. Larger Model for Extra Performance(更大的模型,更多的性能)
我们尝试将主干网换成ResNet50[12]并增加解码器通道。表8显示了性能的提高。大模型更适合于服务器端的应用。

表8:大型模型使用ResNet50骨干网,有更多的解码器通道。在高清的虚拟机上进行了评估。尺寸以MB为单位。
6.6. Limitations(限制因素)
我们的方法更倾向于有明确目标主体的视频。当背景中有人时,感兴趣的主题就会变得模糊不清。它也更倾向于简单的背景,以产生更准确的矩阵。图7显示了一些具有挑战性的案例。

图7:具有挑战性的案例。背景中的人使消光的目标变得模糊不清。复杂的场景使消光工作更加困难。
7. 结论
我们提出了一个用于稳健的人类视频消光的递归架构。我们的方法达到了新的先进水平,同时更轻更快。我们的分析表明,时间信息在提高质量和一致性方面起着重要作用。我们还引入了一种新的训练策略,在消光和语义分割目标上训练我们的模型。这种方法有效地迫使我们的模型在各种类型的视频上具有鲁棒性。
References
[1] Yagiz Aksoy, Tunc Ozan Aydin, and Marc Pollefeys. Designing effective inter-pixel information flow for natural image matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 29–37, 2017.
[2] Nicolas Ballas, L. Yao, C. Pal, and Aaron C. Courville. Delving deeper into convolutional networks for learning video representations. CoRR, abs/1511.06432, 2016.
[3] Liang-Chieh Chen, G. Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. ArXiv, abs/1706.05587, 2017.
[4] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation, 2018.
[5] Qifeng Chen, Dingzeyu Li, and Chi-Keung Tang. Knn matting. IEEE transactions on pattern analysis and machine intelligence, 35(9):2175–2188, 2013.
[6] Kyunghyun Cho, B. V. Merrienboer, C¸aglar G¨ulc¸ehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. ArXiv, abs/1406.1078, 2014.
[7] Yung-Yu Chuang, Brian Curless, David H Salesin, and Richard Szeliski. A bayesian approach to digital matting. In CVPR (2), pages 264–271, 2001.
[8] M. Erofeev, Yury Gitman, D. Vatolin, Alexey Fedorov, and J.
Wang. Perceptually motivated benchmark for video matting. In BMVC, 2015.
[9] Marco Forte and Franc¸ois Piti´e. F, b, alpha matting. CoRR, abs/2003.07711, 2020.
[10] Eduardo SL Gastal and Manuel M Oliveira. Shared sampling for real-time alpha matting. In Computer Graphics Forum, volume 29, pages 575–584. Wiley Online Library, 2010.
[11] Kaiming He, Jian Sun, and X. Tang. Guided image filtering.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 35:1397–1409, 2013.
[12] Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
[13] S. Hochreiter and J. Schmidhuber. Long short-term memory.
[18] Zhanghan Ke, Kaican Li, Yurou Zhou, Qiuhua Wu, Xiangyu Mao, Qiong Yan, and Rynson W.H. Lau. Is a green screen really necessary for real-time portrait matting? ArXiv, abs/2011.11961, 2020.
[19] Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross B. Girshick. Pointrend: Image segmentation as rendering. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9796–9805, 2020.
[20] Anat Levin, Dani Lischinski, and Yair Weiss. A closed-form solution to natural image matting. IEEE transactions on pattern analysis and machine intelligence, 30(2):228–242, 2007.
[21] Anat Levin, Alex Rav-Acha, and Dani Lischinski. Spectral matting. IEEE transactions on pattern analysis and machine intelligence, 30(10):1699–1712, 2008.
[22] Shanchuan Lin, Andrey Ryabtsev, Soumyadip Sengupta, Brian Curless, Steve Seitz, and Ira KemelmacherShlizerman. Real-time high-resolution background matting. In Computer Vision and Pattern Regognition (CVPR), 2021.
[23] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Doll´ar. Microsoft coco: Common objects in context, 2015.
[24] Marwa Mahmoud, Tadas Baltruˇsaitis, Peter Robinson, and Laurel Riek. 3d corpus of spontaneous complex mental states. In Conference on Affective Computing and Intelligent Interaction, 2011.
[25] Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training, 2018.
[26] Vinod Nair and Geoffrey E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010.
Neural Computation, 9:1735–1780, 1997.
[27] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alch´e-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
[14] Qiqi Hou and Feng Liu. Context-aware image matting for simultaneous foreground and alpha estimation, 2019.
[15] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, and Hartwig Adam. Searching for mobilenetv3, 2019.
[16] Sergey Ioffe and Christian Szegedy. Batch normalization:
Accelerating deep network training by reducing internal covariate shift, 2015.
[17] Yasamin Jafarian and Hyun Soo Park. Learning high fidelity depths of dressed humans by watching social media dance videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12753–12762, June 2021.
[28] Andreas Pfeuffer, Karina Schulz, and K. Dietmayer. Semantic segmentation of video sequences with convolutional lstms. 2019 IEEE Intelligent Vehicles Symposium (IV), pages 1441–1447, 2019.
[29] Yu Qiao, Yuhao Liu, Xin Yang, Dongsheng Zhou, Mingliang Xu, Qiang Zhang, and Xiaopeng Wei. Attention-guided hierarchical structure aggregation for image matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13676–13685, 2020.
[30] Yu Qiao, Yuhao Liu, Xin Yang, Dongsheng Zhou, Mingliang Xu, Qiang Zhang, and Xiaopeng Wei. Attention-guided hierarchical structure aggregation for image matting. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
[31] Christoph Rhemann, C. Rother, J. Wang, M. Gelautz, P.
Kohli, and P. Rott. A perceptually motivated online benchmark for image matting. In CVPR, 2009.
[32] Olga Russakovsky, J. Deng, Hao Su, J. Krause, S. Satheesh,
S. Ma, Zhiheng Huang, A. Karpathy, A. Khosla, Michael S. Bernstein, A. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115:211–252, 2015.
[33] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks, 2019.
[34] Soumyadip Sengupta, Vivek Jayaram, Brian Curless, Steve Seitz, and Ira Kemelmacher-Shlizerman. Background matting: The world is your green screen. In Computer Vision and Pattern Regognition (CVPR), 2020.
[35] Xiaoyong Shen, Xin Tao, Hongyun Gao, Chao Zhou, and Jiaya Jia. Deep automatic portrait matting. In European Conference on Computer Vision, pages 92–107. Springer, 2016.
[36] Xingjian Shi, Zhourong Chen, Hao Wang, D. Yeung, W. Wong, and W. Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In NIPS, 2015.
[37] Vladislav Sovrasov. flops-counter.pytorch.
[38] Jian Sun, Jiaya Jia, Chi-Keung Tang, and Heung-Yeung Shum. Poisson matting. In ACM Transactions on Graphics (ToG), volume 23, pages 315–321. ACM, 2004.
[39] Yanan Sun, Guanzhi Wang, Qiao Gu, Chi-Keung Tang, and Yu-Wing Tai. Deep video matting via spatio-temporal alignment and aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2021.
[40] supervise.ly. Supervisely person dataset. supervise.ly, 2018.
[41] Pavel Tokmakov, Alahari Karteek, and C. Schmid. Learning video object segmentation with visual memory. In ICCV, 2017.
[42] C. Ventura, Miriam Bellver, Andreu Girbau, A. Salvador, F. Marqu´es, and Xavier Gir´o i Nieto. Rvos: End-to-end recurrent network for video object segmentation. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5272–5281, 2019.
[43] Jue Wang, Michael F Cohen, et al. Image and video matting:
a survey. Foundations and Trends® in Computer Graphics and Vision, 3(2):97–175, 2008.
[44] Huikai Wu, Shuai Zheng, Junge Zhang, and Kaiqi Huang.
Fast end-to-end trainable guided filter, 2019.
[45] Ning Xu, Brian Price, Scott Cohen, and Thomas Huang. Deep image matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 29702979, 2017.
[46] Yunke Zhang, Lixue Gong, Lubin Fan, Peiran Ren, Qixing Huang, Hujun Bao, and Weiwei Xu. A late fusion cnn for digital matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 74697478, 2019.
[47] Bingke Zhu, Yingying Chen, Jinqiao Wang, Si Liu, Bo Zhang, and Ming Tang. Fast deep matting for portrait animation on mobile phone. In Proceedings of the 25th ACM international conference on Multimedia, pages 297–305. ACM, 2017.
A. Overview
我们在本补充文件中提供了额外的细节。在B节中,我们描述了我们网络结构的细节。在C节中,我们解释了训练的细节。在D节中,我们展示了我们的合成垫层数据样本的例子。在E节中,我们展示了我们方法的其他结果。我们还在补充部分附上了视频结果。请看我们的视频以获得更好的视觉效果。
B. Network
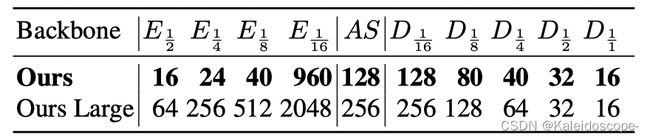
表9:不同尺度的特征通道。E k和D k分别表示K特征尺度下的编码器和解码器通道。AS表示LR-ASPP通道。
表9描述了我们的网络及其带有特征通道的变体。我们的默认网络使用MobileNetV3Large[15]骨干网,而大型变体使用ResNet50[12]骨干网。
Encoder(编码器):编码器主干对单个帧进行操作,在k∈[ 1 2 1\over2 21, 1 4 1\over4 41, 1 8 1\over8 81, 1 16 1\over16 161] 尺度下提取E k通道的特征图。与常规的MobileNetV3和ResNet骨干网继续以 1 32 1\over32 321的尺度操作不同,我们按照[3, 4, 15]的设计,将最后一个块修改为使用扩张率为2,步长为1的卷积。最后的特征图E 1 16 1\over16 161被交给LR-ASPP模块,该模块将其压缩为AS通道。
Decoder(解码器):所有的ConvGRU层通过分割和串联对一半的通道进行操作,所以递归隐性状态在规模k时有 D k 2 Dk\over2 2Dk通道。对于上采样2块,卷积、批量归一化和ReLU堆栈在分割到ConvGRU之前将串联的特征压缩到D k通道。对于输出块,前两个卷积有16个filters,最后的隐藏特征有16个通道。最后的投影卷积输出5个通道,包括3个通道的前景,1个通道的阿尔法,和1个通道的分割预测。除了最后的投影使用1×1的内核,所有的卷积都使用3×3的内核。平均集合使用2×2核,跨度为2。
Deep Guided Filter(深度引导型过滤器):DGF内部包含一些1×1的卷积。我们对它进行了修改,将预测的前景、阿尔法和最终的隐藏特征作为输入。所有的内部卷积都使用16个滤波器。更多细节请参考[44]。
我们的整个网络是在PyTorch[27]中建立和训练的。我们按照[9, 22]的做法,将阿尔法和前景预测输出钳制在[0, 1]的范围内,没有激活函数。钳制是在训练和推理过程中进行的。分割预测的输出是sigmoid logits。
C. Training

算法1显示了我们提出的训练策略的训练循环。序列长度参数T、T是根据阶段来设置的,这在我们的正文中有所规定;批量大小参数设置为B=4,B′=B×T;输入分辨率随机采样为h、w∼Uniform(256,512),h、wˆ∼Uniform(1024,2048)。
我们的网络是用4个Nvidia V100 32G GPU训练的。我们使用混合精度训练[25]来减少GPU的内存消耗。训练在每个阶段分别需要大约18、2、8和14小时。
D. Data Samples
图8显示了来自抠图数据集的合成训练样本的例子。这些片段包含了与视频合成时的自然运动,以及由运动增强产生的人工运动。
图8:合成的训练样本。最后一栏显示了每个像素在不同时间的标准偏差,以可视化运动。
图9显示了合成的测试样本的例子。测试样本只对图像前景和背景进行了运动增强。运动增强只包括非线性变换。与训练增强相比,增强的强度也较弱,以使测试样本看起来尽可能的真实。
图9:测试样本实例。扩增只应用于图像的前景和背景。增强的强度较弱,以使样本看起来更真实。
E. Additional Results
图10显示了与MODNet的其他定性比较。我们的方法始终更加稳健。图11比较了与MODNet的时间一致性。MODNet在低可信度的区域有闪烁的现象,而我们的结果是连贯的。图12显示了我们模型的循环隐藏状态的其他例子。它表明,我们的模型已经学会了在其递归状态中存储有用的时间信息,并且能够在镜头切入时忘记无用的信息。
图10:与MODNet的更多定性比较。

图11:时间上的一致性比较。我们的结果在时间上是连贯的,而MODNet则在扶手周围产生flicker。这是因为MODNet把每一帧都当作独立的图像来处理,所以它的消光决定是不一致的。
图12:更多的重复性隐藏状态的例子。第一个静态背景的例子清楚地表明我们的模型随着时间的推移重建了被遮挡的背景区域。第二个例子中的手持摄像机显示,我们的模型仍然试图重建背景,而且它已经学会了在镜头切割时忘记无用的循环状态。