深度学习基础之激活函数
文章目录
- 激活函数
-
- 阶跃函数
- sigmoid函数
- sigmoid函数和阶跃函数的比较
- 为什么激活函数要用非线性函数?
- ReLU函数-线性整流函数
- Leaky ReLU函数-带泄露线性整流函数
- tanh函数-双曲正切函数
- 参考
激活函数
激活函数是连接感知机和神经网络的桥梁。
激活函数以阈值为界,一旦输入超过阈值,就切换输出。这样的函数称为“阶跃函数”。因此,可以说感知机中使用了阶跃函数作为激活函数。也就是说,在激活函数的众多候选函数中,感知机使用了阶跃函数。那么,如果感知机使用其他函数作为激活函数的话会怎么样呢?实际上,如果将激活函数从阶跃函数换成其他函数,就可以进入神经网络的世界了。下面我们就来介绍一下神经网络使用的激活函数。
阶跃函数
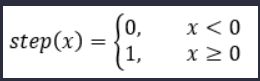
输出为0和1,其导数在绝大多数地方都是0
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
#阶跃函数,以数组x为参数,对数组x的各个元素执行阶跃函数运算,大于0的元素转化为1,小于0的元素转化为0,并以数组形式返回运算结果。
def step_function(x):
y=x>0#将数组x中大于0的元素转换为True,小于等于0的元素转换为False,生成一个新的bool型数组y
y=y.astype(int)#把数组y的元素类型从布尔型转换为int型。True会转换为1,False会转换为0。
return y
#在−5.0到5.0的范围内,以0.1为单位,生成NumPy数组([-5.0, -4.9, ..., 4.9]),100维
X = np.arange(-5.0, 5.0, 0.1)
Y = step_function(X)#以数组X为参数,对数组的各个元素执行阶跃函数运算,并以数组形式返回运算结果。
plt.plot(X, Y,label="step")
plt.ylim(-0.1, 1.1) # 指定图中绘制的y轴的范围
plt.xlabel("x") # x轴的标签
plt.ylabel("y") # y轴的标签
plt.title('step_functon')
plt.legend()#显示图例
plt.show()
sigmoid函数


式中的exp(−x)表示e−x的意思。e是纳皮尔常数2.7182 …。该式表示的sigmoid函数看上去有些复杂,但它也仅仅是个函数而已。而函数就是给定某个输入后,会返回某个输出的转换器。比如,向sigmoid函数输入1.0或2.0后,就会有某个值被输出,类似h(1.0) = 0.731 …、h(2.0) = 0.880 …这样。
Sigmoid函数输出均在0和1之间,导数在任何地方都不为0,反向传播时,梯度消失。
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
#以数组x为参数,对数组x的各个元素执行sigmoid运算,并以数组形式返回运算结果。
def sigmoid(x):
return 1 / (1 + np.exp(-x)) # 因为np.exp(-x)会生成NumPy数组,所以1 / (1 + np.exp(-x))的运算将会在NumPy数组的各个元素间进行。
X = np.arange(-5.0, 5.0, 0.1)
Y = sigmoid(X)
plt.plot(X, Y,label="sigmoid")
plt.ylim(-0.1, 1.1)
plt.xlabel("x") # x轴的标签
plt.ylabel("y") # y轴的标签
plt.title('sig')
plt.legend()#显示图例
plt.show()

sigmoid函数和阶跃函数的比较
神经网络中用sigmoid函数作为激活函数,进行信号的转换,转换后的信号被传送给下一个神经元。实际上,上一章介绍的感知机和接下来要介绍的神经网络的主要区别就在于这个激活函数。其他方面,比如神经元的多层连接的构造、信号的传递方法等,基本上和感知机是一样的。下面,让我们通过和阶跃函数的比较来详细学习作为激活函数的sigmoid函数。
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
#生成数据
x = np.arange(-5.0, 5.0, 0.1)#以0.1为单位,生成-5到5的数据
y1 = sigmoid(x)
y2 = step_function(x)
#绘制阶跃函数与sigmoid函数的比较图
plt.plot(x, y1,label="sigmoid")
plt.plot(x, y2, 'k--',label="step")
plt.ylim(-0.1, 1.1) #指定图中绘制的y轴的范围
plt.xlabel("x") # x轴的标签
plt.ylabel("y") # y轴的标签
plt.title('sig & step')
plt.legend()#显示图例
plt.show()

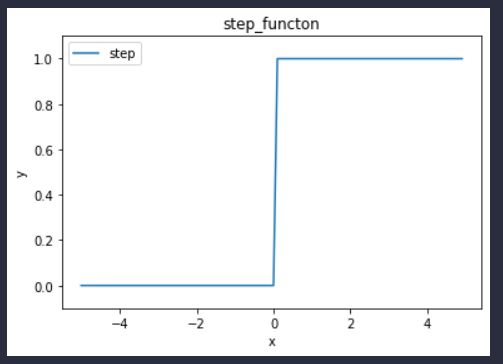
图3-8 sigmoid函数与阶跃函数的比较
现在我们来比较一下sigmoid 函数和阶跃函数,如图3-8所示。两者的不同点在哪里呢?又有哪些共同点呢?我们通过观察图3-8来思考一下。观察图3-8,首先注意到的是“平滑性”的不同。sigmoid函数是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以0为界,输出发生急剧性的变化。sigmoid函数的平滑性对神经网络的学习具有重要意义。
另一个不同点是,相对于阶跃函数只能返回0或1,sigmoid函数可以返回0.731 …、0.880 …等实数(这一点和刚才的平滑性有关)。也就是说,感知机中神经元之间流动的是或1的二元信号,而神经网络中流动的是连续的实数值信号。
接着说一下阶跃函数和sigmoid函数的共同性质。阶跃函数和sigmoid函数虽然在平滑性上有差异,但是如果从宏观视角看图3-8,可以发现它们具有相似的形状。实际上,两者的结构均是“输入小时,输出接近0(为0);随着输入增大,输出向1靠近(变成1)”。也就是说,当输入信号为重要信息时,阶跃函数和sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。还有一个共同点是,不管输入信号有多小,或者有多大,输出信号的值都在0到1之间。
阶跃函数和sigmoid函数还有其他共同点,就是两者均为非线性函数。sigmoid函数是一条曲线,阶跃函数是一条像阶梯一样的折线,两者都属于非线性的函数。在介绍激活函数时,经常会看到“非线性函数”和“线性函数”等术语。函数本来是输入某个值后会返回一个值的转换器。向这个转换器输入某个值后,输出值是输入值的常数倍的函数称为线性函数(用数学式表示为h(x) = cx。c为常数)。因此,线性函数是一条笔直的直线。而非线性函数,顾名思义,指的是不像线性函数那样呈现出一条直线的函数。
为什么激活函数要用非线性函数?
神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神经网络的层数就没有意义了。
线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。为了具体地(稍微直观地)理解这一点,我们来思考下面这个简单的例子。这里我们考虑把线性函数 h(x) = cx 作为激活函数,把y(x) = h(h(h(x)))的运算对应3层神经网络A。这个运算会进行y(x) = c × c × c × x的乘法运算,但是同样的处理可以由y(x) = ax(注意,a = c^3)这一次乘法运算(即没有隐藏层的神经网络)来表示。如本例所示,使用线性函数时,无法发挥多层网络带来的优势。因此,为了发挥叠加层所带来的优势,激活函数必须使用非线性函数。
到目前为止,我们介绍了作为激活函数的阶跃函数和sigmoid函数。在神经网络发展的历史上,sigmoid函数很早就开始被使用了,而通常使用的激活函数还包括ReLU函数、Leaky ReLU函数、Tanh函数等函数。现在逐一对它们进行介绍。
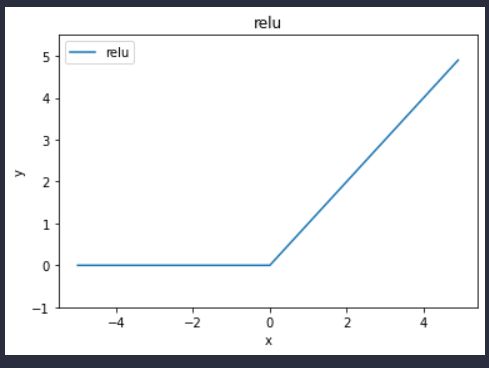
ReLU函数-线性整流函数

# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
#以数组x为参数,对数组x的各个元素执行maximum运算,大于0的元素不变,小于0的元素转化为0,并以数组形式返回运算结果。
def relu(x):
return np.maximum(0, x)
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x, y,label="relu")
plt.ylim(-1.0, 5.5)
plt.xlabel("x") # x轴的标签
plt.ylabel("y") # y轴的标签
plt.title('relu')
plt.legend()#显示图例
plt.show()
Leaky ReLU函数-带泄露线性整流函数
假设在反向传播的过程中,有一个很大的梯度传过ReLU神经元,这会引起权重w和偏置b发生变化,使得大部分输入在经过ReLU函数时只能得到一个0,因此 大多数输入不能反向传播通过ReLU得到一个梯度,相当于这个神经元死掉了,因此此现象被称为dying ReLU。为了解决这个问题,人们设计了Leaky ReLU函数。
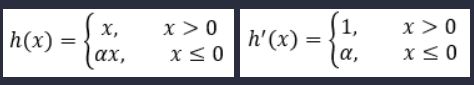
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
#以数组x为参数,对数组x的各个元素执行maximum运算,大于0的元素不变,小于0的元素转化为原来的0.05倍,并以数组形式返回运算结果。
def Leaky_relu(x):
return np.maximum(0.05*x, x)
x = np.arange(-5.0, 5.0, 0.1)
y1 = Leaky_relu(x)
plt.plot(x, y1,label="Leaky_relu")
plt.ylim(-1, 6)
plt.xlabel("x") # x轴的标签
plt.ylabel("y") # y轴的标签
plt.title('Leaky_relu')
plt.legend()#显示图例
plt.show()
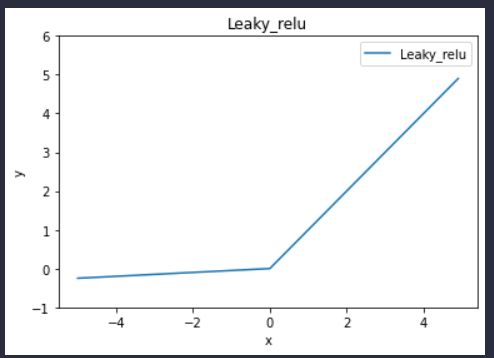
我们可以观察到,与ReLU相比,在Leaky ReLu中数值为负的输入将不会得到0的输出,而是得到a*x,本例中a取0.05。因此,在反向传播的过程中LeakyReLU在取值小于0部分会给一个很小的梯度a,从而避免了dying ReLU现象的发生。
tanh函数-双曲正切函数

输出均在-1和1之间,导数在任何地方都不为0
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
#以数组x为参数,对数组x的各个元素执行tanh运算,并以数组形式返回运算结果。
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = tanh(x)
plt.plot(x, y,label="tanh")
plt.ylim(-1.1, 1.1)
plt.xlabel("x") # x轴的标签
plt.ylabel("y") # y轴的标签
plt.title('tanh')
plt.legend()#显示图例
plt.show()

ℎ 函数作为常用的激活函数,与比起来具有以下优点:解决了函数不关于原点对称的问题同时收敛速度比sigmoid更快。但同时它也具有和sigmoid同样的缺陷,并没有解决梯度弥散的问题。简单的理解梯度弥散,就是由于激活函数的“饱和”,当激活函数的导数落入饱和区,梯度会变得非常小。

参考
黄老师的课件