CycleGAN——loss解析及更改与实验
CycleGAN(五)loss解析及更改与实验
2019年04月01日 11:25:05 邢翔瑞版权声明:转载注明出处:邢翔瑞的技术博客
https://blog.csdn.net/weixin_36474809
https://blog.csdn.net/weixin_36474809/article/details/88895136
目的:弄懂loss的定义位置及何更改。
目录
一、论文中loss定义及含义
1.1 论文中的loss
1.2 adversarial loss
1.3 cycle consistency loss
1.4 总体loss
1.5 idt loss
二、代码中loss定义
2.1 判别器D的loss
2.2 生成器G的loss
2.3 Idt loss
2.4 定义位置汇总
三、更改与实验
3.1 定义及更改位置
3.2 测试时会打出相应参数信息
四、训练中loss值常见变化
4.1 常见loss
4.2 运行及存储位置
一、论文中loss定义及含义
CycleGAN论文详解:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
1.1 论文中的loss
其过程包含了两种loss:
- adversarial losses:尽可能让生成器生成的数据分布接近于真实的数据分布
- cycle consistency losses: 防止生成器G与F相互矛盾,即两个生成器生成数据之后还能变换回来近似看成X->Y->X
1.2 adversarial loss
尽可能让生成器生成的数据接近于真实的数据分布:

与GAN一样,G用于实现X->Y, 训练应当尽可能让此G(X)接近于Y,判别器Dy用于判别样本的真假。与GAN的公式一样:

同理,对于F实现 Y->X, 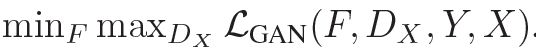
1.3 cycle consistency loss
用于让两个生成器生成的样本之间不要相互矛盾。
上一个adversarial loss只可以保证生成器生成的样本与真实样本同分布,但是我们希望对应的域之间的图像是一一对应的。即A-B-A还可以再迁移回来。

我们希望x -> G(x) -> F(G(x)) ≈ x,称作forward cycle consistency
同理,y -> F(y) -> G(F(y)) ≈ y, 称作 backward cycle consistency
为了尽可能保证consistency,我们设定相应的loss:
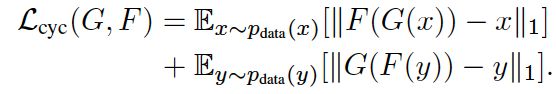
1.4 总体loss

即生成器G尽可能实现X到Y的迁移,生成器F尽可能实现Y到X的迁移,同时,希望两生成器的生成器是可以实现互逆,即相互迭代回到自身。(作者后面实验细节training datails之中,λ 取10 )
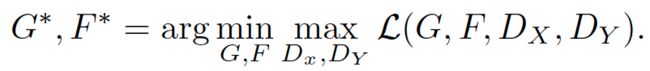
1.5 idt loss
有一个loss再论文主要部分没有提及,但是在application之中提及了,并且代码之中有涉及,是idt loss

cycle_gan_model.py之中对它的定义是这样:
parser.add_argument('--lambda_identity', type=float, default=0.5, help='use identity mapping. Setting lambda_identity other than 0 has an effect of scaling the weight of the identity mapping loss. For example, if the weight of the identity loss should be 10 times smaller than the weight of the reconstruction loss, please set lambda_identity = 0.1')
idt loss的定义在论文的application之中,防止input 与out put之间的color compostion过多。网络所有的loss的定义就是,reconstruction loss就是GAN loss和cycle consistency loss两个加在一起,GAN loss用于迁移类,cycle consistency loss用于尽量保留原图可以循环迁移。但是还有一个更直观的loss叫idt loss尽量的避免迁移过多。
二、代码中loss定义
models/cycle_gan_model.py
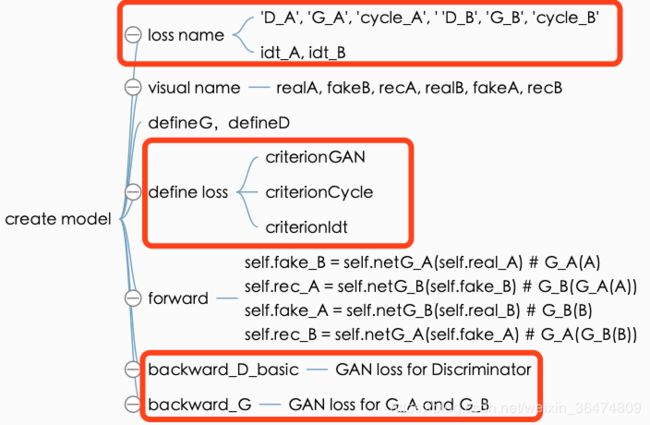
论文中并未提及idt_A以及idt_B的含义及作用。
2.1 判别器D的loss
运用真实样本作为正样本True,及G生成的样本作为负样本False,训练D
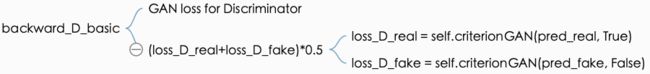
-
def backward_D_basic(self, netD, real, fake):
-
"""Calculate GAN loss for the discriminator
-
Parameters:
-
netD (network) -- the discriminator D
-
real (tensor array) -- real images
-
fake (tensor array) -- images generated by a generator
-
Return the discriminator loss.
-
We also call loss_D.backward() to calculate the gradients.
-
"""
-
# Real
-
pred_real = netD(real)
-
loss_D_real = self.criterionGAN(pred_real,
True)
-
# Fake
-
pred_fake = netD(fake.detach())
-
loss_D_fake = self.criterionGAN(pred_fake,
False)
-
# Combined loss and calculate gradients
-
loss_D = (loss_D_real + loss_D_fake) *
0.5
-
loss_D.backward()
-
return loss_D
2.2 生成器G的loss
self.loss_G_A + self.loss_G_B + self.loss_cycle_A + self.loss_cycle_B + self.loss_idt_A + self.loss_idt_B
-
# GAN loss D_A(G_A(A))
-
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B),
True)
-
# GAN loss D_B(G_B(B))
-
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A),
True)
-
# Forward cycle loss || G_B(G_A(A)) - A||
-
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
-
# Backward cycle loss || G_A(G_B(B)) - B||
-
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
-
# combined loss and calculate gradients
-
self.loss_G = self.loss_G_A + self.loss_G_B + self.loss_cycle_A + self.loss_cycle_B + self.loss_idt_A + self.loss_idt_B
-
self.loss_G.backward()

我们很容易理解,loss_G_A就是相应的GAN loss中的生成器G的项,loss_cycle_A就是cycle consistency loss中的项。
分别为GAN loss和L1 loss
-
# define loss functions
-
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device)
# define GAN loss.
-
self.criterionCycle = torch.nn.L1Loss()
-
self.criterionIdt = torch.nn.L1Loss()
2.3 Idt loss
idt loss是什么论文主要框架之中没有提及,cycle_gan_model.py之中对它的定义是这样:
parser.add_argument('--lambda_identity', type=float, default=0.5, help='use identity mapping. Setting lambda_identity other than 0 has an effect of scaling the weight of the identity mapping loss. For example, if the weight of the identity loss should be 10 times smaller than the weight of the reconstruction loss, please set lambda_identity = 0.1')
idt loss的定义再论文的application之中,防止input 与out put之间的color compostion过多。网络所有的loss的定义就是,reconstruction loss就是GAN loss和cycle consistency loss两个加在一起,GAN loss用于迁移类,cycle consistency loss用于尽量保留原图可以循环迁移。但是还有一个更直观的loss叫idt loss尽量的避免迁移过多。
2.4 定义位置汇总
- GAN loss前无系数,
- idt loss前面两个系数,lambda_B与lambda_idt
- cycle loss前一个系数,ldmbda_B
-
if lambda_idt >
0:
-
# G_A should be identity if real_B is fed: ||G_A(B) - B||
-
self.idt_A = self.netG_A(self.real_B)
-
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
-
# G_B should be identity if real_A is fed: ||G_B(A) - A||
-
self.idt_B = self.netG_B(self.real_A)
-
self.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idt
-
else:
-
self.loss_idt_A =
0
-
self.loss_idt_B =
0
-
-
# GAN loss D_A(G_A(A))
-
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B),
True)
-
# GAN loss D_B(G_B(B))
-
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A),
True)
-
# Forward cycle loss || G_B(G_A(A)) - A||
-
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
-
# Backward cycle loss || G_A(G_B(B)) - B||
-
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
三、更改与实验
3.1 定义及更改位置
cycle_gan_model.py之中定义与更改
-
For CycleGAN,
in addition to GAN losses, we introduce lambda_A, lambda_B, and lambda_identity
for the following losses.
-
A (
source domain), B (target domain).
-
Generators: G_A: A -> B; G_B: B -> A.
-
Discriminators: D_A: G_A(A) vs. B; D_B: G_B(B) vs. A.
-
Forward cycle loss: lambda_A * ||G_B(G_A(A)) - A|| (Eqn. (2)
in the paper)
-
Backward cycle loss: lambda_B * ||G_A(G_B(B)) - B|| (Eqn. (2)
in the paper)
-
Identity loss (optional): lambda_identity * (||G_A(B) - B|| * lambda_B + ||G_B(A) - A|| * lambda_A) (Sec 5.2
"Photo generation from paintings"
in the paper)
-
Dropout is not used
in the original CycleGAN paper.
-
""
"
-
parser.set_defaults(no_dropout=True) # default CycleGAN did not use dropout
-
if is_train:
-
parser.add_argument('--lambda_A', type=float, default=10.0, help='weight for cycle loss (A -> B -> A)')
-
parser.add_argument('--lambda_B', type=float, default=10.0, help='weight for cycle loss (B -> A -> B)')
-
parser.add_argument('--lambda_identity', type=float, default=0.5, help='use identity mapping. Setting lambda_identity other than 0 has an effect of scaling the weight of the identity mapping loss. For example, if the weight of the identity loss should be 10 times smaller than the weight of the reconstruction loss, please set lambda_identity = 0.1')
-
-
return parser
这里设置相应的值,直接对default 进行更改即可,也可以输入命令行进行相应的更改,命令行后加上:
--lambda_A 10 --lambda_B 10
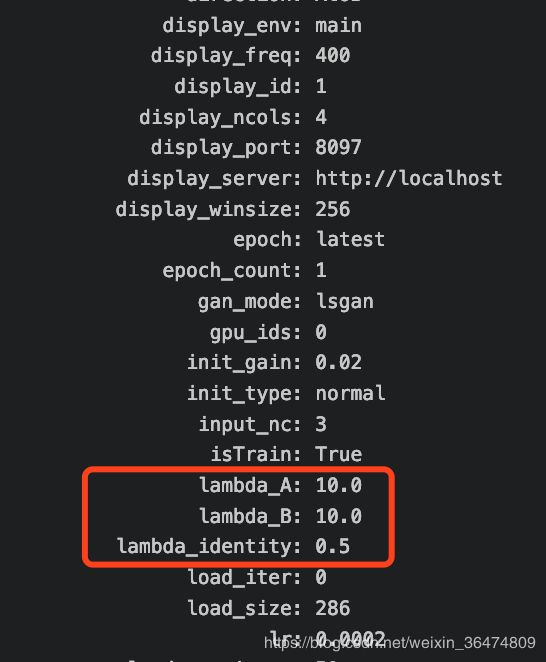
3.2 测试时会打出相应参数信息
四、训练中loss值常见变化
About loss curve
Unfortunately, the loss curve does not reveal much information in training GANs, and CycleGAN is no exception. To check whether the training has converged or not, we recommend periodically generating a few samples and looking at them.
作者给出,loss值对于实际的效果并没有影响,因为一个生成器和判别器的矛盾在于loss值,因此loss曲线并不能提现模型的性能。
4.1 常见loss
实际训练过程中可以根据loss值判断训练结果如何。几个值都是越小越好。
env/bin/python /home/xingxiangrui/pytorch-CycleGAN-and-pix2pix/train.py --dataroot /home/xingxiangrui/pytorch-CycleGAN-and-pix2pix/datasets/norText_2_cotton --name norText_2_cotton_cyclegan --model cycle_gan --no_html
运行成功:
-
[xingxiangrui@yq01-gpu-yq-face
-21
-5 ~]$ env/bin/python /home/xingxiangrui/pytorch-CycleGAN-
and-pix2pix/train.py --dataroot /home/xingxiangrui/pytorch-CycleGAN-
and-pix2pix/datasets/norText_2_cotton --name norText_2_cotton_cyclegan --model cycle_gan
-
----------------- Options ---------------
-
batch_size:
1
-
beta1:
0.5
-
checkpoints_dir: ./checkpoints
-
continue_train:
False
-
crop_size:
256
-
dataroot: /home/xingxiangrui/pytorch-CycleGAN-
and-pix2pix/datasets/norText_2_cotton [default:
None]
-
dataset_mode: unaligned
-
direction: AtoB
-
display_env: main
-
display_freq:
400
-
display_id:
1
-
display_ncols:
4
-
display_port:
8097
-
display_server: http://localhost
-
display_winsize:
256
-
epoch: latest
-
epoch_count:
1
-
gan_mode: lsgan
-
gpu_ids:
0
-
init_gain:
0.02
-
init_type: normal
-
input_nc:
3
-
isTrain:
True [default:
None]
-
lambda_A:
10.0
-
lambda_B:
10.0
-
lambda_identity:
0.5
-
load_iter:
0 [default:
0]
-
load_size:
286
-
lr:
0.0002
-
lr_decay_iters:
50
-
lr_policy: linear
-
max_dataset_size: inf
-
model: cycle_gan
-
n_layers_D:
3
-
name: norText_2_cotton_cyclegan [default: experiment_name]
-
ndf:
64
-
netD: basic
-
netG: resnet_9blocks
-
ngf:
64
-
niter:
100
-
niter_decay:
100
-
no_dropout:
True
-
no_flip:
False
-
no_html:
False
-
norm: instance
-
num_threads:
4
-
output_nc:
3
-
phase: train
-
pool_size:
50
-
preprocess: resize_and_crop
-
print_freq:
100
-
save_by_iter:
False
-
save_epoch_freq:
5
-
save_latest_freq:
5000
-
serial_batches:
False
-
suffix:
-
update_html_freq:
1000
-
verbose:
False
-
----------------- End -------------------
-
dataset [UnalignedDataset] was created
-
The number of training images =
100
-
initialize network
with normal
-
initialize network
with normal
-
initialize network
with normal
-
initialize network
with normal
-
model [CycleGANModel] was created
-
---------- Networks initialized -------------
-
[Network G_A] Total number of parameters :
11.378 M
-
[Network G_B] Total number of parameters :
11.378 M
-
[Network D_A] Total number of parameters :
2.765 M
-
[Network D_B] Total number of parameters :
2.765 M
-
-----------------------------------------------
-
。。。
-
create web directory ./checkpoints/norText_2_cotton_cyclegan/web...
-
(epoch:
1, iters:
100, time:
0.896, data:
1.052) D_A:
0.384 G_A:
0.232 cycle_A:
1.791 idt_A:
0.739 D_B:
0.572 G_B:
0.620 cycle_B:
2.002 idt_B:
0.851
-
End of epoch
1 /
200 Time Taken:
92 sec
-
learning rate =
0.0002000
-
(epoch:
2, iters:
100, time:
0.865, data:
0.214) D_A:
0.219 G_A:
0.304 cycle_A:
1.499 idt_A:
0.597 D_B:
0.305 G_B:
0.699 cycle_B:
1.118 idt_B:
0.711
-
End of epoch
2 /
200 Time Taken:
87 sec
-
learning rate =
0.0002000
-
。。。
-
(epoch:
195, iters:
100, time:
0.865, data:
0.209) D_A:
0.016 G_A:
0.836 cycle_A:
0.584 idt_A:
0.168 D_B:
0.124 G_B:
0.346 cycle_B:
0.530 idt_B:
0.181
-
saving the model at the end of epoch
195, iters
19500
-
End of epoch
195 /
200 Time Taken:
88 sec
-
learning rate =
0.0000119
-
(epoch:
196, iters:
100, time:
1.197, data:
0.237) D_A:
0.036 G_A:
0.737 cycle_A:
0.590 idt_A:
0.133 D_B:
0.014 G_B:
0.271 cycle_B:
0.425 idt_B:
0.186
-
End of epoch
196 /
200 Time Taken:
87 sec
-
learning rate =
0.0000099
-
(epoch:
197, iters:
100, time:
0.871, data:
0.218) D_A:
0.031 G_A:
0.756 cycle_A:
0.533 idt_A:
0.113 D_B:
0.037 G_B:
0.511 cycle_B:
0.370 idt_B:
0.160
-
End of epoch
197 /
200 Time Taken:
86 sec
-
learning rate =
0.0000079
-
(epoch:
198, iters:
100, time:
0.856, data:
0.217) D_A:
0.063 G_A:
0.509 cycle_A:
0.634 idt_A:
0.123 D_B:
0.308 G_B:
0.492 cycle_B:
0.478 idt_B:
0.222
-
End of epoch
198 /
200 Time Taken:
86 sec
-
learning rate =
0.0000059
-
(epoch:
199, iters:
100, time:
0.903, data:
0.203) D_A:
0.033 G_A:
0.981 cycle_A:
0.515 idt_A:
0.110 D_B:
0.111 G_B:
0.531 cycle_B:
0.381 idt_B:
0.167
-
End of epoch
199 /
200 Time Taken:
86 sec
-
learning rate =
0.0000040
-
(epoch:
200, iters:
100, time:
1.200, data:
0.219) D_A:
0.017 G_A:
1.035 cycle_A:
0.613 idt_A:
0.106 D_B:
0.030 G_B:
0.726 cycle_B:
0.384 idt_B:
0.200
-
saving the latest model (epoch
200, total_iters
20000)
-
saving the model at the end of epoch
200, iters
20000
-
End of epoch
200 /
200 Time Taken:
89 sec
-
learning rate =
0.0000020
loss值越小,则训练越成功。最终D_A收敛于,一般看D的loss越小,则表明训练结果更好一些。
增大lambda为40之后,loss为:
-
================ Training Loss (Mon Apr
1
11:
46:
05
2019) ================
-
(epoch:
1, iters:
100, time:
0.600, data:
0.176) D_A:
0.224 G_A:
0.485 cycle_A:
5.948 idt_A:
5.620 D_B:
0.410 G_B:
0.693 cycle_B:
9.939 idt_B:
2.715
-
(epoch:
2, iters:
100, time:
0.604, data:
0.169) D_A:
0.251 G_A:
0.731 cycle_A:
5.778 idt_A:
4.086 D_B:
0.497 G_B:
1.078 cycle_B:
6.170 idt_B:
2.712
-
(epoch:
3, iters:
100, time:
0.597, data:
0.163) D_A:
0.201 G_A:
0.586 cycle_A:
5.058 idt_A:
6.942 D_B:
0.219 G_B:
0.741 cycle_B:
13.409 idt_B:
2.129
-
(epoch:
4, iters:
100, time:
0.838, data:
0.185) D_A:
0.123 G_A:
0.200 cycle_A:
5.216 idt_A:
1.311 D_B:
0.128 G_B:
0.740 cycle_B:
2.606 idt_B:
2.367
-
(epoch:
5, iters:
100, time:
0.597, data:
0.146) D_A:
0.113 G_A:
0.472 cycle_A:
6.259 idt_A:
1.344 D_B:
0.258 G_B:
0.829 cycle_B:
3.239 idt_B:
2.951
-
(epoch:
6, iters:
100, time:
0.598, data:
0.192) D_A:
0.088 G_A:
0.731 cycle_A:
3.720 idt_A:
1.364 D_B:
0.142 G_B:
2.097 cycle_B:
3.516 idt_B:
1.719
-
(epoch:
7, iters:
100, time:
0.601, data:
0.170) D_A:
0.261 G_A:
0.691 cycle_A:
5.233 idt_A:
2.105 D_B:
0.788 G_B:
1.213 cycle_B:
4.088 idt_B:
2.316
-
(epoch:
8, iters:
100, time:
0.986, data:
0.156) D_A:
0.108 G_A:
0.938 cycle_A:
4.672 idt_A:
3.141 D_B:
0.062 G_B:
0.983 cycle_B:
5.727 idt_B:
2.015
-
(epoch:
9, iters:
100, time:
0.599, data:
0.175) D_A:
0.072 G_A:
0.883 cycle_A:
4.078 idt_A:
0.846 D_B:
0.057 G_B:
0.977 cycle_B:
2.139 idt_B:
1.904
-
(epoch:
10, iters:
100, time:
0.599, data:
0.159) D_A:
0.142 G_A:
0.473 cycle_A:
4.346 idt_A:
1.358 D_B:
0.077 G_B:
0.753 cycle_B:
3.725 idt_B:
2.112
-
。。。
-
(epoch:
195, iters:
100, time:
0.602, data:
0.164) D_A:
0.020 G_A:
0.723 cycle_A:
1.798 idt_A:
0.337 D_B:
0.034 G_B:
0.554 cycle_B:
1.263 idt_B:
0.681
-
(epoch:
196, iters:
100, time:
0.919, data:
0.162) D_A:
0.009 G_A:
1.077 cycle_A:
1.783 idt_A:
0.317 D_B:
0.055 G_B:
0.737 cycle_B:
1.220 idt_B:
0.642
-
(epoch:
197, iters:
100, time:
0.602, data:
0.155) D_A:
0.008 G_A:
1.063 cycle_A:
1.974 idt_A:
0.321 D_B:
0.149 G_B:
0.443 cycle_B:
1.102 idt_B:
0.725
-
(epoch:
198, iters:
100, time:
0.599, data:
0.172) D_A:
0.007 G_A:
0.800 cycle_A:
1.763 idt_A:
0.450 D_B:
0.225 G_B:
0.888 cycle_B:
1.459 idt_B:
0.811
-
(epoch:
199, iters:
100, time:
0.599, data:
0.153) D_A:
0.009 G_A:
1.097 cycle_A:
1.814 idt_A:
0.325 D_B:
0.082 G_B:
0.636 cycle_B:
1.103 idt_B:
0.709
-
(epoch:
200, iters:
100, time:
0.946, data:
0.170) D_A:
0.009 G_A:
0.976 cycle_A:
1.923 idt_A:
0.319 D_B:
0.151 G_B:
0.608 cycle_B:
1.062 idt_B:
0.922
4.2 运行及存储位置
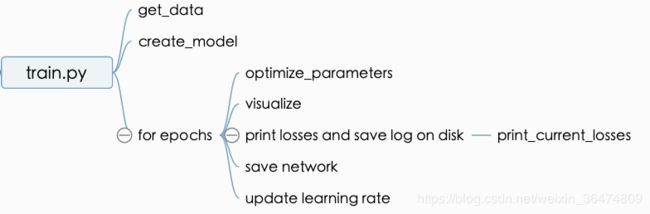
loss会进行相应运算并print出来,存于check points文件夹,之中模型的loss_log.txt之中,可以cat loss_log.txt打出loss信息。
注意,这个loss值是加了系数之后的loss,即乘了相应的lambda系数,之后打出的loss