无监督关键短语的生成问题博客11--tfidf.py的分析
2021SC@SDUSC
上一篇博客中,我们完成了对项目中utils.py的分析,在本篇博客中,我们将分析pke中的tfidf.py文件,首先我们将结合论文分析tf-idf指标的计算方法,接着结合实例的使用和tf-idf源码进行分析。
一、 tf-idf的计算方法
我们知道,关键短语生成问题实际上是为一系列短语提供排名,所以我们需要一些方法去为候选的短语进行排名,我们注意到词汇和语意的相似性对关键短语的排名是非常重要的,因此本项目结合了两种相似性进行排名,以得到sliver labels.
首先是嵌入相似性,我们知道,像类似于WordVec和Doc2Vec技术是可以将提取的关键短语和文档编码在同一空间中的,因为此,语意相似性就可以用空间中的余弦距离来测量,本篇文章中wikipedia英文数据集训练好的Doc2Vec模型将语料库中的文档和候选关键短语都编码成300维度的向量,如果我们将文档 和关键短语
和关键短语 的嵌入表示为
的嵌入表示为![]() ,
,![]() ,那么语意相似性层面可用公式以下公式计算:
,那么语意相似性层面可用公式以下公式计算:
![]()
而TF-IDF衡量的是词汇级别的相似性,特别地,对于一个预料库 ,其中一个文档,其含有的单词数为
,其中一个文档,其含有的单词数为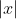 , 对于短语而言,其在文档出现的次数计作
, 对于短语而言,其在文档出现的次数计作![]() ,而
,而![]() 表示了在语料库中,有多少文章中出现了短语.其在词汇级别的相似度可以如下表示:
表示了在语料库中,有多少文章中出现了短语.其在词汇级别的相似度可以如下表示:
![]()
当文档很长时,TF-IDF的评分是稳定的,Doc2Vec对短文档和相对较长的文档的编码都很可靠,用几何平均数将语意和词汇相似性结合起来,便可综合考虑两种相似性。其最终计算公式如下:
![]()
二、pke的tf-idf使用实例
下面给出关键词提取后用tf-idf评分的一个例子并分析相关代码。
import string
import pke
# 创建一个TfIdf extractor
extractor = pke.unsupervised.TfIdf()
# 加载文档内容
extractor.load_document(input='path/to/input',
language='en',
normalization=None)
# 选择不包含标点符号的{1-3}语法作为候选
extractor.candidate_selection(n=3,stoplist=list(string.punctuation))
# 使用' tf ' x ' idf '对候选项进行加权
df = pke.load_document_frequency_file(input_file='path/to/df.tsv.gz')
extractor.candidate_weighting(df=df)
# 把得分最高的10个候选短语作为关键短语
keyphrases = extractor.get_n_best(n=10)首先是导入了pke包,然后在pke的unsupervised方法中,创建一个TfIdf对象作为extractor,调用load_document函数加载文档,将stoplist赋值为标点符号的list,即关键短语不含标点符号,ngram特征为3。之后载入文档频率文件,指定其输入路径,得到的结果为candidate_weighting的参数df,最后调用get_n_best方法得到了得分最高的10个候选关键短语。
三、tfidf源码的分析
tfidf.py的结构如下,主要有两个函数,candidate_selection和candidate_weighting,前一个函数实现了关键词的提取,后一个函数用tf-idf给关键词进行排序。
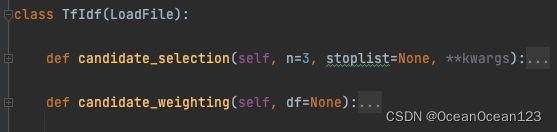
首先是导入相关的包。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import math
import string
import logging # 日志模块
from pke.base import LoadFile
from pke.utils import load_document_frequency_file # 加载文档频率文件我们先来看candidate_selection函数:
def candidate_selection(self, n=3, stoplist=None, **kwargs):
# 选取1-3gram特征的短语作为keyphrase candidate
# 从1-3选择ngram
self.ngram_selection(n=n)
# 如果没有stopplist,则初始化stopplist为空列表
if stoplist is None:
stoplist = list(string.punctuation)
# 过滤包含标点符号的候选关键短语
self.candidate_filtering(stoplist=stoplist)关于该函数的参数:
- n:期望输入的为int数值,为ngram的n,默认为3
- stoplist:期望输入为list类型,用于过滤候选关键短语的stoplist(停词列表),默认为“None”
- 来自'string.punctuation'符号标记的单词是不被允许的
这里首先是调用了ngram_selection方法,指定ngram特征为传入特征,初始化stoplist,当没有stoplist时为符号,最后过滤掉这些符号调用candidate_filtering方法传入stoplis过滤t生成关键短语。稍后我们再分析candidate_filtering方法。
再看candidate_weighting函数:
def candidate_weighting(self, df=None):
#使用文档频率的候选关键词的得分计算函数
# 如果没有提供文档频率计数,则初始化默认文档频率计数
if df is None:
logging.warning('LoadFile._df_counts is hard coded to {}'.format(self._df_counts))
df = load_document_frequency_file(self._df_counts, delimiter='\t')
# 初始化文档数量为--NB_DOC--+ 1
N = 1 + df.get('--NB_DOC--', 0)
# 循环candidates
for k, v in self.candidates.items():
# 获取候选文档频率
candidate_df = 1 + df.get(k, 0)
# 计算idf得分
idf = math.log(N / candidate_df, 2)
# 将idf分数添加到权重容器中
self.weights[k] = len(v.surface_forms) * idf
关于参数df的说明:df为文档的频率,文档的数量使用"--NB_DOC--" 键指定。
首先初始化文档数量为--NB_DOC--+ 1,代表语料库中含多少文档。对于candidates,用for循环遍历,对于语料库和短语c,调用get方法,得到了语料库中多少文档含有短语k,得到candidate_df,然后调用math的log方法,即可得到idf得分。对于短语k的得分,用tf与idf相乘即为最后结果。
四、candidate_filtering方法的分析
def candidate_filtering(self,
stoplist=None,
minimum_length=3,
minimum_word_size=2,
valid_punctuation_marks='-',
maximum_word_number=5,
only_alphanum=True,
pos_blacklist=None):
if stoplist is None: # 若stoplist未指定,初始化stoplist
stoplist = []
if pos_blacklist is None:
pos_blacklist = []该函数筛选包含来自stoplist中字符串的候选对象。只保留包含字母、数字字符的候选关键短语,并且这些关键短语的长度超过给定的长度。 (non_latin_filter被设置为True)
我们先对参数进行说明:
- stopplist (list):字符串列表,默认为None
- Minimum_length (int):最小字符数候选,默认为3
- Minimum_word_size (int):被认为是一个有效的单词,默认值为2
- valid_punctuation (str):有效的标点符号对于候选人,默认为'-'
- maxum_word_number (int):candidate的最大长度,默认为5
- only_alphanum (bool):过滤包含non (latin)的候选项字母数字字符,默认为True
- pos_blacklist (list):不需要的部分演讲列表候选,默认为[]
之后若stoplist和pos_blacklist为空,则初始化。
# 遍历candidate
for k in list(self.candidates):
# 得到候选短语
v = self.candidates[k]
words = [u.lower() for u in v.surface_forms[0]]
# 如果出现在stoplist中,则丢弃
if set(words).intersection(stoplist):
del self.candidates[k]
# 如果标签在pos_blacklist中,则丢弃
elif set(v.pos_patterns[0]).intersection(pos_blacklist):
del self.candidates[k]
# 丢弃只包含标点符号的标记
elif any([set(u).issubset(set(punctuation)) for u in words]):
del self.candidates[k]
# 丢弃1-2个字符组成的候选字符
elif len(''.join(words)) < minimum_length:
del self.candidates[k]
# 丢弃包含小字的候选词(1个字符)
elif min([len(u) for u in words]) < minimum_word_size:
del self.candidates[k]
# 丢弃由超过5个单词组成的候选词
elif len(v.lexical_form) > maximum_word_number:
del self.candidates[k]
# 如果不包含字母数字字符则丢弃
if only_alphanum and k in self.candidates:
if not all([self._is_alphanum(w, valid_punctuation_marks)
for w in words]):
del self.candidates[k]函数的核心部分在于循环遍历candidate用条件过滤,判断是否是stoplist的词,标签是否出现在pos_blacklist中,是否含有标点符号,且秋词只含有标点符号的标记,最后完成了candidate的过滤。
五、nltk实现tf-idf算法
最后我们简单地看一下在nltk中,tf-idf算法的简单实现。
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
# 构建语料库corpus
sents=['this is sentence one','this is sentence two','this is sentence three']
sents=[word_tokenize(sent) for sent in sents] # 对句子进行分词
print(sents) # 输出分词后的结果
corpus=TextCollection(sents) # 构建语料库
print(corpus) # 输出语料库在导入相关包之后构建语料库,这里以几个句子为例,之后用word_tokenize()方法对sents中的每一个句子进行分词,再以分词之后的结果构建语料库,这里的文档数就是3,一个文档为一句话。最后构建语料库完成,结果如下:
![]()
# 计算语料库中"one"的tf值
tf=corpus.tf('one',corpus) # 1/12
print(tf)
# 计算语料库中"one"的idf值
idf=corpus.idf('one') # log(3/1)
print(idf)
# 计算语料库中"one"的tf-idf值
tf_idf=corpus.tf_idf('one',corpus)
print(tf_idf)之后计算token的tf和idf再相乘,这里语料库构建完成后直接调用df和idf方法即可直接得到计算结果,对于one来说,在所有文档的12个token中出现了一次,所以tf值为1/12,在三个文档中的一个文档出现了一次,所以idf值为log(3/1),也可以直接调用tf_idf方法进行计算。结果如下:

至此,我已完成了对用wiki训练doc2vec的代码部分分析,并得到最后训练好的bin文件,完成了model.py,create_vocabulary.py,utils.py的分析,项目中其他文件的分析工作由队友完成。下一篇博客中,我们将介绍该论文的对比方法中的textrank方法,并结合实例分析其代码。