【论文】YOLO系列
目录
YOLO V1
YOLO V2
YOLO V1
在yolo之前,目标检测的巅峰之作是faster-rcnn。faster-rcnn是典型的two-stage目标检测网络,先用一个RPN(region proposal network)提取region proposal,再用一个分类网络判断RP中是否含有目标,所以faster-rcnn本质上是分类问题。
yolo v1是one-stage的开山之作,将目标检测看作回归问题,直接从图像像素得到边界框坐标和类别概率。不同于faster-rcnn只对某个RP预测,yolov1可以看到整张图像,所以预测错误的概率是faster-rcnn的一半,yolo v1的预测结果假阳性目标少,精确率高,但是召回率低,定位误差多。(若有疑问,建议补课精确率和召回率)
one-stage实现方式:
将输入图像划分为7*7的栅格,每个栅格预测2个bounding box,每个bounding box包括5个预测值(x,y,w,h,confidence)
confidence=p(object)*IOU

以VOC数据集为例,一共20个类别,最终输出7*7*(2*5+20)=7*7*30个tensor。
网络结构受图像分类模型GoogLeNet的启发,有24个卷积层,后面是2个全连接层。隐藏层部分使用1×1降维层,后面接3×3卷积层。最终输出是7×7×30的预测张量。(由于使用了全连接层,不支持输入灵活尺寸)

损失函数:
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这三个方面达到很好的平衡。
v1 loss:
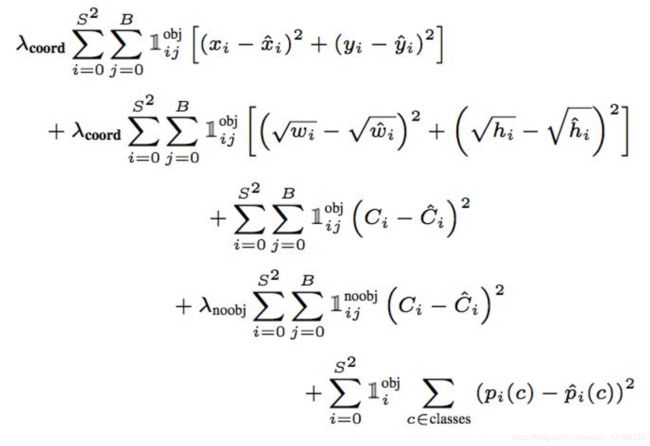
前两项是位置的损失函数,宽高开根号,是为了强化小目标的损失。
比如:小目标:w_pre=10,w_gt=20
大目标:w_pre=100,w_gt=110
显然小目标检测得更差一些。若不开根,二者损失值一样(20-10)^2=(110-100)^2 , 开根后
 ,相当于强化了小目标的损失。
,相当于强化了小目标的损失。
第三、四项分别是含有目标的bounding box的confidence和不含目标的bounding box的confidence损失。大部分边界框内是没有目标的,会造成loss的不平衡,所以对不含目标的bounding box加权![]() =0.5。
=0.5。
最后一项是分类概率损失。
v1的回归损失、置信度损失和分类损失使用的均是MSE,v3回归损失仍是MSE, 而类别和置信度的损失是交叉熵。v4在v3的基础上对回归框进行的loss回归预测,就是基于CIOU的回归函数。
附v3 loss:

YOLO V2
YOLO V2 主要解决yolo v1定位误差多、召回率低的问题。
相较于v1的几点改进:
1. 增加BN层,移除dropout层,这一操作使mAP增加2%
2. 使用高分辨率的分类器,yolov1使用224*224的输入预训练,然后将分辨率提高到448*448在检测器上微调。对于目标检测任务,通常分辨率越高最后得到的结果越接近预期。但是切换分辨率,检测器可能难以快速适应高分辨率。yolov2使用448*448的分辨率微调分类网络(10个epoch),使模型在检测数据集上finetune之前已经适用高分辨率输入。
3. 增加anchor box, yolov1用全连接预测bbox的位置坐标,YOLOv2借鉴了Faster R-CNN中RPN网络的anchor box策略,移除了YOLOv1中的全连接层,采用了卷积和anchor boxes来预测边界框,提高定位精度。其中值得一提的一个trick,检测模型的输入不是448*448,而是416*416,因为经过32倍的下采样,416*416的输出特征图是13*13的奇数维度,这样可以很方便的寻找到中心点,对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。所以在YOLOv2设计中要保证最终的特征图有奇数个维度。yolov1只预测7*7*2=98个框,增加anchor后,v2预测的边框数为13*13*anchor_num,map由69.5%降至69.2%,但是召回率由81%提高到88%
4. 使用聚类的方法得到anchor的维度,在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,带有一定的主观性。如果选取的先验框维度比较合适,那么模型更容易学习,从而做出更好的预测。因此,YOLOv2对训练集的标签使用k-means聚类确定边界框维度。
5. 直接位置预测
YOLO V3
引入FPN,解决小目标检测效果不好的问题,backbone使用darknet53, 分类器由softmax改为sigmod