目标检测资源合集
文章目录
-
- 1. RCNN系列
-
- 1. R-CNN
-
- 1. R-CNN在当时的影响
- 2. R-CNN的流程
- 3. R-CNN框架
- 4. R-CNN存在的问题
- 2. fast R-CNN
-
- 1. 算法效果
- 2. 算法流程
- 3. Fast R-CNN框架
- 3. faster R-CNN
-
- 1. 算法效果
- 2. 算法流程
- 3. RPN网络
- 4. Faster R-CNN 框架
- 2. SSD
-
- 1. 算法效果
- 2. faster r-cnn存在的问题
- 3. SSD网络
-
- 1. 在不同特征尺度上预测不同尺度的目标
- 2. VGG-16模型
- 3. Default Box的设计
- 4. Predictor的实现
- 5. 正负样本的选取
- 6. 损失的计算
- 3. YOLO系列
-
- 1. YOLOv1
-
- 1. 网络原理
- 2. 网络结构
- 3. 损失函数(用 sum-squared error
- 2. YOLOv2(YOLO9000)
-
- 1. 创新点
- 2. YOLOv2模型框架
- 3. YOLOv3
-
- 1. 网络结构
- 2. 目标边界框的预测
- 3. 正负样本的匹配
- 4. 损失的计算
- 4. YOLOv3实现
-
- 1. Mosaic
- 2. SPP模块
- 3. CIoU Loss
- 4. Focal loss
- 5. YOLOv3 SPP源码解析(pytorch版)
- 6. YOLOv4
-
- 6.1 网络结构
- 6.2 优化策略
- 7. YOLOv5
-
- 7.1 网络结构
- 7.2 训练策略
- 7.3 损失计算
- 8. YOLOX
-
- 8.1 网络结构
1. RCNN系列
其中包括:RCNN、Fast-RCNN、Faster-RCNN一些网路结构、原理的讲解。
参考链接:https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter09_computer-vision/9.8_rcnn
视频:https://www.bilibili.com/video/BV1af4y1m7iL?p=1
资料:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/course_ppt
这里对于原资料做了一些笔记以及截屏梳理,便于自己学习,不作商业用途。版权归上述视频和资料。
感谢原作者:https://blog.csdn.net/qq_37541097?type=blog
1. R-CNN
1. R-CNN在当时的影响
2. R-CNN的流程

- 候选区域的生成

- 对每个候选区域, 使用深度网络提取特征

- 特征送入每一类的SVM分类器, 判定类别


- 使用回归器精细修正候选框位置

3. R-CNN框架

4. R-CNN存在的问题

2. fast R-CNN
1. 算法效果
2. 算法流程

注:提取整张图片的特征图是比较大的改进点,还有就是POI pooling层。
-
一次性计算整张图像特征

-
训练数据的采样(正负样本)
还需要负样本,从2000个候选框中采集64个框去训练,其中包括正样本和负样本,正样本是与真实目标边界框IOU大于0.5的候选框,负样本是与真实目标边界框IOU在[0.1, 0.5)之间的候选框。
并不是取ss得到的所有候选框去训练,只是采样了一部分去训练。 -
RoI Pooling Layer

-
分类器

-
回归器


-
损失函数



3. Fast R-CNN框架

3. faster R-CNN
1. 算法效果
2. 算法流程

3. RPN网络

256-d:意味着backbone输出的特征向量的深度channel。

-
关乎感受野


-
训练数据的采样(正、负样本)
随机采样256个anchors框,正负样本为1:1,如果正样本少于128个anchors框,则用负样本来填充。
定义正样本为anchor和GT框的IOU大于0.7,如果不够,则找和GT框IOU最大的anchor为正样本。
定义负样本为anchor和GT框的IOU大于0.3。 -
损失函数

分类损失可以是softmax也可以是二值交叉熵,如果是二值交叉熵则为k个scores。



-
Fast R-CNN 多类损失函数跟之前的Fast R-CNN一样。
-
Faster R-CNN训练过程

4. Faster R-CNN 框架

2. SSD
参考视频:https://www.bilibili.com/video/BV1fT4y1L7Gi?spm_id_from=333.999.0.0
1. 算法效果
2. faster r-cnn存在的问题

3. SSD网络
1. 在不同特征尺度上预测不同尺度的目标
步距为2的时候,paddding为1,步距为1的时候,padding为0。
2. VGG-16模型

3. Default Box的设计


4. Predictor的实现
使用卷积核为3X3来实现,个数为以下。

注意:这里生成边界框回归参数与faster rcnn有区别,后者是生成4c * k个,也就是说每个anchor对于每个类别都会生成回归框,而这里不关注类别,只生成4k个。
5. 正负样本的选取
正样本匹配与faster rcnn类似
负样本:

6. 损失的计算


定位损失和fasterrcnn一样
3. YOLO系列
1. YOLOv1
视频:https://www.bilibili.com/video/BV1yi4y1g7ro/?spm_id_from=trigger_reload
csdn: https://blog.csdn.net/qq_37541097/article/details/103482003
1. 网络原理
- 将一幅图像分为ss(77)个的网格grid cell,然后目标的中心点落入哪个cell,该cell就负责预测这个目标
- 每个网络要预测B(2)个bounding box和C个类别的分数, 每个bounding box包含4个位置信息,和confidence值。其中要注意,预测的bounding box包含的信息分别为x, y, w, h和confidence,x,y是相对于grid cell的相对位置,w,h是相对于整图的相对位置。confidence表示预测的bbox和真实的bbox的IOU,值为 有目标且为该类的概率 * IOU


2. 网络结构


3. 损失函数(用 sum-squared error
- bounding box损失
- confidene 损失
- class损失

限制:
- 对比较密集的小目标检测效果差
- 新的尺寸的目标效果差
- 主要问题预测不准
2. YOLOv2(YOLO9000)
1. 创新点
- 新增Batch Normalization:提升2%map
- High Resolution Classifier :更高分辨率的更大(448X448,以前是224X224)的输入尺寸,提升4%
- Convolutional With Anchor Boxes:引入anchor boxes 提升7%召回率
- Dimension Clusters: k-means聚类来获得anchors
- Direct location prediction 目标边界框预测的尝试

- Fine-Grained Features
通过passthrough layer融合earlier layer的信息,提升1%。

- Multi-Scales Training
采用32的倍数预设 多尺度训练,每迭代10个batches ,会有个新的图像尺寸。
2. YOLOv2模型框架
Darknet-19
3. YOLOv3
参考:
https://blog.csdn.net/YMilton/article/details/120268832?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164821528916782089316900%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164821528916782089316900&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-3-120268832.142v5pc_search_result_cache,143v6control&utm_term=yolox%E7%BD%91%E7%BB%9C%E7%BB%93%E6%9E%84&spm=1018.2226.3001.4187
1. 网络结构

Top-1是指预测结果中分数最高的那一类别和实际类别一致的准确率,Top-5是指预测结果中排名前5的类别中有一个和实际类别相符的准确率
Backbone是 Darknet-53,没有最大池化层,通过卷积层来下采样。
2. 目标边界框的预测

- 需要预测的是 tx, ty, tw, th。其中 cell的宽高是1(因为最后是通过一个1X1的卷积层去预测特征层上所有信息的),cx,cy是这个cell左上角的坐标,pw,ph代表anchor框的宽高,如上面四个公式,可以得出预测框中心的坐标以及宽高。
- 实线代表预测框,虚线代表anchor框。
- 1X1的卷积层滑动到这个窗口的时候,它会针对每个anchor模板预测4个回归参数和confidence和每个类别的score。
- 预测框的中心不会超出该cell,作者说能加快收敛。
3. 正负样本的匹配

文章解读:有几个GT目标就有几个正样本。
代码解读:
- 首先计算GT和anchor模板的iou值,大于0.3的算匹配成功;
- GT对应到特征层中,GT中心点预测在哪个cell中,那么这个cell对应的anchor模板2就是正样本;
- 如果3个anchor模板都大于指定阈值,那么这3个anchor模板都认为是正样本;
4. 损失的计算

-
置信度损失,这也是分类损失

二值交叉熵
ci是个预测值,通过sigmoid来激活,ci_hat是最终的预测值; -
类别损失

二值交叉熵:需要注意的是,预测最后的概率是(0, 1),但每类之前的概率是独立的,相加并不会等于1,然而softmax处理后各类别的概率相加才会等于1。 -
定位损失

对于每个正样本都去计算定位损失,然后求和。
4. YOLOv3实现
1. Mosaic
Mosaic图像增强的优点:
- 增加了数据的多样性
- 增加目标个数
- BN能一次性统计多张图片的参数:
BN是求每个特征层的均值和方差,batch size 越大越好。因为是拼接的图,所以一张图相当于四张图的均值和方差信息,有利于BN层的计算。
2. SPP模块

每个通路出来的feature map的尺寸是一样的,因为都先经过了padding,concatenate在深度上进行拼接。
- 有没有必要每个分支都加SPP结构

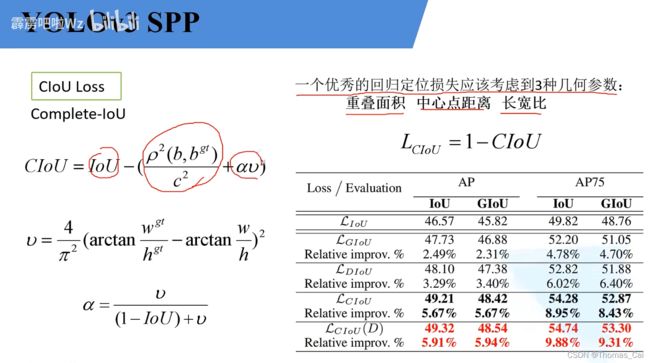
3. CIoU Loss

- IoU Loss

- GIoU Loss

Ac等于外接矩形的面积,u等于两个框的并集。
缺点:

- DIoU Loss (Distance-IoU)
LIoU的缺点:慢的收敛
GIoU的缺点:不准确的回归


- CIoU Loss
4. Focal loss
-
为了应对正负样本不均衡的问题
-
focal loss为什么会那么好呢?


阿尔法只是一个超参,不是正负样本的比例。

当引入阿尔法的时候,只能平衡正负样本。这里引入的新的(1-pt)的伽马次方,可以降低简单样本的权重,聚焦于难分的负样本。 -
最终版:


对于简单样本,可以大幅度的降低损失权重,更集中的去学习难分的样本。
缺点:易受噪音的干扰。
5. YOLOv3 SPP源码解析(pytorch版)
视频:https://www.bilibili.com/video/BV1t54y1C7ra?p=1
代码:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_object_detection/yolov3_spp
6. YOLOv4
参考讲解:https://www.bilibili.com/video/BV1NF41147So?spm_id_from=333.999.0.0
参考博文:https://blog.csdn.net/qq_37541097/article/details/123229946?spm=1001.2014.3001.5502
6.1 网络结构


- Backbone: CSPDarknet53
CSP结构的好处:
- 加强CNN的学习能力
- 移除计算瓶颈
- 减少现存的使用
- Neck: SPP, PAN(包括FPN)
SPP: Spatial Pyramid Pooling
解决多尺度的问题
关于SPP(Spatial Pyramid Pooling)模块之前讲YOLO系列网络详解时详细介绍过,SPP就是将特征层分别通过一个池化核大小为5x5、9x9、13x13的最大池化层,然后在通道方向进行concat拼接在做进一步融合,这样能够在一定程度上解决目标多尺度问题。
PAN: Path Aggregation Network
结构其实就是在FPN(从顶到底信息融合)的基础上加上了从底到顶的信息融合。
- Head: YOLOv3
6.2 优化策略
- Eliminate grid sensitivity
grid cell处针对每一个anchor来预测相应的目标回归框、object name以及每个类别的分数。引入scale来使得预测框中点可以触及到grid cell的边界,增加了正样本。
- Mosaic data augmentation
将四张不同的图片按照不同的规则拼接在一起,扩充训练样本多样性。
- IoU threshold(match posotive samples)
扩展相邻的grid cell,配合Eliminate grid sensitivity增加正样本。
- Optimizered Anchors
对yolov3的anchor模板对于 512*512 重新生成新的 anchor模板
- CIOU
改变计算loss的iou的方式
7. YOLOv5
参考讲解:https://www.bilibili.com/video/BV1T3411p7zR?spm_id_from=333.999.0.0&vd_source=82b50e78f6d8c4b40bd90af87f9a980b
参考博文:https://blog.csdn.net/qq_37541097/article/details/123594351
7.1 网络结构

-
Backbone: New CSP-Darknet53
从yolov4的CSPDarknet53 —> New CSP-Darknet53
这里主要是把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层 -
Neck: SPPF, New CSP-PAN
从SPP —> SPPF: 将SPP改成串行的方式,结果一样,但后者速度快2倍,详见链接。
PAN(包括FPN) —> New CSP-PAN: 在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP,每个C3模块里都含有CSP结构。 -
Head: YOLOv3,没变
7.2 训练策略
- Multi-scale training(0.5~1.5X) 多尺度训练
- AutoAnchor(For training custom data) 对于新的数据集开启会设定适应的anchor
- Warmup and Cosine LR scheduler 从小的学习率慢慢到初始学习率,cosine的策略降低学习率
- EMA 增加动量,更新参数更平滑
- Mixed precison 混合训练
- Evolve hyper-parameters 超参
7.3 损失计算
classes loss/objectness loss/location loss 具体参考原博
还有有关平衡不同尺度的损失、消除Grid敏感度、匹配正样本(Build Targets) 也请参考原博,因为写的真的很清楚,respect!
8. YOLOX
参考讲解:https://www.bilibili.com/video/BV1JW4y1k76c?spm_id_from=333.999.0.0
参考博文:https://blog.csdn.net/qq_37541097/article/details/125132817
8.1 网络结构

优化器用SGD
lr为0.01
weight decay为0.0005
对标的yolov3:
backbone: darknet53 + SPP
data aug: randomHorizontalFlip、ColorJitter、multi-scale
没有 randomresizedCrop
创新点:
-
Decoupled head(解耦头)
因为分类和回归任务是有冲突的,并增加了IOU计算的branch,在后处理可以不用nms,
效果:收敛更快,且最后精度更高。 -
更强的数据增强
mosaic和mixup 来进行数据增强
- mosaic
ultralytics-yolov3使用过,对四张图进行拼接,标签也进行处理 - mixup
两张图混到一起,标签也混到一起
-
Anchor-free
对于锚框的机制的变化,缺点一:锚框不好选取,缺点二:锚框增加了检测头的复杂度,并增加了每张图片预测的数量。
anchor free可以减少设计的参数,代表性FCOS、OTA -
multi positives
-
SimOTA
这个要注意,将匹配正负样本的过程看成一个最优传输问题。这是yolox非常有特色的地方,详情请看参考链接。 -
NMS free(optional)