CNN中添加HOG特征的pytorch实现——基于Alexnet
CNN中添加HOG特征的pytorch实现——基于Alexnet
几天前花了差不多两天时间基本实现了这个需求,经历了从一开始的毫无头绪,到最后对CNN模型 (加载数据集和数据流向) 和HOG特征有了更进一步的理解,实现需求之后又杂七杂八的看了一些相关的文章(第一次找论文看,精准的寻找高质量相关论文也是有技巧的~),看的也是似懂非懂,有些论文中涉及到的一些概念和技术以前没有了解过,也会影响对设计思想的理解,所以想要借鉴其他场景下的一些创新也并非易事,再者,也发现了对CNN中涉及到的一些机器学习的基础知识掌握也不好,对CNN中基础的概念和原理还需要进一步巩固。本文目的在于梳理和记录一下实现需求的过程中的思考和逻辑。
HOG
一开始的想法就是无论在模型的哪里或者如何传进去所获得的HOG特征,首先得把HOG特征向量准备好,所以先从了解HOG提取传统特征开始入手。
经过查询了解之后发现,可以使用skimage中提供的hog函数进行特征提取,那么接下来的问题就是了解此函数的传入参数和返回值,以及它们的含义(可以去看源码),当将 visualize=False 时,返回值就是一维的浮点数array,代表传入图片的HOG特征。
使用cv2读取图片,就需要图片的路径,初步的想法就是一次性从.csv中将所有图片的路径保存在数组中,然后就可以遍历数组将所有图片的HOG特征保存在二维array中,当这些都做完之后就发现了问题,由于model在forward时传入的的图片是通过dataloader打乱之后随机组合成的mini_batch,所以在拼接的时候,按数据集中图片的顺序保存的HOG特征就没办法和对应图片的深度特征进行拼接了,所以需要以别的方式获取到图片的路径,以保证每张图片的HOG特征和深度特征的拼接是一一对应的。
from skimage import feature as ft
import cv2
# def Get_Path(dataPath): # 从数据集(.csv文件)中一次性获取每张图片的绝对路径
# csvFile = open(dataPath, "r")
# reader = csv.reader(csvFile)
# data= []
# for item in reader:
# if reader.line_num == 1:
# continue
# data.append(item[0])
# csvFile.close()
# data = np.array(data)
# return data
def Get_HOG_NP(HOG_data):
HOG_NP = []
for path in HOG_data:
#print(path)
path = str(path)
img = cv2.cvtColor(cv2.imread(path), cv2.COLOR_BGR2GRAY)
img = cv2.resize(img, (224,224))
#print (img.shape)
#normalised_blocks, hog_image = hog(img, orientations=9, pixels_per_cell=(8, 8), cells_per_block=(8, 8), block_norm='L2-Hys',visualize=True)
features = ft.hog(img,
orientations=9,
pixels_per_cell=[16,16],
cells_per_block=[2,2],
visualize=False,
feature_vector= True)
# print( type(features) )
# print(features.shape)
HOG_NP.append(features)
HOG_NP = np.array(HOG_NP)
# print(HOG_NP.shape)
# print(HOG_NP.dtype)
# pca = PCA(n_components=64,copy=False)
# HOG_NP = pca.fit_transform(HOG_NP)
# lda = LDA(n_components=1)
# HOG_NP = lda.fit_transform(HOG_NP,labels)
return HOG_NP
Dataloader
由于模型中forward的图片数据是dataloader 随机组成 的mini_batch,所以我们就尝试一下能否从mini_batch组合的过程中获得每张图片的路径,这就到了第二个关键部分——模型的数据集加载过程
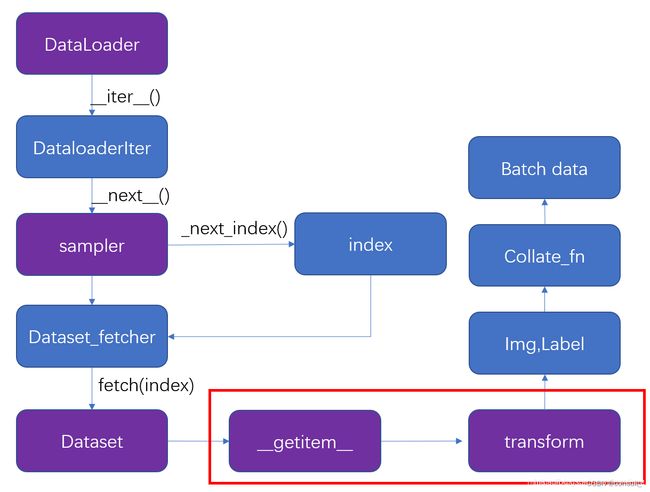
了解了数据记载的全过程,就会发现只需要在重载__getitem__()方法时,将每一张处理过之后的图片同此图片的路径一同打包进Mini_batch即可。
data_transform = transforms.Compose( [lambda x: Image.open(x).convert('RGB'),
#transforms.CenterCrop(300),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
class MyDataSet(Dataset): #两个私有成员函数必须被重载:__len__() 和 __getitem__() 方法
def __init__(self,mode,data,labels):
self.data = data **#此时 data 还是图片的路径**
self.labels = labels
self.transforms = data_transform
def __getitem__(self, index):
path = self.data[index] # 保存此图片的路径
data = self.transforms(self.data[index]) # 拿到此图片路径后进行transform
label = torch.tensor(int(self.labels[index]))
return data,label,path #将准备好的要传进forward里的图片数据 同 此图片的路径一同打包进Mini_batch
#这样就能保证Mini_batch中 图片数据和路径是对应的
def __len__(self):
return len(self.labels)
def getDataSet(mode,dataPath):
csvFile = open(dataPath, "r")
reader = csv.reader(csvFile)
data= []
label = []
for item in reader:
if reader.line_num == 1:
continue
data.append(item[0])
label.append(int(item[1]))
csvFile.close()
data = np.array(data)
label = np.array(label)
dataSet = MyDataSet(mode,data,label) # 获取到每个图片的路径和标签
return dataSet
train_dataset = getDataSet("train","/home/xb/SARShip/openSARShip/train_old.csv") # 传入.csv文件路径
cat
接下来就是一些cat前的准备工作了,将array转成能在GPU上运算的张量,数据类型也转换与深度特征数据一致等,然后就可以在每一次迭代中前向传播时尽情的拼接了~~
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size = batch_size,
num_workers=0)
for step, data in enumerate(train_loader):
images, labels, path = data # Mini_batch中images的图片和path中路径一一对应
optimizer.zero_grad()
#print( type(path) )
HOG_data = Get_HOG_NP(path)
data2 = torch.as_tensor(HOG_data, dtype=torch.float, device=device)
logits = net(images.to(device),data2 )
def forward(self, x, data):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # 展平后再传入全连接层
# print(x.shape)
# print(data.shape)
x = torch.cat((x,data),1) # 按列拼接,注意记得修改相应的网络参数
#print( x.shape )
x = self.classifier(x)
return x
注:
由于数据集中的图片是一些大小不同的灰度图,所以,我们如果不像处理用于卷积的图片那样预处理图片大小的话,会得到长度不同的HOG特征向量,这样是没办法用于拼接的,因为模型中全连接层的维度是固定不变的,所以在HOG之前记得resize,或者在HOG之后对特征向量进行降维到统一维度(PCA)。