PRML读书会第五期——概率图模型(Graphical Models)【中】
注:这是全文的第二部分,前后文传送门:
PRML读书会第五期——概率图模型(Graphical Models)【上】
PRML读书会第五期——概率图模型(Graphical Models)【下】
算法推导
符号与规定
为了保证行文中符号的一致性,在推导中采取如下的符号体系:

与上文一致地, X X X代表全体随机变量, x ( x i ) x(x_i) x(xi)代表某一随机变量。此处,我们的任务为求变量 x x x的边缘概率。
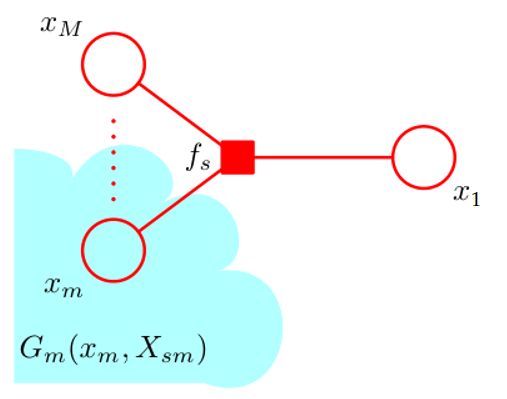
由于算法在具有树结构的因子图上进行,我们考虑每一个与 x x x相连的因子, x x x通过这些因子与图的其它部分相关联。我们记这些因子节点为 f S a , f S b , ⋯ f_{S_a},f_{S_b},\cdots fSa,fSb,⋯.一般的,我们将任一 f S n f_{S_n} fSn视作 f S f_S fS以简化讨论。于此同时,我们规定 X S a , X S b , ⋯ X_{S_a},X_{S_b},\cdots XSa,XSb,⋯,它们是通过对应因子节点 f S a , f S b , ⋯ f_{S_a},f_{S_b},\cdots fSa,fSb,⋯与 x x x相连的子树中的所有节点对应的随机变量组成的集合,如图所示。同样的,我们将任一 X S n X_{S_n} XSn视作 X S X_S XS.
在此基础上我们定义 x x x关于 f S f_S fS的邻居 x 1 , x 2 , ⋯ , x M x_1,x_2,\cdots,x_M x1,x2,⋯,xM,因子 f S f_S fS正是定义在 x x x与它关于 f S f_S fS的邻居们构成的集合上的。
进一步地,我们将 X S X_S XS中通过邻居节点 x m x_m xm与 f S f_S fS相连的子树中的所有节点对应的随机变量组成的集合记作 X S m X_{Sm} XSm,如图中的 X S 1 X_{S1} XS1.与刚才定义 X S X_S XS时类似,我们在 x m x_m xm的基础上定义 f l f_l fl与 X m l X_{ml} Xml:与 x m x_m xm直接相连的因子节点,除 f S f_S fS外,其余因子节点分别记为 f l a , f l b , ⋯ f_{l_a},f_{l_b},\cdots fla,flb,⋯,并一般化地记为 f l f_l fl;通过 f l f_l fl与 x m x_m xm相连的子树中的所有节点对应的随机变量的集合记作 X m l X_{ml} Xml。
于此同时,我们用 n e ne ne来记邻居构成的集合。对于变量节点 x i x_i xi来说, n e ( x i ) ne(x_i) ne(xi)是与 x i x_i xi相连的所有因子节点的集合;对于因子节点 f S f_S fS来说, n e ( f S ) ne(f_S) ne(fS)是所有与 f S f_S fS相连的变量节点的集合。特别的,当我们说节点集合 S ∈ n e ( x i ) S\in ne(x_i) S∈ne(xi)时, S S S实际上指的是上文中规定的 f S f_S fS对应的 X S X_S XS对应的节点集合,即 S S S是由通过因子节点 f S f_S fS与 x x x相连的子树中的所有节点构成的。
除此之外,我们使用省略号来略去与通过因子节点与讨论对象相连的子树部分。我们还将在变量和变量集合的层面上定义一些函数,如 F S F_S FS是由因子节点 f S f_S fS关联起来的随机变量在联合概率中的因子之积,具体来说是联合概率中涉及与 f S f_S fS对应地 X S X_S XS与 x x x的所有因子;而 G m G_m Gm是通过 x m x_m xm对应的节点(包括 x m x_m xm本身)从而与因子节点 f S f_S fS关联起来的随机变量在联合概率中的因子之积,具体来说是联合概率中涉及与 x m x_m xm对应地 X S m X_{Sm} XSm及 x m x_m xm的所有因子;而其余的函数将在具体推导中给出相应的定义。
总结一下,小写字母 x x x通常代表了随机变量,大写字母 X X X通常代表了变量集合,而 X S X_S XS的下标 S S S为随机变量集合在图中对应的节点集合,对于函数 G , F G,F G,F,可以简单的通过它们所接受的自变量来判断它们代表了联合概率中的哪一部分因子( F F F面向因子节点进行定义,而 G G G面向变量节点进行定义)。算法的具体推导过程并不是十分复杂,如果忘记了记号的具体含义,可以参照上述图示。
注:
原书中仅通过图示的手段给出了部分记号的含义,容易使读者感到一头雾水;尽管将所有的记号全部给出会给读者带来一定的心理压力,但配合综合图示,在感到困惑时能够有迹可循
或是迫于时间压力,主讲人仅给出了半个算法的部分推导。这里将按照书本顺序将其补全
书中此处采用小写s来指代变量集合,为了与前文风格保持一致,采用了大写S,具体算式可能与书中摘录的图示稍有出入
下文为连续的推导过程,处于简洁考虑,所有式子默认采用 ( ∗ ) (*) (∗)标注,式前的 ( ∗ ) (*) (∗)默认指上一个式子。
推导过程
先明确我们的目标:求边缘概率 p ( x ) p(x) p(x).由加法原理,我们有
p ( x ) = ∑ X ∖ x p ( X ) p(x)=\sum\limits_{X\setminus x}p(X) p(x)=X∖x∑p(X)
引入因子图中因子分解的概念,我们有
p ( X ) = ∏ S f S ( X S ) p(X)=\prod\limits_Sf_S(X_S) p(X)=S∏fS(XS)
此处对因子 S S S的划分较为自由。结合具体任务,我们选定如下的划分方式
p ( X ) = ∏ S ∈ n e ( x ) F S ( x , X S ) p(X)=\prod\limits_{S\in ne(x)}F_S(x,X_S) p(X)=S∈ne(x)∏FS(x,XS)
事实上,在上述对 X S X_S XS的定义过程中已经蕴含了这种划分的背后的思想。由于算法在具有树结构的因子图上进行, x x x通过与之相连的因子节点与整张图其余部分相连;换句话说,对 ∀ S ∈ n e ( x ) \forall S\in ne(x) ∀S∈ne(x),即 S S S取遍 f S a , f S b , ⋯ f_{S_a},f_{S_b},\cdots fSa,fSb,⋯时, F S ( x , X S ) F_S(x,X_S) FS(x,XS)也将取遍联合概率中的所有因子;自然而然地, F S F_S FS定义在 { x } ∪ X S \{x\}\cup X_S {x}∪XS上,指代了涉及这些随机变量的因子。
将此处的 p ( X ) p(X) p(X)带入边缘概率的表达式,得
p ( x ) = ∑ X ∖ x ∏ S ∈ n e ( x ) F S ( x , X S ) ( ∗ ) p(x)=\sum\limits_{X\setminus x}\prod\limits_{S\in ne(x)}F_S(x,X_S)(*) p(x)=X∖x∑S∈ne(x)∏FS(x,XS)(∗)
既然 S S S能将 x x x外的节点取遍,我们自然可以利用 S S S来拆解求和号
( ∗ ) = ∑ X S a ∑ X S b ⋯ ∑ X S n ∏ S ∈ n e ( x ) F S ( x , X S ) ( ∗ ) (*)=\sum\limits_{X_{S_a}}\sum\limits_{X_{S_b}}\cdots\sum\limits_{X_{S_n}}\prod\limits_{S\in ne(x)}F_S(x,X_S)(*) (∗)=XSa∑XSb∑⋯XSn∑S∈ne(x)∏FS(x,XS)(∗)
将累乘写开,利用乘法分配律作进一步的化简
( ∗ ) = ∑ X S a ∑ X S b ⋯ ∑ X S n F S a ( x , X S a ) F S b ( x , X S b ) ⋯ F S n ( x , X S n ) = ∑ X S a F S a ( x , X S a ) ∑ X S b F S b ( x , X S b ) ⋯ ∑ X S n F S n ( x , X S n ) = [ ∑ X S a F S a ( x , X S a ) ] [ ∑ X S b F S b ( x , X S b ) ] ⋯ [ ∑ X S n F S n ( x , X S n ) ] = ∏ S ∈ n e ( x ) ∑ X S F S ( x , X S ) (*)=\sum\limits_{X_{S_a}}\sum\limits_{X_{S_b}}\cdots\sum\limits_{X_{S_n}}F_{S_a}(x,X_{S_a})F_{S_b}(x,X_{S_b})\cdots F_{S_n}(x,X_{S_n})\\ =\sum\limits_{X_{S_a}}F_{S_a}(x,X_{S_a})\sum\limits_{X_{S_b}}F_{S_b}(x,X_{S_b})\cdots\sum\limits_{X_{S_n}}F_{S_n}(x,X_{S_n})\\ =\Big[\sum\limits_{X_{S_a}}F_{S_a}(x,X_{S_a})\Big]\Big[\sum\limits_{X_{S_b}}F_{S_b}(x,X_{S_b})\Big]\cdots\Big[\sum\limits_{X_{S_n}}F_{S_n}(x,X_{S_n})\Big]\\ =\prod_{S\in ne(x)}\sum\limits_{X_S}F_S(x,X_S) (∗)=XSa∑XSb∑⋯XSn∑FSa(x,XSa)FSb(x,XSb)⋯FSn(x,XSn)=XSa∑FSa(x,XSa)XSb∑FSb(x,XSb)⋯XSn∑FSn(x,XSn)=[XSa∑FSa(x,XSa)][XSb∑FSb(x,XSb)]⋯[XSn∑FSn(x,XSn)]=S∈ne(x)∏XS∑FS(x,XS)
其中最后一步利用累乘符号对结果进行简化。
我们已经得到了一个相对简单的结果,我们作定义
μ f S → x ( x ) ≜ ∑ X S F S ( x , X S ) \mu_{f_S\to x}(x)\triangleq\sum\limits_{X_S}F_S(x,X_S) μfS→x(x)≜XS∑FS(x,XS)
从上述过程中我们可以看出,若应用将乘法分配律的步骤称为变量消除法,那么每一个因式中, μ f S → x ( x ) \mu_{f_S\to x}(x) μfS→x(x)携带了整个式子中与 f S f_S fS有关的全部“信息",通过累乘的方式将它们传递到我们的目标中,如图:
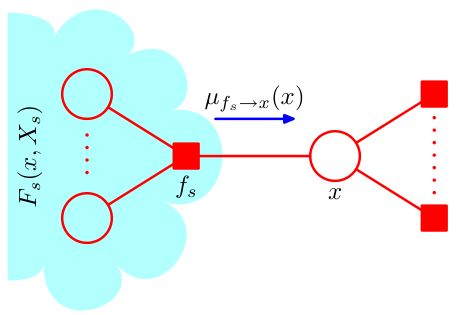
这便是从因子节点到变量节点的”信念传播“。
由于 F S F_S FS还可以继续化简,我们将 F S F_S FS中的因子展开出来,有
F S ( x , X S ) = f S ( x 1 , x 2 , … , x M ) G 1 ( x 1 , X S 1 ) G 2 ( x 2 , X S 2 ) ⋯ G M ( x M , X S M ) F_S(x,X_S)=f_S(x_1,x_2,\dots,x_M)G_1(x_1,X_{S1})G_2(x_2,X_{S2})\cdots G_M(x_M,X_{SM}) FS(x,XS)=fS(x1,x2,…,xM)G1(x1,XS1)G2(x2,XS2)⋯GM(xM,XSM)
从定义的图示中我们能很明显看出它的正确性: F S ( x , X S ) F_S(x,X_S) FS(x,XS)囊括了 { x } ∪ X S \{x\}\cup X_S {x}∪XS对应的节点,这些节点包括了 f S f_S fS本身涵盖的节点(即 x x x与 x x x关于 f S f_S fS的邻居节点),还有与这些邻居节点相连的子树部分。由于条件独立性的存在,在 { x } ∪ X S \{x\}\cup X_S {x}∪XS中, x x x仅与这些邻居节点有关,而与其余的子树无关,故可将这些子树部分的因子写作对应 G m ( x m , X S M ) G_m(x_m,X_{SM}) Gm(xm,XSM)的乘积。
将上述分解形式带入 μ f S → x ( x ) \mu_{f_S\to x}(x) μfS→x(x)得
μ f S → x ( x ) = ∑ X S f S ( x 1 , x 2 , … , x M ) G 1 ( x 1 , X S 1 ) G 2 ( x 2 , X S 2 ) ⋯ G M ( x M , X S M ) ( ∗ ) \mu_{f_S\to x}(x)=\sum\limits_{X_S}f_S(x_1,x_2,\dots,x_M)G_1(x_1,X_{S1})G_2(x_2,X_{S2})\cdots G_M(x_M,X_{SM})(*) μfS→x(x)=XS∑fS(x1,x2,…,xM)G1(x1,XS1)G2(x2,XS2)⋯GM(xM,XSM)(∗)
根据上述讨论,对 X S X_S XS进行拆分
X S = { x 1 } ∪ { x 2 } ∪ ⋯ ∪ { x M } ∪ X S 1 ∪ X S 2 ∪ ⋯ ∪ X S M X_S=\{x_1\}\cup\{x_2\}\cup\cdots\cup\{x_M\}\cup X_{S1}\cup X_{S2}\cup\cdots\cup X_{SM} XS={x1}∪{x2}∪⋯∪{xM}∪XS1∪XS2∪⋯∪XSM
在此基础上利用分配律对原式进行化简
( ∗ ) = ∑ x 1 ⋯ ∑ x M ∑ X S 1 ⋯ ∑ X S M f S ( x 1 , x 2 , … , x M ) G 1 ( x 1 , X S 1 ) G 2 ( x 2 , X S 2 ) ⋯ G M ( x M , X S M ) = ∑ x 1 ⋯ ∑ x M f S ( x 1 , x 2 , … , x M ) ∑ X S 1 G 1 ( x 1 , X S 1 ) ⋯ ∑ X S M G M ( x M , X S M ) = ∑ x 1 ⋯ ∑ x M f S ( x 1 , x 2 , … , x M ) [ ∑ X S 1 G 1 ( x 1 , X S 1 ) ] ⋯ [ ∑ X S M G M ( x M , X S M ) ] = ∑ x 1 ⋯ ∑ x M f S ( x 1 , x 2 , … , x M ) ∏ m ∈ n e ( f S ) ∖ { x } ∑ X S m G m ( x m , X S m ) (*)=\sum\limits_{x_1}\cdots\sum\limits_{x_M}\sum\limits_{X_{S1}}\cdots\sum\limits_{X_{SM}}f_S(x_1,x_2,\dots,x_M)G_1(x_1,X_{S1})G_2(x_2,X_{S2})\cdots G_M(x_M,X_{SM})\\ =\sum\limits_{x_1}\cdots\sum\limits_{x_M}f_S(x_1,x_2,\dots,x_M)\sum\limits_{X_{S1}}G_1(x_1,X_{S1})\cdots\sum\limits_{X_{SM}}G_M(x_M,X_{SM})\\ =\sum\limits_{x_1}\cdots\sum\limits_{x_M}f_S(x_1,x_2,\dots,x_M)\Big[\sum\limits_{X_{S1}}G_1(x_1,X_{S1})\Big]\cdots\Big[\sum\limits_{X_{SM}}G_M(x_M,X_{SM})\Big]\\ =\sum\limits_{x_1}\cdots\sum\limits_{x_M}f_S(x_1,x_2,\dots,x_M)\prod\limits_{m\in ne(f_S)\setminus \{x\}}\sum\limits_{X_{Sm}}G_m(x_m,X_{Sm}) (∗)=x1∑⋯xM∑XS1∑⋯XSM∑fS(x1,x2,…,xM)G1(x1,XS1)G2(x2,XS2)⋯GM(xM,XSM)=x1∑⋯xM∑fS(x1,x2,…,xM)XS1∑G1(x1,XS1)⋯XSM∑GM(xM,XSM)=x1∑⋯xM∑fS(x1,x2,…,xM)[XS1∑G1(x1,XS1)]⋯[XSM∑GM(xM,XSM)]=x1∑⋯xM∑fS(x1,x2,…,xM)m∈ne(fS)∖{x}∏XSm∑Gm(xm,XSm)
其中最后一步用 n e ( f S ) ∖ { x } ne(f_S)\setminus\{x\} ne(fS)∖{x}对这些 x x x关于 f S f_S fS的邻居进行刻画,从而写作累乘形式以化简。注意,因子 G m ( x m , X S m ) G_m(x_m,X_{Sm}) Gm(xm,XSm)依赖于 x m x_m xm,需要 ∑ x m \sum\limits_{x_m} xm∑提供的求和环境,故不可以提到前面去。
仿照前面定义 μ f S → x ( x ) \mu_{f_S\to x}(x) μfS→x(x)的做法,我们作定义
μ x m → f S ( x m ) ≜ ∑ X S m G m ( x m , X S m ) \mu_{x_m\to f_S}(x_m)\triangleq\sum\limits_{X_{Sm}}G_m(x_m,X_{Sm}) μxm→fS(xm)≜XSm∑Gm(xm,XSm)
同样的,我们可以认为 μ x m → f S ( x m ) \mu_{x_m\to f_S}(x_m) μxm→fS(xm)携带了与之关联的子树 X S m X_{S_m} XSm中的全部信息,如图:

这便是变量节点到因子节点的“信念传播”。结合上述因子节点到变量节点的“信念传播”,从图中我们可以直观的理解这一连续的过程。
继续化简 G m ( x m , X S m ) G_m(x_m,X_{Sm}) Gm(xm,XSm),不难发现,以 x m x_m xm为根的子树的结构,与将 x x x作为原树根节点的树结构完全一致。仿照前面的划分,我们有
G m ( x m , X S m ) = ∏ l ∈ n e ( x m ) ∖ f S F l ( x m , X m l ) G_m(x_m,X_{Sm})=\prod\limits_{l\in ne(x_m)\setminus f_S}F_l(x_m,X_{ml}) Gm(xm,XSm)=l∈ne(xm)∖fS∏Fl(xm,Xml)
由于在子树中复现前文的操作,我们需要将 f S f_S fS节点从 n e ( x m ) ne(x_m) ne(xm)中剔除。
同样的,将上述分解形式带入 μ x m → f S ( x m ) \mu_{x_m\to f_S}(x_m) μxm→fS(xm)得
μ x m → f S ( x m ) = ∑ X S m ∏ l ∈ n e ( x m ) ∖ f S F l ( x m , X m l ) ( ∗ ) \mu_{x_m\to f_S}(x_m)=\sum\limits_{X_{Sm}}\prod\limits_{l\in ne(x_m)\setminus f_S}F_l(x_m,X_{ml})(*) μxm→fS(xm)=XSm∑l∈ne(xm)∖fS∏Fl(xm,Xml)(∗)
同样的,我们利用 l l l来拆分求和号,并将累乘写开
( ∗ ) = ∑ X l a ∑ X l b ⋯ ∑ X l n ∏ l ∈ n e ( x m ) ∖ f S F l ( x m , X m l ) = ∑ X l a ∑ X l b ⋯ ∑ X l n F l a ( x m , X m l a ) F l b ( x m , X m l b ) ⋯ F l n ( x m , X m l n ) = ∑ X l a F l a ( x m , X m l a ) ∑ X l b F l b ( x m , X m l b ) ⋯ ∑ X l n F l n ( x m , X m l n ) = [ ∑ X l a F l a ( x m , X m l a ) ] [ ∑ X l b F l b ( x m , X m l b ) ] ⋯ [ ∑ X l n F l n ( x m , X m l n ) ] = ∏ l ∈ n e ( x m ) ∖ f S ∑ X l F l ( x m , X m l ) = ∏ l ∈ n e ( x m ) ∖ f S μ f l → x m ( x m ) (*)=\sum\limits_{X_{l_a}}\sum\limits_{X_{l_b}}\cdots\sum\limits_{X_{l_n}}\prod\limits_{l\in ne(x_m)\setminus f_S}F_l(x_m,X_{ml})\\ =\sum\limits_{X_{l_a}}\sum\limits_{X_{l_b}}\cdots\sum\limits_{X_{l_n}}F_{l_a}(x_m,X_{ml_a})F_{l_b}(x_m,X_{ml_b})\cdots F_{l_n}(x_m,X_{ml_n})\\ =\sum\limits_{X_{l_a}}F_{l_a}(x_m,X_{ml_a})\sum\limits_{X_{l_b}}F_{l_b}(x_m,X_{ml_b})\cdots\sum\limits_{X_{l_n}} F_{l_n}(x_m,X_{ml_n})\\ =\Big[\sum\limits_{X_{l_a}}F_{l_a}(x_m,X_{ml_a})\Big]\Big[\sum\limits_{X_{l_b}}F_{l_b}(x_m,X_{ml_b})\Big]\cdots\Big[\sum\limits_{X_{l_n}} F_{l_n}(x_m,X_{ml_n})\Big]\\ =\prod\limits_{l\in ne(x_m)\setminus f_S}\sum\limits_{X_l} F_l(x_m,X_{ml})=\prod\limits_{l\in ne(x_m)\setminus f_S}\mu_{f_l\to x_m}(x_m) (∗)=Xla∑Xlb∑⋯Xln∑l∈ne(xm)∖fS∏Fl(xm,Xml)=Xla∑Xlb∑⋯Xln∑Fla(xm,Xmla)Flb(xm,Xmlb)⋯Fln(xm,Xmln)=Xla∑Fla(xm,Xmla)Xlb∑Flb(xm,Xmlb)⋯Xln∑Fln(xm,Xmln)=[Xla∑Fla(xm,Xmla)][Xlb∑Flb(xm,Xmlb)]⋯[Xln∑Fln(xm,Xmln)]=l∈ne(xm)∖fS∏Xl∑Fl(xm,Xml)=l∈ne(xm)∖fS∏μfl→xm(xm)
最后同样利用累乘将其合并,而累乘的对象正是上文定义的因子节点到变量节点“信念传播”的形式。上述推导过程如图所示:

至此,Sum-Product算法的主体推导完成。下面对边界进行讨论:
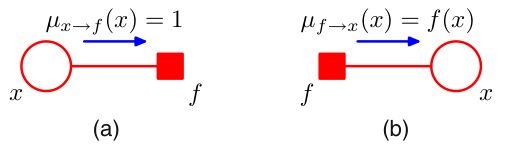
直接带入上述推导结果,不难得出,对于叶型随机变量节点, μ x → f ( x ) = 1 \mu_{x\to f}(x)=1 μx→f(x)=1,而对于叶型因子节点, μ f → x ( x ) = f ( x ) \mu_{f\to x}(x)=f(x) μf→x(x)=f(x).
Sum-Product算法总结如下:
{ p ( x ) = ∏ S ∈ n e ( x ) μ f S → x ( x ) μ f → x ( x ) = ∑ x 1 , ⋯ , x M f ( x , x 1 , ⋯ , x M ) ∏ m ∈ n e ( f ) ∖ x μ x m → f ( x m ) μ x → f ( x ) = ∏ l ∈ n e ( x ) ∖ f μ f l → x ( x ) \left\{\begin{array}{ll} p(x)=\prod\limits_{S\in ne(x)}\mu_{f_S\to x}(x)\\ \mu_{f\to x}(x)=\sum\limits_{x_1,\cdots,x_M}f(x,x_1,\cdots,x_M)\prod\limits_{m\in ne(f)\setminus x}\mu_{x_m\to f}(x_m)\\ \mu_{x\to f}(x)=\prod\limits_{l\in ne(x)\setminus f}\mu_{f_l\to x}(x) \end{array}\right. ⎩ ⎨ ⎧p(x)=S∈ne(x)∏μfS→x(x)μf→x(x)=x1,⋯,xM∑f(x,x1,⋯,xM)m∈ne(f)∖x∏μxm→f(xm)μx→f(x)=l∈ne(x)∖f∏μfl→x(x)
在推导过程中,我们并没有考虑到归一化的问题。事实上,我们可以通过对其中任意一个随机变量进行归一化,从而得到整体共用的归一化常数。
实例
下用实例来验证Sum-Product算法的正确性。
在利用算法进行具体操作时,我们随机选定根节点,既可以时变量节点,又可以是因子节点。从根节点出发,我们先递后归求出所有 μ f S → x \mu_{f_S\to x} μfS→x与 μ x m → f S \mu_{x_m\to f_S} μxm→fS;利用上面总结中的第一条,我们可以利用这些“信息”表达出所有的边缘概率。
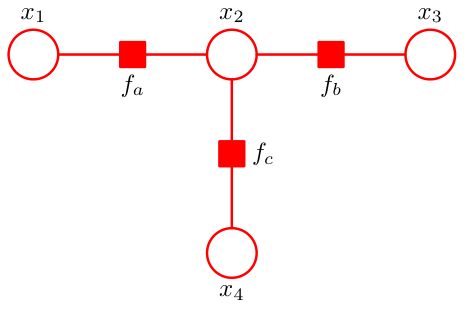
如图,根据因子图的形式,我们写出它联合概率的因子分解
p ~ ( X ) = f a ( x 1 , x 2 ) f b ( x 2 , x 3 ) f c ( x 2 , x 4 ) \tilde{p}(X)=f_a(x_1,x_2)f_b(x_2,x_3)f_c(x_2,x_4) p~(X)=fa(x1,x2)fb(x2,x3)fc(x2,x4)
这里,我们使用 p ~ \tilde{p} p~来指代未归一化的概率。
我们的目的是求解 p ~ ( x 2 ) \tilde{p}(x_2) p~(x2).
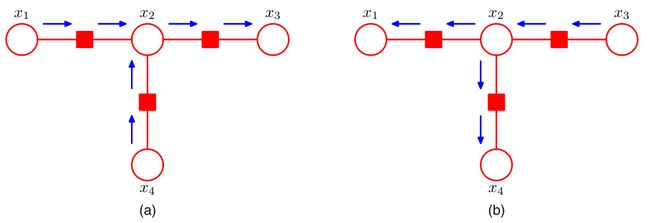
现选定 x 3 x_3 x3作根节点,分别从叶子向根、从根向叶子写出全部的信息:
图(a):叶子 → \to →根
μ x 1 → f a ( x 1 ) = 1 μ f a → x 2 ( x 2 ) = ∑ x 1 f a ( x 1 , x 2 ) μ x 4 → f c ( x 4 ) = 1 μ f c → x 2 ( x 2 ) = ∑ x 4 f c ( x 2 , x 4 ) μ x 2 → f b ( x 2 ) = μ f a → x 2 ( x 2 ) μ f c → x 2 ( x 2 ) μ f b → x 3 ( x 3 ) = ∑ x 2 f b ( x 2 , x 3 ) μ x 2 → f b ( x 2 ) \mu_{x_1\to f_a}(x_1)=1\\ \mu_{f_a\to x_2}(x_2)=\sum\limits_{x_1}f_a(x_1,x_2)\\ \mu_{x_4\to f_c}(x_4)=1\\ \mu_{f_c\to x_2}(x_2)=\sum\limits_{x_4}f_c(x_2,x_4)\\ \mu_{x_2\to f_b}(x_2)=\mu_{f_a\to x_2}(x_2)\mu_{f_c\to x_2}(x_2)\\ \mu_{f_b\to x_3}(x_3)=\sum\limits_{x_2}f_b(x_2,x_3)\mu_{x_2\to f_b}(x_2) μx1→fa(x1)=1μfa→x2(x2)=x1∑fa(x1,x2)μx4→fc(x4)=1μfc→x2(x2)=x4∑fc(x2,x4)μx2→fb(x2)=μfa→x2(x2)μfc→x2(x2)μfb→x3(x3)=x2∑fb(x2,x3)μx2→fb(x2)
图(b):根 → \to →叶子
μ x 3 → f b ( x 3 ) = 1 μ f b → x 2 ( x 2 ) = ∑ x 3 f b ( x 2 , x 3 ) μ x 2 → f a ( x 2 ) = μ f b → x 2 ( x 2 ) μ f c → x 2 ( x 2 ) μ f a → x 1 ( x 1 ) = ∑ x 2 f a ( x 1 , x 2 ) μ x 2 → f a ( x 2 ) μ x 2 → f c ( x 2 ) = μ f a → x 2 ( x 2 ) μ f b → x 2 ( x 2 ) μ f c → x 4 ( x 4 ) = ∑ x 2 f c ( x 2 , x 4 ) μ x 2 → f c ( x 2 ) \mu_{x_3\to f_b}(x_3)=1\\ \mu_{f_b\to x_2}(x_2)=\sum\limits_{x_3}f_b(x_2,x_3)\\ \mu_{x_2\to f_a}(x_2)=\mu_{f_b\to x_2}(x_2)\mu_{f_c\to x_2}(x_2)\\ \mu_{f_a\to x_1}(x_1)=\sum\limits_{x_2}f_a(x_1,x_2)\mu_{x_2\to f_a}(x_2)\\ \mu_{x_2\to f_c}(x_2)=\mu_{f_a\to x_2}(x_2)\mu_{f_b\to x_2}(x_2)\\ \mu_{f_c\to x_4}(x_4)=\sum\limits_{x_2}f_c(x_2,x_4)\mu_{x_2\to f_c}(x_2) μx3→fb(x3)=1μfb→x2(x2)=x3∑fb(x2,x3)μx2→fa(x2)=μfb→x2(x2)μfc→x2(x2)μfa→x1(x1)=x2∑fa(x1,x2)μx2→fa(x2)μx2→fc(x2)=μfa→x2(x2)μfb→x2(x2)μfc→x4(x4)=x2∑fc(x2,x4)μx2→fc(x2)
注:按叶子到根的顺序能够保证其中的每个节点在向下继续传递信息前,能够收集到足够的信息;而从根到叶子的传递过程中,根成了唯一的信息源,故需要利用先前叶子传递到根的信息,所里两个步骤具有先后顺序
在此基础上,我们得到
p ~ ( x 2 ) = μ f a → x 2 ( x 2 ) μ f b → x 2 ( x 2 ) μ f c → x 2 ( x 2 ) = ∑ x 1 f a ( x 1 , x 2 ) ∑ x 3 f b ( x 2 , x 3 ) ∑ x 4 f c ( x 2 , x 4 ) \tilde{p}(x_2)=\mu_{f_a\to x_2}(x_2)\mu_{f_b\to x_2}(x_2)\mu_{f_c\to x_2}(x_2)\\ =\sum\limits_{x_1}f_a(x_1,x_2)\sum\limits_{x_3}f_b(x_2,x_3)\sum\limits_{x_4}f_c(x_2,x_4) p~(x2)=μfa→x2(x2)μfb→x2(x2)μfc→x2(x2)=x1∑fa(x1,x2)x3∑fb(x2,x3)x4∑fc(x2,x4)
而纯粹利用变量消除法,我们有
p ~ ( x 2 ) = ∑ x 1 , x 3 , x 4 p ( X ) = ∑ x 1 ∑ x 3 ∑ x 4 f a ( x 1 , x 2 ) f b ( x 2 , x 3 ) f c ( x 2 , x 4 ) = ∑ x 1 f a ( x 1 , x 2 ) ∑ x 3 f b ( x 2 , x 3 ) ∑ x 4 f c ( x 2 , x 4 ) \tilde{p}(x_2)=\sum\limits_{x_1,x_3,x_4}p(X)\\ =\sum\limits_{x_1}\sum\limits_{x_3}\sum\limits_{x_4}f_a(x_1,x_2)f_b(x_2,x_3)f_c(x_2,x_4)\\ =\sum\limits_{x_1}f_a(x_1,x_2)\sum\limits_{x_3}f_b(x_2,x_3)\sum\limits_{x_4}f_c(x_2,x_4) p~(x2)=x1,x3,x4∑p(X)=x1∑x3∑x4∑fa(x1,x2)fb(x2,x3)fc(x2,x4)=x1∑fa(x1,x2)x3∑fb(x2,x3)x4∑fc(x2,x4)
二者结果一致,即验证了Sum-Product算法的正确性。
衍生算法
回到我们的推断任务上来,我们需要解决边缘概率、条件概率与最大后验三个问题。利用上述的Sum-Product算法,我们已经能够高效地完成第一个任务——求边缘概率。
而对于求解条件概率,利用贝叶斯法则,我们有
p ( X A ∣ X B ) = p ( X A , X B ) p ( X B ) p(X_A|X_B)=\dfrac{p(X_A,X_B)}{p(X_B)} p(XA∣XB)=p(XB)p(XA,XB)
我们不再是求单个变量的边缘概率,而是求解变量集合的边缘概率。
求解随机变量集合的边缘概率
如图,与上文处理 F S ( x , X S ) F_S(x,X_S) FS(x,XS)时采取的手法一致地,我们将联合概率拆解为
p ( X ) = f S ( X S ) ∏ m ∈ n e ( f S ) G m ( x m , X S m ) p(X)=f_S(X_S)\prod\limits_{m\in ne(f_S)}G_m(x_m,X_{Sm}) p(X)=fS(XS)m∈ne(fS)∏Gm(xm,XSm)
这里的 X S X_S XS与上文中的含义略有不同,此处指 f S f_S fS关联起来的目标变量集合
利用加法法则,我们有
p ( X S ) = ∑ X ∖ X S p ( X ) = ∑ X ∖ X S f S ( X S ) ∏ m ∈ n e ( f S ) G m ( x m , X S m ) = f S ( X S ) ∑ X ∖ X S ∏ m ∈ n e ( f S ) G m ( x m , X S m ) ( ∗ ) p(X_S)=\sum\limits_{X\setminus X_S}p(X)\\ =\sum\limits_{X\setminus X_S}f_S(X_S)\prod\limits_{m\in ne(f_S)}G_m(x_m,X_{Sm})\\ =f_S(X_S)\sum\limits_{X\setminus X_S}\prod\limits_{m\in ne(f_S)}G_m(x_m,X_{Sm})(*) p(XS)=X∖XS∑p(X)=X∖XS∑fS(XS)m∈ne(fS)∏Gm(xm,XSm)=fS(XS)X∖XS∑m∈ne(fS)∏Gm(xm,XSm)(∗)
同样的,我们对 X ∖ X S X\setminus X_S X∖XS有如下拆分
X ∖ X S = X S 1 ∪ X S 2 ∪ ⋯ ∪ X S M = ⋃ i ∈ n e ( f S ) X S i X\setminus X_S = X_{S1}\cup X_{S2}\cup\cdots\cup X_{SM}=\bigcup\limits_{i\in ne(f_S)}X_{Si} X∖XS=XS1∪XS2∪⋯∪XSM=i∈ne(fS)⋃XSi
利用上述结果将求和号打开
( ∗ ) = f S ( X S ) ∑ X S 1 ⋯ ∑ X S M G 1 ( x 1 , X S 1 ) ⋯ G M ( x M , X S M ) = f S ( X S ) ∑ X S 1 G 1 ( x 1 , X S 1 ) ⋯ ∑ X S M G M ( x M , X S M ) = f S ( X S ) [ ∑ X S 1 G 1 ( x 1 , X S 1 ) ] ⋯ [ ∑ X S M G M ( x M , X S M ) ] = f S ( X S ) ∏ i ∈ n e ( f S ) ∑ X S i G i ( x i , X S i ) (*)=f_S(X_S)\sum\limits_{X_{S1}}\cdots\sum\limits_{X_{SM}}G_1(x_1,X_{S1})\cdots G_M(x_M,X_{SM})\\ =f_S(X_S)\sum\limits_{X_{S1}}G_1(x_1,X_{S1})\cdots\sum\limits_{X_{SM}}G_M(x_M,X_{SM})\\ =f_S(X_S)\Big[\sum\limits_{X_{S1}}G_1(x_1,X_{S1})\Big]\cdots\Big[\sum\limits_{X_{SM}}G_M(x_M,X_{SM})\Big]\\ =f_S(X_S)\prod_{i\in ne(f_S)}\sum_{X_{Si}}G_i(x_i,X_{Si}) (∗)=fS(XS)XS1∑⋯XSM∑G1(x1,XS1)⋯GM(xM,XSM)=fS(XS)XS1∑G1(x1,XS1)⋯XSM∑GM(xM,XSM)=fS(XS)[XS1∑G1(x1,XS1)]⋯[XSM∑GM(xM,XSM)]=fS(XS)i∈ne(fS)∏XSi∑Gi(xi,XSi)
最后,根据 μ x → f ( x ) \mu_{x\to f}(x) μx→f(x)的定义,我们最终得到
p ( X S ) = f S ( X S ) ∏ i ∈ n e ( f S ) μ x i → f S ( x i ) p(X_S)=f_S(X_S)\prod\limits_{i\in ne(f_S)}\mu_{x_i\to f_S}(x_i) p(XS)=fS(XS)i∈ne(fS)∏μxi→fS(xi)
这样,我们可以利用Sum-Product得到的信息求得随机变量集合的边缘概率。
观测变量处理
上述讨论中,我们默认所有变量都是未观测变量,而对于观测变量来说,只需对联合概率作小小的改进即可胜任。
假设 X = h ∪ v X=h\cup v X=h∪v,其中 h h h为隐变量, v v v为观测变量,且观测值为 v ^ \hat v v^.我们向联合概率中引入一些因子,得到
p ( h , v = v ^ ) = p ( X ) ∏ i I ( v i , v i ^ ) p(h,v=\hat v)=p(X)\prod\limits_iI(v_i,\hat{v_i}) p(h,v=v^)=p(X)i∏I(vi,vi^)
其中,
I ( v , v ^ ) = { 1 , v = v ^ , 0 , v ≠ v ^ . I(v,\hat v)= \left\{ \begin{array}{ll} 1,&v=\hat v,\\ 0,&v\not=\hat v. \end{array} \right. I(v,v^)={1,0,v=v^,v=v^.
求最大后验
即要求 X m a x = arg max X p ( X ) X^{max}=\mathop{\arg\max}\limits_X\ p(X) Xmax=Xargmax p(X).
我们先考虑一个稍微弱化的任务:不求出联合概率最大时变量的具体取值,而是求出对应的最大概率,即
p ( X m a x ) = max X p ( X ) p(X^{max})=\max\limits_{X}p(X) p(Xmax)=Xmaxp(X)
事实上, m a x max max与 ∑ \sum ∑一样,是可以拆解的。我们想求三个数的最大值,可以先求出其中两个数的最大值,再与第三数进行比较。
因此,我们有
max X p ( X ) = max x 1 max x 2 ⋯ max x 3 p ( X ) \max\limits_{X}p(X)=\max\limits_{x_1}\max\limits_{x_2}\cdots\max\limits_{x_3}p(X) Xmaxp(X)=x1maxx2max⋯x3maxp(X)
同样的,乘法关于最大值的分配律依然成立,即 c ⋅ max ( a , b ) = max ( c a , c b ) c\cdot \max(a,b)=\max(ca,cb) c⋅max(a,b)=max(ca,cb).既然如此,我们依旧可以用理解 ∑ \sum ∑的方式来理解 max \max max.而针对最大后验值,从形式上来说,与求解某一变量的边缘概率几乎一致,只不过求边缘概率时不需要对所求的目标变量求和,故求最大后验时会多一层 max \max max。
将Sum-Product算法的 ∑ \sum ∑改写为 max \max max,就得到了所谓的Max-Product算法,即
{ max X p ( X ) = max x ∏ S ∈ n e ( x ) μ f S → x ( x ) μ f → x ( x ) = max x 1 , ⋯ , x M f ( x , x 1 , ⋯ , x M ) ∏ m ∈ n e ( f ) ∖ x μ x m → f ( x m ) μ x → f ( x ) = ∏ l ∈ n e ( x ) ∖ f μ f l → x ( x ) \left\{\begin{array}{ll} \max\limits_{X}p(X)=\max\limits_{x}\prod\limits_{S\in ne(x)}\mu_{f_S\to x}(x)\\ \mu_{f\to x}(x)=\max\limits_{x_1,\cdots,x_M}f(x,x_1,\cdots,x_M)\prod\limits_{m\in ne(f)\setminus x}\mu_{x_m\to f}(x_m)\\ \mu_{x\to f}(x)=\prod\limits_{l\in ne(x)\setminus f}\mu_{f_l\to x}(x) \end{array}\right. ⎩ ⎨ ⎧Xmaxp(X)=xmaxS∈ne(x)∏μfS→x(x)μf→x(x)=x1,⋯,xMmaxf(x,x1,⋯,xM)m∈ne(f)∖x∏μxm→f(xm)μx→f(x)=l∈ne(x)∖f∏μfl→x(x)
同样的,我们选定一个根节点,并且只需要将信息从叶子传递到根即可;最后,针对 x x x的不同取值求出其最大值,即为最大后验的值。
整个求解过程是一个动态规划(Dynamic Programming),我们通过不断的对部分随机变量进行优化,最终得到全局的最优解。
同样的,我们可以利用动态规划中的常见的反向追踪(back-tracking)手法来求得 X m a x X^{max} Xmax.在每次进行从当前最优化的 x n − 1 m a x x_{n-1}^{max} xn−1max到 x n x_n xn状态转移时,我们都记录下它的来源,记
ϕ ( x n ) = x n − 1 max \phi(x_n)=x_{n-1}^{\max} ϕ(xn)=xn−1max
这样,在我们求得最后根节点 x m a x x^{max} xmax后,将它带到 ϕ \phi ϕ中,就可以找出 X m a x X^{max} Xmax的具体取值了,如下图:

但Max-Product算法还有优化的空间。不难看出,我们对这些因子进行了多次乘法,而这些因子是联合概率的组成部分。实际应用中,对一个小于1的浮点数进行多次乘法,对精度构成了挑战,而简单的取一个对数便能将乘法化为加法,完美的解决问题,如下
{ ln max X p ( X ) = max x [ ∑ S ∈ n e ( x ) μ f S → x ( x ) ] μ f → x ( x ) = max x 1 , ⋯ , x M [ ln f ( x , x 1 , ⋯ , x M ) + ∑ m ∈ n e ( f ) ∖ x μ x m → f ( x m ) ] μ x → f ( x ) = ∑ l ∈ n e ( x ) ∖ f μ f l → x ( x ) \left\{\begin{array}{ll} \ln\max\limits_{X}p(X)=\max\limits_{x}\Big[\sum\limits_{S\in ne(x)}\mu_{f_S\to x}(x)\Big]\\ \mu_{f\to x}(x)=\max\limits_{x_1,\cdots,x_M}\Big[\ln f(x,x_1,\cdots,x_M)+\sum\limits_{m\in ne(f)\setminus x}\mu_{x_m\to f}(x_m)\Big]\\ \mu_{x\to f}(x)=\sum\limits_{l\in ne(x)\setminus f}\mu_{f_l\to x}(x) \end{array}\right. ⎩ ⎨ ⎧lnXmaxp(X)=xmax[S∈ne(x)∑μfS→x(x)]μf→x(x)=x1,⋯,xMmax[lnf(x,x1,⋯,xM)+m∈ne(f)∖x∑μxm→f(xm)]μx→f(x)=l∈ne(x)∖f∑μfl→x(x)
具体地,我们取 ϕ ( x n ) \phi(x_n) ϕ(xn)为
ϕ ( x n ) = arg max x n − 1 [ ln f n − 1 , n ( x n − 1 , x n ) + μ x n − 1 → f n − 1 , n ( x n ) ] \phi(x_n)=\mathop{\arg\max}\limits_{x_{n-1}}[\ln f_{n-1,n}(x_{n-1},x_n)+\mu_{x_{n-1}\to f_{n-1,n}}(x_n)] ϕ(xn)=xn−1argmax[lnfn−1,n(xn−1,xn)+μxn−1→fn−1,n(xn)]
相应地,边界条件也发生了改变
μ x → f ( x ) = 0 , μ f → x ( x ) = ln f ( x ) \mu_{x\to f}(x)=0,\mu_{f\to x}(x)=\ln f(x) μx→f(x)=0,μf→x(x)=lnf(x)
Max-Product(Max-Sum)算法可以看作是对Viterbi算法的推广。
后续内容书中点到为止,此处亦不做具体展开。
下文传送门:
PRML读书会第五期——概率图模型(Graphical Models)【下】