2021年MathorCup高校数学建模挑战赛—大数据竞赛B题信息流智能推荐算法中的序列评估问题求解全过程文档及程序
2021年MathorCup高校数学建模挑战赛—大数据竞赛
B题 信息流智能推荐算法中的序列评估问题
原题再现:
随着互联网信息的蓬勃发展,用户在使用互联网应用时面临着信息过载的问题。推荐算法的出现,满足了用户个性化的内容消费需求,提升了用户获取有用信息的效率,在互联网 APP 里已被广泛应用。信息流作为推荐算法的主要应用场景,是用户触达互联网信息的主要入口,已经完全融入了人们的日常生活中,成为了人们了解世界的主要方式。
图 1 为信息流产品示例。该示例中,用户在执行刷新操作后,推
荐系统返回了 K 条推荐结果,构成了一个推荐序列。其中前 4 条推荐内容占满了一个手机屏幕,用户继续下滑可浏览剩余内容。一个推荐序列由多种内容类型构成,例如,内容 1 为图文内容,内容 4 为视频内容。需要说明的是,推荐系统每次返回的内容条数 K 可以是不固定的,系统可以根据用户的具体请求环境进行动态调整,以此得到最佳的用户浏览体验,如何确定 K 的大小在本题目中不做讨论。

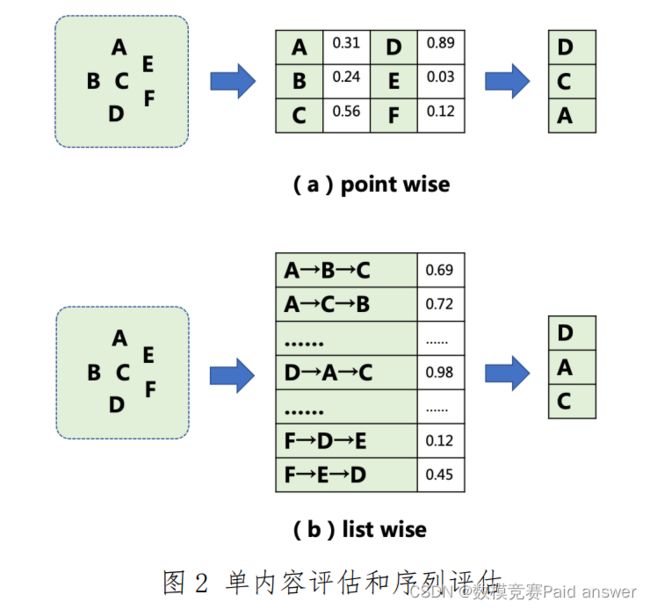
传统推荐算法的核心思想是挖掘被推荐内容与用户兴趣的匹配关系,以及内容本身的优质程度,选择与用户最相关或者最优质的内容推荐给用户。如图 2 中(a)所示,推荐系统会对单条候选内容进行打分评估,通过内容是否匹配用户兴趣以及内容质量的高低,来预估给用户推荐这条内容后带来的综合收益大小(综合收益通常包含用户是否会点击这条内容,以及用户在这条内容上的浏览时长)。系统打出的分值则是对每条内容带来的综合收益大小的刻画。然后,系统选择出预估分值最大的 K 条内容,并按照分值从大到小的顺序推荐给用户。这种推荐方式我们称之为 point wise。
但是,研究发现,除了内容本身因素以外,内容之间的排列组合
关系,也会影响用户的浏览体验,进而影响推荐收益的大小。例如,相似内容的高度集中,往往会带来较差的结果反馈,即使它们都高度匹配用户兴趣或者具有较高的内容质量。于是,越来越多的研究集中在如何选择最优的内容排列组合上,而不仅仅是最优的内容上。如图2 中(b)所示,同样的 ABC 三条内容,按照不同的顺序(A→B→C、A→C→B、……)推荐给用户,会带来不一样的收益大小。推荐系统需要先根据候选内容生成候选推荐序列,然后对每一个候选序列进行打分评估,系统打出的分值则是对每个序列带来的整体综合收益大小的刻画。最后,系统选择出预估分值最高的一个序列,按照该序列的排列顺序将内容推荐给用户。这种推荐方式我们称之为 list wise。本题目要求参赛者设计数学模型对给定的候选序列进行序列整体收益评估。
题目提供近一周时间内用户在信息流产品上的曝光历史(train_data.txt)作为训练集,以供参赛者进行建模分析。附件中的 train_data.样例.txt 给出了数据格式示例,方便参赛者查看。涉及字段包括:
1. 用户 ID:用户唯一标识,例如 1000024368;
2. 请 求 ID:用户单次请求推荐服务的唯一标识 ,例如500012184_1635188998881_5305;
3. 日期:用户单次请求推荐服务的日期,例如 20211026;
4. 时间:用户单次请求推荐服务的时间,例如 22(代表晚上 22点);
5. 推荐序列:用户单次请求推荐服务,推荐服务返回的内容列表。内容的排列顺序即为内容的真实推荐顺序,多个内容之间用“;”分隔,单个内容包括三个字段:内容ID、用户是否点击(0 代表未点击,1 代表点击)、用户浏览时长(单位为秒),多 个 字 段 之 间 用 “ :” 分隔 。 例如133672454001:0:0;508896132:1:111;508969800:0:0;508870333:1:10;
同时,题目提供内容的基础属性(doc_info.txt)。附件中的doc_info.样例.txt 给出了数据格式示例。涉及字段包括:
1. 内容 ID:内容的唯一标识,例如 133342615958;
2. 内容类型:推荐内容分为视频(video)和图文(news)两种类型;
3. 内容类别:内容的一二级分类,例如综艺/内地综艺;
最后,题目提供在训练集时间之后的一部分用户推荐序列作为测试集(test_data.txt),附件中的 test_data.样例.txt 给出了数据格式示例。参赛者需要根据训练集数据预测测试集序列的收益大小。
涉及字段包括:
1. 请求ID:用户单次请求推荐服务的唯一标识 ,例如500012184_1635188998881_5305;
2. 用户 ID:用户唯一标识,例如 1000024368;
3. 日期:用户单次请求推荐服务的日期,例如 20211026;
4. 时间:用户单次请求推荐服务的时间,例如 22(代表晚上22点);
5. 推荐序列:用户单次请求推荐服务,推荐服务返回的内容列表。内容的排列顺序即为内容的真实推荐顺序,多个内容之间用“ ;” 分 隔 ,单个内容 只 提 供 内 容 ID ,例如508681374;133681260394;508767175;508767175;
上述完整数据集通 过 https://pan.yidian-inc.com/index.php/s/QB7lhh7YPKLJWfL 进行下载获取。请参赛者对上述数据进行分析并建立模型,解决以下问题。参赛者需要将最终解决方案以论文方式进行详细阐述,包括主要模型、算法和计算结果,并以单独文件提交问题 2 的预测结果到竞赛系统中,不改变文件的格式。
问题 1:建立评估推荐序列总点击收益(序列中单条内容的点击量之和)和总时长收益(序列中单条内容的浏览时长之和)的数学模型,以及如何根据点击收益和时长收益对综合收益进行量化。不同于评估单个推荐内容收益的数学模型,在序列评估模型设计中,需要详细阐述如何考虑不同排列组合对收益大小的影响。
问题 2:基于问题 1 设计的数学模型,预测测试集(test_data.txt)中推荐序列的总点击量和总时长(单位为秒),将预测结果写入result.csv 并提交。文件包含三列:请求 ID、总点击量、总浏览时长。请求 ID 对应测试集中的请求 ID,总点击量和总浏览时长为预估出的测试集中每个请求 ID 对应推荐序列的点击量和时长之和。附件result.csv 中已给出的总点击量和总时长为随机生成的示例数据,参赛者需要将其替换为自己预测的总点击量和总时长值再提交。
问题 3:假设有 N 条候选内容,从中选择长度为 K(N≥K)的最
优推荐序列,需要参与收益评估的序列量为A[K,N]"。在真实推荐场景中,由于计算性能的考虑,系统无法对所有可能序列进行收益评估,往往需要先采用计算复杂度更低的方式对序列集合进行剪枝,圈定出少量候选序列进行精确收益评估。而剪枝策略的目标是保证候选序列集更大可能包含最优序列。请详细阐述你的建模思路,以及剪枝策略的精准度和时间复杂度。
整体求解过程概述(摘要)
随着信息流和互联网的迅猛发展,网络越发成为人们获取信息的主要来源。为了有效的提升用户浏览信息的效率,准确推送用户喜爱的个性化的内容,成为当前的热门需求。其中推荐内容的排列顺序会影响用户的浏览体验。本文将对推荐序列的排序提出评估及用户反应预测的算法。
针对问题一和问题二,我们首先进行数据预处理,数据可视化及分析数据的基本情况,基于用户浏览时长,用户浏览时间,用户推荐内容,用户总点击量等特征,使用 − 算法对用户做聚类分析。我们提出我们采用 Transformer 的深度神经网络模型和最相似用户数据的估计模型相结合的混合模型以预测用户浏览各个物品的点击和浏览时间, 并把 Transformer 模型得到的结果标准化后求和得到评估模型。在完成数据预处理后,我们将用户 ID,推荐序列的内容,浏览时间,作为特征,浏览时长作为标签,基于用户消耗的精力(学习参数)和浏览时长的违反度设计损失函数。训练后,通过解码得到推荐序列的预测总点击量和总浏览时长。基于最相似用户数据的估计模型是通过计算目标用户与训练集用户的相似度,以选取训练集中与其最相似的用户,根据该特定用户在训练数据中的行为数据预测目标用户的行为。最终我们,将两个模型得到的结果加权求和便得到求解第二问的混合模型。问题二根据问题一训练得到网络模型就可以预测测试集中推荐序列的总点击量和总时长。
针对问题三,我们使用基于集束搜索和 transformer 的强化学习算法,基于总点击量和总浏览时长设计回报函数,从 N 条推荐内容选择 K 条推荐内容。结合集束搜索,这样根据强化学习的回报函数的选择可以得到最优的 K 条推荐内容,进而可以通过问题一提出的模型计算相应的总点击量和总浏览时长。
模型假设:
1.假设测试集中的用户爱好分布符合训练集中的用户爱好分布。
2.假设每个用户的精力是一样的,但看完一项内容之后精力损耗是不一样的,看完物品后的精力损耗也是模型要训练学习的参数。
3.假设用户在能量剩余小于等于 0 时不在继续浏览。
4.假设相似的用户的被推荐内容是相似的。
问题分析:
问题1分析
问题一需要构造一个评估推荐序列总点击收益(序列中单条内容的点击量之和)和总时长收益(序列中单条内容的浏览时长之和)的整合模型,我们采用 Transformer的深度神经网络模型和最相似用户数据的估计模型相结合的混合模型。Transformer 的深度神经网络模型首先给定每个用户的能量函数Energy(t),记录浏览内容带来的精力损失。将当前能量,用户浏览时长,用户观看时间,推荐内容类型作为encoder输入,输出为用户的精力损耗。由于内容是按照列表的序列顺序进行输入的,结合 Transformer的注意力机制,是可以学习到内容顺序对用户浏览带来的影响。基于总点击量和实际点击量设计损失函数。网络结构采用引入注意力机制的深度神经网络。基于最相似用户数据的估计模型是通过计算目标用户与训练集用户的相似度,以选取训练集中与其最相似的用户,根据该特定用户在训练数据中的行为数据预测目标用户的行为。最终我们,将两个模型得到的结果加权求和便得到求解第二问的混合模型,同时根据基于Transformer 的深度神经网络模型设计综合收益的评价模型。
问题 2 分析
根据问题一训练得到网络模型就可以预测测试集中推荐序列的总点击量和总时长。
问题 3 分析
问题三需要对用户的推荐内容序列进行剪枝,圈定出少量候选序列进行精确收益评估。我们采用基于集束搜索和 Transformer 的强化学习模型。强化学习模型可以基于设计的回报函数选出点击量高和浏览时间长的推荐序列,Transformer 模型可以很好的提取特征和分析序列信息。在强化学习的搜索采样中选择集束搜索将很大程度上提高搜索效率和提高解的质量。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
部分Python程序如下:
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def load_data_fashion_mnist(batch_size, resize=None, root='~/Datasets/FashionMNIST'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=4)
return train_iter, test_iter