卷积神经网络Inception Net
1. 概述
2014年,Google提出了包含Inception模块的网络结构,并命名为GoogLeNet[1],其中LeNet为致敬LeNet网络,GoogLeNet在当年的ILSVRC的分类任务上获得冠军。GoogLeNet经过多次的迭代,最初的版本也被称为Inception v1。Inception的名字也得益于NIN和盗梦空间“We need to go deeper”的启发。提高模型的表达能力,最有效的办法是增加模型的大小,包括了模型的深度和模型的宽度,但是一味的增大模型会出现以下的一些问题:
- 模型越大,相应的参数也就会越多,就会出现过拟合;
- 模型越大,需要的计算资源也就会越多;
那么是否存在一种方法,能够在增大模型的同时,控制参数的个数呢?Inception v1中认为最基本的方法是使用稀疏连接代替全连接和卷积操作,同时引入 1 × 1 1\times 1 1×1的卷积核来进一步减少参数个数。
2015年,Google在Inception v1的基础上提出了Batch Normalization[2]的操作,并将其添加到GoogLeNet网络中,同时对网络结构做了一些修改,也被称为Inception v2,最终在ImageNet分类任务上的成绩超过了Inception v1。
在Inception v2之后,Google对Inception模块进行重新的思考,提出了一系列的优化思路,如针对神经网络的设计提出了四条的设计原则,提出了如何分解大卷积核,重新思考训练过程中的辅助分类器的作用,最终简化了网络的结构,得到了Inception v3[3]。
2. Inception网络结构
2.1. Inception v1
在Inception v1中提出了Inception模块,该模块在增加网络的深度和宽度的过程中极大减少了模型的参数。
2.1.1. Inception模块
在Inception v1中,提出了Inception模块,希望在Inception模块中引入稀疏连接来减少参数的数量。稀疏连接有两种方法,一种是空间(spatial)上的稀疏连接,也就是传统的CNN卷积结构,即只对输入图像的某一部分patch进行卷积,而不是对整个图像进行卷积,共享参数降低了总参数的数目减少了计算量;另一种方法是在特征(feature)维度进行稀疏连接,就是前一节提到的在多个尺寸上进行卷积再聚合,把相关性强的特征聚集到一起,每一种尺寸的卷积只输出256个特征中的一部分,这也是种稀疏连接。
基于上述的特征维度的稀疏连接,Inception模块的设计便与常见的CNN网络结构不同,原先的卷积层通常采用的是串联的设计思路,而在Inception模块中则是采用将多种不同规格的卷积并联的方式,在Inception中,选择的卷积核大小分别为 1 × 1 1\times 1 1×1, 3 × 3 3\times 3 3×3, 5 × 5 5\times 5 5×5,最终将各自所得到的特征图concat在一起,作为后续的输入,如下左图所示:
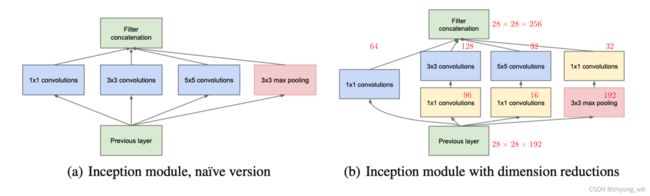
受到NIN[4]的启发,为进一步减少参数的个数,在 3 × 3 3\times 3 3×3和 5 × 5 5\times 5 5×5的卷积操作前增加了 1 × 1 1\times 1 1×1的卷积核。如果不采用并联的方式,对于大小为 28 × 28 × 192 28\times 28\times 192 28×28×192的输入,其中通道数为 192 192 192,大小为 28 × 28 × 256 28\times 28\times 256 28×28×256的输出,如果只采用 3 × 3 3\times 3 3×3的卷积核,则参数的个数为 3 × 3 × 192 × 256 = 442368 3\times 3\times 192\times 256=442368 3×3×192×256=442368,若果只是采用 5 × 5 5\times 5 5×5的卷积核,则参数的个数为 5 × 5 × 192 × 256 = 1228800 5\times 5\times 192\times 256=1228800 5×5×192×256=1228800。
而通过concat多种不同的卷积核以及pooling操作,则可以减少参数的个数,按照上述图片中标注的每种卷积核的输出通道数,其参数的个数为:
{ 64 × 192 96 × 192 + 3 × 3 × 96 × 128 16 × 192 + 5 × 5 × 32 × 26 32 × 192 \left\{\begin{matrix} 64\times 192 \\ 96\times 192+3\times 3\times 96\times 128 \\ 16\times 192+5\times 5\times 32\times 26 \\ 32\times 192\end{matrix}\right. ⎩ ⎨ ⎧64×19296×192+3×3×96×12816×192+5×5×32×2632×192
最终的参数个数为 163328 163328 163328,相比较上述采用单一的卷积核,参数个数大大较少了。
2.1.2. Inception v1的网络结构
将Inception模块融合到卷积网络中,替换卷积神经网络中的部分卷积操作便得到Inception v1的结构,其结构的具体参数如下表所示:

其具体的计算过程如下所示:
- data:大小为 224 × 224 × 3 224\times224\times3 224×224×3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
- convolution:输入( 224 × 224 × 3 224\times224\times3 224×224×3),输出( 112 × 112 × 64 112\times112\times64 112×112×64,其中,卷积核大小为 7 × 7 7\times7 7×7,padding为 3 3 3,步长为 2 2 2,卷积核的个数为 64 64 64,卷积后进行ReLU操作)
- max pool:输入( 112 × 112 × 64 112\times112\times64 112×112×64),输出( 56 × 56 × 64 56\times56\times64 56×56×64,其中,核的大小为 3 × 3 3\times3 3×3,步长为 2 2 2)
- convolution:输入( 56 × 56 × 64 56\times56\times64 56×56×64),输出( 56 × 56 × 192 56\times56\times192 56×56×192,其中,卷积核大小为 3 × 3 3\times3 3×3,padding为 1 1 1,步长为 1 1 1,卷积核的个数为 192 192 192,卷积后进行ReLU操作)
- max pool:输入( 56 × 56 × 192 56\times56\times192 56×56×192),输出( 28 × 28 × 192 28\times28\times192 28×28×192,其中,核的大小为 3 × 3 3\times3 3×3,步长为 2 2 2)
- Inception(3a):分为四个分支操作,输入( 28 × 28 × 192 28\times28\times192 28×28×192)
- 卷积1:输出( 28 × 28 × 64 28\times28\times64 28×28×64,其中,卷积核大小为 1 × 1 1\times1 1×1,padding为 0 0 0,步长为 1 1 1,卷积核的个数为 64 64 64)
- 卷积2:输出( 28 × 28 × 128 28\times28\times128 28×28×128,其中,包含了两部分的卷积操作,第一个是 96 96 96个 1 × 1 1\times1 1×1的卷积核,输出为 28 × 28 × 96 28\times28\times96 28×28×96,第二个是 128 128 128个 3 × 3 3\times3 3×3的卷积核,输出为 28 × 28 × 128 28\times28\times128 28×28×128)
- 卷积3:输出( 28 × 28 × 32 28\times28\times32 28×28×32,其中,包含了两部分的卷积操作,第一个是 16 16 16个 1 × 1 1\times1 1×1的卷积核,输出为 28 × 28 × 16 28\times28\times16 28×28×16,第二个是 32 32 32个 5 × 5 5\times5 5×5的卷积核,输出为 28 × 28 × 32 28\times28\times32 28×28×32)
- 卷积4:输出( 28 × 28 × 32 28\times28\times32 28×28×32,其中,包含了两部分的操作,第一个是max pool,核的大小为 3 × 3 3\times3 3×3,输出为 28 × 28 × 192 28\times28\times192 28×28×192,第二个是 32 32 32个 1 × 1 1\times1 1×1的卷积核,输出为 28 × 28 × 32 28\times28\times32 28×28×32)
- 将这四个结果进行连接,对这四部分输出结果的第三维并联,即 64 + 128 + 32 + 32 = 256 64+128+32+32=256 64+128+32+32=256,最终输出 28 × 28 × 256 28\times28\times256 28×28×256
- Inception(3b):分为四个分支操作,输入( 28 × 28 × 256 28\times28\times256 28×28×256)
- 卷积1:输出( 28 × 28 × 128 28\times28\times128 28×28×128,其中,卷积核大小为 1 × 1 1\times1 1×1,padding为 0 0 0,步长为 1 1 1,卷积核的个数为 128 128 128)
- 卷积2:输出( 28 × 28 × 192 28\times28\times192 28×28×192,其中,包含了两部分的卷积操作,第一个是 128 128 128个 1 × 1 1\times1 1×1的卷积核,输出为 28 × 28 × 128 28\times28\times128 28×28×128,第二个是 192 192 192个 3 × 3 3\times3 3×3的卷积核,输出为 28 × 28 × 192 28\times28\times192 28×28×192)
- 卷积3:输出( 28 × 28 × 96 28\times28\times96 28×28×96,其中,包含了两部分的卷积操作,第一个是 32 32 32个 1 × 1 1\times1 1×1的卷积核,输出为 28 × 28 × 32 28\times28\times32 28×28×32,第二个是 96 96 96个 5 × 5 5\times5 5×5的卷积核,输出为 28 × 28 × 96 28\times28\times96 28×28×96)
- 卷积4:输出( 28 × 28 × 64 28\times28\times64 28×28×64,其中,包含了两部分的操作,第一个是max pool,核的大小为 3 × 3 3\times3 3×3,输出为 28 × 28 × 256 28\times28\times256 28×28×256,第二个是 64 64 64个 1 × 1 1\times1 1×1的卷积核,输出为 28 × 28 × 64 28\times28\times64 28×28×64)
- 将这四个结果进行连接,对这四部分输出结果的第三维并联,即 128 + 192 + 96 + 64 = 480 128+192+96+64=480 128+192+96+64=480,最终输出 28 × 28 × 480 28\times28\times480 28×28×480
剩下的类似分析,就不一一列举了。完整的Inception v1的网络结构如下图所示:

在Inception v1中,还保留了局部响应归一Local Response Normalization,也就是上图中的LRN,不过LRN在VGG的论文中交待是没有作用的,在后续的Inception v2中也是将这部分替换掉,在此不做过多介绍。
2.1.3. Inception v1的训练
由于网络的深度增加了,防止在梯度回传的过程中造成梯度弥散,因此在中间的Inception模块中设置了额外的辅助Loss,用以增加向后传导的梯度,缓解梯度消失问题,同时增加额外的正则化操作。最终的损失函数是三个部分的损失函数的和。
2.2. Inception v2
Inception v2的网络在Inception v1的基础上,进行了改进,主要的改动包括两个方面:第一,加入了Batch Normalization层,减少了Internal Covariate Shift,使每一层的输出都规范化到一个 N ( 0 , 1 ) N\left ( 0,1 \right ) N(0,1)的高斯分布;第二,使用 2 2 2个 3 × 3 3\times 3 3×3的卷积核替代Inception模块中的 5 × 5 5\times 5 5×5卷积核,既降低了参数数量,也加速计算;
2.2.1. Batch Normalization
由于在网络的每一层的输入发生变化后,就会使得每一层的内部参数要不断适应新的分布,这一现象称为内部协移(Internal Covariate Shift),为了减少这样的现象的出现,需要对每一层的输入归一化。
Batch Normalization的作用便是对batch内的输入做归一化操作,对于一个神经元的一个mini-batch上的一批数据,做一次BN操作:
- 假设batch的大小为 m m m,首先求解该mini-batch上的均值:
μ B ← 1 m ∑ i = 1 m x i \mu _B\leftarrow \frac{1}{m} \sum_{i=1}^{m}x_i μB←m1i=1∑mxi - 求该mini-batch上的方差:
σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 \sigma _B^{2}\leftarrow \frac{1}{m}\sum_{i=1}^{m}(x_i-\mu _B)^2 σB2←m1i=1∑m(xi−μB)2 - 把每个数据归一化:
x i ^ ← x i − μ B σ B 2 + ε \hat{x_i}\leftarrow \frac{x_i-\mu _B}{\sqrt{\sigma _B^2+\varepsilon }} xi^←σB2+εxi−μB
,这样就得到了均值为0,方差为1的归一化数据。 - 使用线性变换:
y i ← γ x ^ i + β y_i\leftarrow \gamma \hat{x}_i+\beta yi←γx^i+β
,这样使得网络能学到更多的分布,既可以保持原输入,也可以改变,提升了模型的泛化能力。
综合以上的步骤,可以得到BN的具体过程:

在训练过程中,在每一批的batch数据上,计算batch内的均值和方差,实现对输入数据的归一化。
在测试过程中,测试数据不在是batch的,而更多的可能是单条数据,对于BN的计算,[2]中给出的方法是使用所有mini-batch的均值和方差来估计出两个统计量:
E [ x ] ← E B [ μ B ] V a r [ x ] ← m m − 1 E B [ σ B 2 ] \begin{matrix} E\left [ x \right ]\leftarrow E_B\left [ \mu _B \right ] \\ Var\left [ x \right ]\leftarrow \frac{m}{m-1}E_B\left [ \sigma _B^2 \right ] \end{matrix} E[x]←EB[μB]Var[x]←m−1mEB[σB2]
2.2.2. 拆解大的卷积核
Inception v2针对v1的另一个优化是将其中的 5 × 5 5\times 5 5×5卷积核拆解成 2 2 2个 3 × 3 3\times 3 3×3的卷积核,如下图所示:

对于一个 5 × 5 5\times 5 5×5的卷积核可以拆解成 2 2 2个 3 × 3 3\times 3 3×3的卷积核,具体过程如下图所示:

2.2.3. Inception v2的网络结构
由上述分析,在Inception v2中将Inception模块中的 5 × 5 5\times 5 5×5的卷积核用两个相连的 3 × 3 3\times 3 3×3的卷积核替换。这一步的操作是使得模型的参数增加了25%,计算成本也提高了30%;同时将BN模块融合到网络中;除此之外,还对网络做了如下的一些修改,具体的网络结构如下图所示:

2.3. Inception v3
在Inception v2基础上,Google对之前提出的Inception模块进行了进一步的分析,在此基础上提出了较多的修改,这也成为了Inception v3[3]。Inception v3也成为了使用较多的GoogLeNet模型。
2.3.1. 设计神经网络的原则
在[3]中,提出了四条设计神经网络的原则,原文如下所示:
- Avoid representational bottlenecks, especially early in the network.
- Higher dimensional representations are easier to process locally within a network.
- Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power.
- Balance the width and depth of the network.
对此,简单的理解为:
- 在网络的浅层不能对特征过多降维,这样会带来较多的特征损失
- 原含义是说增加特征的维度,能够加快训练速度,更容易收敛,实际上是指在最后的分类层之前,增加特征维度,生成高维稀疏特征。
- 在低维Embedding中进行空间上的聚合,不会对模型的表征能力上造成较大影响,这部分主要解释 1 × 1 1\times 1 1×1的作用, 1 × 1 1\times 1 1×1卷积会进行空间上的聚合,减少参数,这样做不会带来较大的损失。
- 平衡宽度和深度,需要同时考虑。
2.3.2. 分解大卷积核
对于大的卷积核,在[3]中提出了两种分解的方法:
- 利用连续的两层小卷积核的卷积层代替大卷积层,如 5 × 5 5\times 5 5×5的卷积核可以由连续的两个 3 × 3 3\times 3 3×3的卷积核代替;
- 利用连续的两层非对称的卷积层代替原有卷积层,如 n × n n\times n n×n的卷积核可以由两个非对称的卷积核 n × 1 n\times 1 n×1和 1 × n 1\times n 1×n的卷积核代替。
具体如下图所示:

由上述的分析可知,这样做的好处能够减少参数量以及计算量。
2.3.3. 辅助分类器的作用
在Inception v1的模型中,在Inception模块的Inception(4a)和Inception(4d)后设置了辅助损失Loss,即辅助分类器。最初设计的思路是防止梯度在回传的过程中消失,即所谓的梯度消失现象,这样能方便模型的训练。然而,实验却发现在训练初期,有无辅助分类器对于模型效果并没有太大区别;在训练后期,有辅助分类器将提高模型的最终效果,辅助分类器更像是对模型起到了正则化的作用。
2.3.4. 减少特征图大小
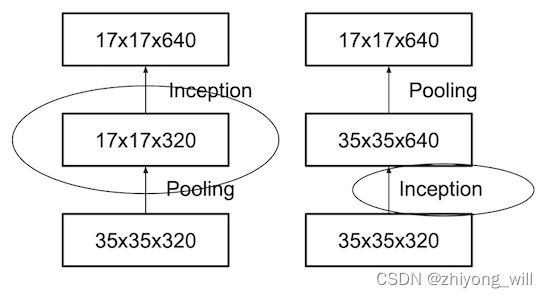
一般来说,在卷积神经网络中,随着深度的加深,pooling操作导致特征图的大小不断变小,这会导致信息的丢失。为了缓解这种现象,在特征图的宽与高缩小减半的同时,利用大小为 1 × 1 1\times 1 1×1的卷积层使得特征图的通道数量翻倍,即从 C × W × H C\times W\times H C×W×H变为 2 C × W 2 × H 2 2C\times \frac{W}{2}\times \frac{H}{2} 2C×2W×2H,通过这样的方式,以减少池化操作所带来的信息损失。为此,有两种选择:
- 先进行升维操作,再进行pooling操作
- 先进行pooling操作,再进行升维操作
两种方法对比后,显然第一种方法更合理,但是第一种方法的计算量显然是比第二种方法大的(直观看第一种方法需要在更大的特征图上进行卷积操作),两种方式如下图所示:
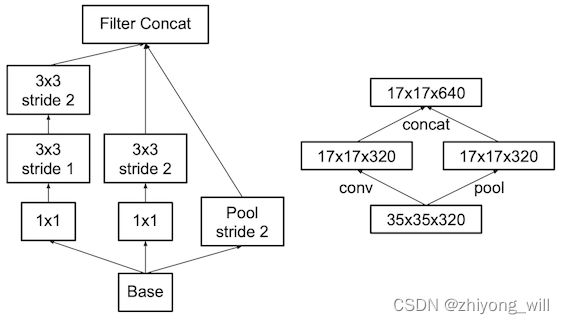
在[3]中提出了另一种方法减少计算量的折衷的方法,即将卷积模块和pooling模块并行,最后将两个模块的结果concat在一起,如下图所示:
3. 总结
更宽更深的网络对于提升网络效果起到了至关重要的作用,但同时也带来了很多的问题,如难以训练,计算代价等等,沿着这条路,Google提出了Inception模块,并将其引入到卷积神经网络中,同时在网络的训练过程中又增加了诸如辅助分类器等帮助模型训练的优化,使得能够训练出更宽更深的网络模型Inception v1,同时在Inception v1的基础上,又继续优化,提出BN模块加速训练,提出大卷积转成多个小卷积来加速计算,得到了Inception v2和Inception v3模型。Google在Inception结构上的优化还未停止,在这之后,又吸收了其他模型结构的优势,推出了Inception v4以及xInception等等。
参考文献
[1] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
[2] Sergey Ioffe, Christian Szegedy , Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. ICML, PMLR 37:448-456, 2015.
[3] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2818-2826.
[4] Lin M , Chen Q , Yan S . Network In Network[J]. Computer Science, 2013.