MECT: Multi-Metadata Embedding based Cross-Transformer forChinese Named Entity Recognition论文实验复现记录
萌新第一次复现实验,做得磕磕绊绊的,简单记录一下
也感谢zsh2517和yyc489的帮助!!
论文链接:https://arxiv.org/pdf/2104.07204.pdf
代码地址:https://github.com/CoderMusou/MECT4CNER
补充:
关于anaconda https://www.jianshu.com/p/62f155eb6ac5
pytorch 官网 https://pytorch.org/get-started/locally/
关于linux https://blog.csdn.net/qq_23329167/article/details/83856430
github上readme关于复现实验的步骤写的比较详细,按着做就好。
1、报错“IndexError: list index out of range”
经检查是 \MECT4CNER\Modules\CNNRadicalLevelEmbedding.py文件中 char2radical函数里的"return list(c_info[3])"(line 26)
github上问了作者,原来是因为我用的汉字部首数据集是漢語拆字字典,需要把c_info[3]改成c_info[0]
2、paths.py里的路径和modules文件中CNNRadicalLevelEmbedding.py里第12行的radical_path路径记得改成自己的!
3、如果嫌CPU跑太慢,选择GPU,一定要注意pytorch版本。
首先要下载CUDA,这篇要求的是CUDA10.1。然后去pytorch官网https://pytorch.org/点开下面的“previous version”找到想要的和CUDA对应的版本。
划重点!如果用镜像源很可能默认改成CPU版!如果用conda下载也会默认下载CPU版!其实用梯子去官网下载速度不算很慢。可以考虑通过wheel下载。直接复制粘贴到anaconda命令行里回车就行。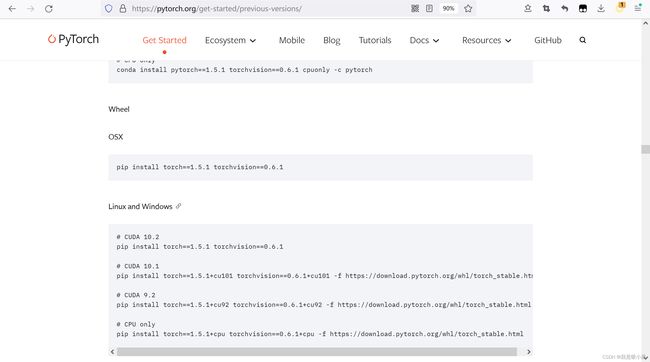
4、环境配置尽量按照readme里要求
(包括版本(比如注意这个程序用的是python3.7))
其他还有一些细节问题,百度就直接能查到(我也记不太清了hhh)。
5、我遇到的最大的问题:自己电脑的CPU和GPU都跑不动(轻薄本的痛)
有一种解决办法是改小batch_size,这个实验中是在main.py文件里
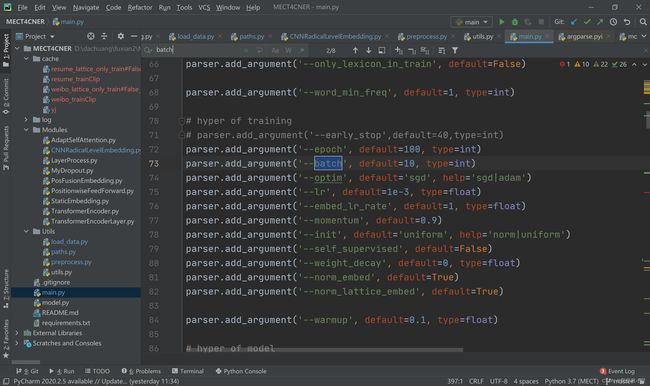
然而我的电脑改到最小也跑不动,而且 batch_size对模型的训练结果是有一定影响的,
所以,,最终我选择连接学校实验室的服务器,当时害怕极了因为我是第一次这么做
6、服务器
这里推荐powershell,用起来比cmd舒服一点。我们学校服务器是linux系统,这里推荐winscp,上传下载整理文件非常方便。
连接服务器:直接在powershell命令行输入ssh -p端口 用户名@IP 输入密码的时候不显示输入,光标也不会动(萌新表示好神奇)
先下载anaconda,后面的操作就和在自己电脑上几乎一模一样咯!create一个新env,安装相应的包就好了
但是有一个问题:一段时间不操作(哪怕正在跑数据)服务器连接就会断开。所以用到tmux。命令行输入tmux进入该界面,接下来正常操作输入命令行跑程序即可。运行起来后就可以断开连接了,等它跑完了再打开看结果就好。
那么,如何查看结果(程序输出)呢:
tmux ls 查看所有tmux窗口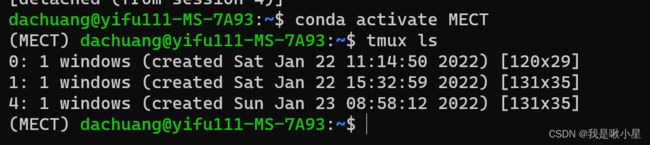
tmux attach -t xxx 打开目标tmux窗口
tmux不能用滚轮翻页有点麻烦。对于所有 tmux 的命令的快捷键,都是以 Ctrl+B 开头
Ctrl+b d 脱离
Ctrl+b w 切换窗口
Ctrl+b Fn+PgUp/Down 翻页
如何直接导出全部输出(不用自己一点一点复制粘贴):
tmux ls
tmux attach -t xxx(#进入要导出的界面)
Ctrl(按着)+B,然后松开, 之后 “:”
非滚动模式下,capture-pane -S -3000(#往上翻 3000 行。如果输出比 3000行多那么这个数字再大一些)
save-buffer ~/output.txt(#~ 表示家(home)目录,一般为 /home/用户名/ , 是个缩写)
这样就把结果以.txt形式保存到服务器根目录了(当然可以自己改路径存到某个文件夹),直接下载就可以保存到本地
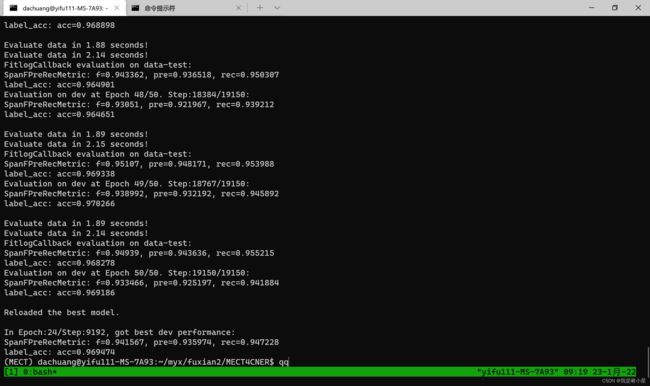
我只用了resume数据集,复现结果:
In Epoch:24/Step:9192, got best dev performance:
SpanFPreRecMetric: f=0.941567, pre=0.935974, rec=0.947228
label_acc: acc=0.969474
论文中写的结果:f1=95.89 pre=95.71, rec=95.77
和paper里的还是有差距,,感觉原因之一是我用的汉语偏旁语料库和论文中用的不太一样(github代码库中readme:“Get Chinese character structure components(radicals). The radicals used in the paper are from the online Xinhua dictionary. Due to copyright reasons, these data cannot be published. There is a method that can be replaced by 漢語拆字字典, but inconsistent character decomposition methods cannot guarantee repeatability.” 我用的是漢語拆字字典)