机器学习4. 决策树
目录
4-11 节11.决策树原理
4-12 节12.决策树代码实现
4-13 节13.决策树实验分析
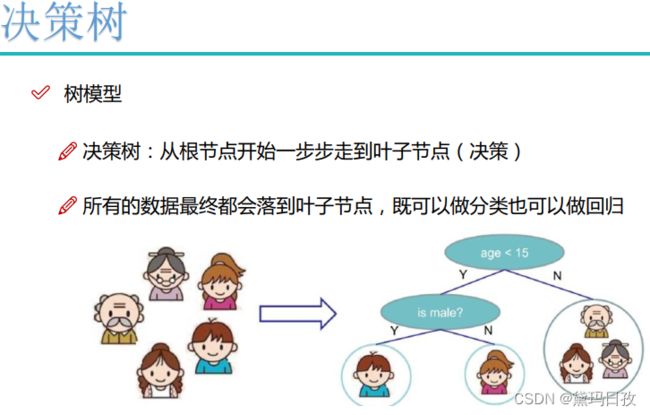
树模型的可视化展示¶
概率估计
决策树中的正则化
决策树模型对数据的敏感
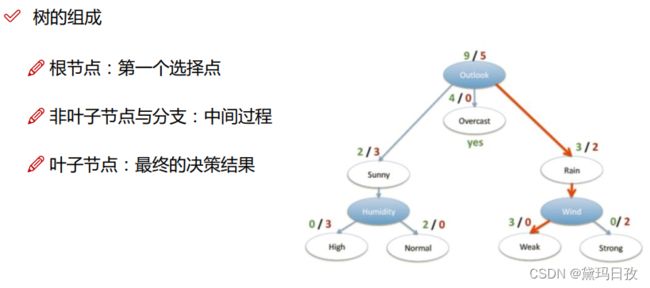
4-11 节11.决策树原理
属于有监督算法
既可以做分类也可以做回归(分类用样本到叶子节点众数代表的类别表示--其中用到熵值;回归用样本到叶子节点平均数表示--用到方差计算节点划分好坏)
数据可离散也可连续
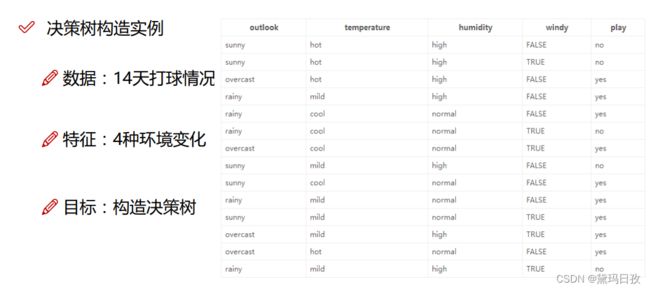
节点判断的先后顺序有严格的限制。


熵越来越小,不确定性越来越小。

信息增益。第一个节点根节点选择信息增益最大的,以此类推。
信息增益=系统原始熵值-采用特征X分类后的熵值
信息增益率=(系统原始熵值-采用特征X分类后的熵值)/ 特征X自身熵值
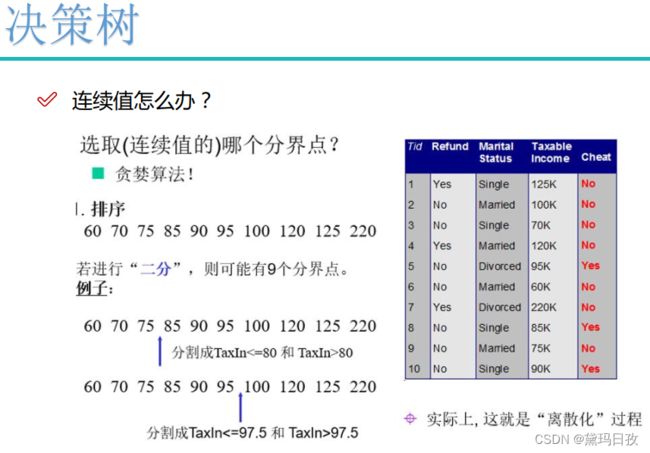
举例:




C4.5解决ID3z中没有考虑自身熵的问题

CART为二叉树,包括很多回归任务也是用二叉树表示。

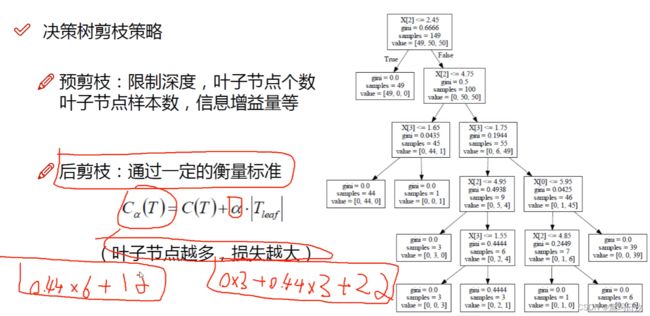
后剪枝用的比较少。下面公式用最下方左边两个叶子节点和其父节点举例说明。
4-12 节12.决策树代码实现
DecisionTree.py
# -*- coding: UTF-8 -*-
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
from math import log
import operator
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['F1-AGE', 'F2-WORK', 'F3-HOME', 'F4-LOAN']
return dataSet, labels
def createTree(dataset,labels,featLabels):
classList = [example[-1] for example in dataset]
if classList.count(classList[0]) == len(classList): #classList.count(classList[0])表示classList中值为classList[0]的个数。
return classList[0]
#ss = majorityCnt(classList)#ss = 'yes'
if len(dataset[0]) == 1: #特征已经遍历完,只剩下随后一列标签。
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataset)
bestFeatLabel = labels[bestFeat]
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}}
del labels[bestFeat]
featValue = [example[bestFeat] for example in dataset]
uniqueVals = set(featValue)
for value in uniqueVals:
sublabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataset,bestFeat,value),sublabels,featLabels)
return myTree
def majorityCnt(classList):
classCount={} #当classCount={'no': 6, 'yes': 9}
for vote in classList:
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
sortedclassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)#sortedclassCount = [('yes', 9), ('no', 6)]
return sortedclassCount[0][0]
def chooseBestFeatureToSplit(dataset):
numFeatures = len(dataset[0]) - 1
baseEntropy = calcShannonEnt(dataset) #计算数据初始的熵值。用数据最后一列类别列classList。
bestInfoGain = 0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataset]
uniqueVals = set(featList)#将列表中不重复的值用集合表示。
newEntropy = 0
for val in uniqueVals:
subDataSet = splitDataSet(dataset,i,val) #i为列的索引,代表某个特征列。
prob = len(subDataSet)/float(len(dataset))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def splitDataSet(dataset,axis,val):
retDataSet = []
for featVec in dataset:
if featVec[axis] == val:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def calcShannonEnt(dataset):
numexamples = len(dataset)
labelCounts = {}
for featVec in dataset:
currentlabel = featVec[-1]
if currentlabel not in labelCounts.keys():
labelCounts[currentlabel] = 0
labelCounts[currentlabel] += 1
shannonEnt = 0
for key in labelCounts:
prop = float(labelCounts[key])/numexamples
shannonEnt -= prop*log(prop,2)
return shannonEnt
def getNumLeafs(myTree):
numLeafs = 0
firstStr = next(iter(myTree))
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = next(iter(myTree))
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
arrow_args = dict(arrowstyle="<-")
font = FontProperties(fname=r"c:\windows\fonts\simsunb.ttf", size=14)
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args, FontProperties=font)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = next(iter(myTree))
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white') #创建fig
fig.clf() #清空fig
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴
plotTree.totalW = float(getNumLeafs(inTree)) #获取决策树叶结点数目
plotTree.totalD = float(getTreeDepth(inTree)) #获取决策树层数
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移
plotTree(inTree, (0.5,1.0), '') #绘制决策树
plt.show()
if __name__ == '__main__':
dataset, labels = createDataSet()
featLabels = []
myTree = createTree(dataset,labels,featLabels)#myTree = {'F3-HOME': {0: {'F2-WORK': {0: 'no', 1: 'yes'}}, 1: 'yes'}}
createPlot(myTree)4-13 节13.决策树实验分析
树模型的可视化展示¶
- 下载安装包:https://graphviz.org/download/
下载安装到E:\Graphviz
- 环境变量配置:https://jingyan.baidu.com/article/020278115032461bcc9ce598.html
如果安装过程中设置了添加环境变量则不再通过手动添加。
再进入windows命令行界面,输入dot -version,然后按回车,如果显示graphviz的相关版本信息,则安装配置成功。
如果要生成决策树图,在进入windows命令行界面,cd 切换到所生成的tree.dot所在的路径,执行 dot -Tpng tree.dot -o tree.png
概率估计
估计类概率 输入数据为:花瓣长5厘米,宽1.5厘米的花。 相应的叶节点是深度为2的左节点,因此决策树应输出以下概率:
- Iris-Setosa 为 0%(0/54),
- Iris-Versicolor 为 90.7%(49/54),
- Iris-Virginica 为 9.3%(5/54)。
tree_clf.predict_proba([[5,1.5]]) #tree_clf为训练好的决策树模型,输入为特征向量
array([[0. , 0.90740741, 0.09259259]])
tree_clf.predict([[5,1.5]])
array([1])决策树中的正则化
DecisionTreeClassifier类还有一些其他参数类似地限制了决策树的形状:
-
min_samples_split(节点在分割之前必须具有的最小样本数),
-
min_samples_leaf(叶子节点必须具有的最小样本数),
-
max_leaf_nodes(叶子节点的最大数量),
-
max_features(在每个节点处评估用于拆分的最大特征数)。
-
max_depth(树最大的深度)
决策树模型对数据的敏感
当数据旋转时,分类决策边界会变化。
决策树 - Jupyter Notebook中的内容如下:
即:决策树.ipynb
###决策树
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
###
树模型的可视化展示
下载安装包:https://graphviz.gitlab.io/_pages/Download/Download_windows.html
环境变量配置:https://jingyan.baidu.com/article/020278115032461bcc9ce598.html
petal
###
###
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:,2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X,y)
###
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
###
###
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
###
然后,你可以使用graphviz包中的dot命令行工具将此.dot文件转换为各种格式,如PDF或PNG。下面这条命令行将.dot文件转换为.png图像文件:
$ dot -Tpng iris_tree.dot -o iris_tree.png
###
from IPython.display import Image
Image(filename='iris_tree.png',width=400,height=400)
###决策边界展示
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
if plot_training:
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==2], X[:, 1][y==2], "g^", label="Iris-Virginica")
plt.axis(axes)
if iris:
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
if legend:
plt.legend(loc="lower right", fontsize=14)
plt.figure(figsize=(8, 4))
plot_decision_boundary(tree_clf, X, y)
plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2)
plt.plot([2.45, 7.5], [1.75, 1.75], "k--", linewidth=2)
plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2)
plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2)
plt.text(1.40, 1.0, "Depth=0", fontsize=15)
plt.text(3.2, 1.80, "Depth=1", fontsize=13)
plt.text(4.05, 0.5, "(Depth=2)", fontsize=11)
plt.title('Decision Tree decision boundaries')
plt.show()
###
概率估计
估计类概率 输入数据为:花瓣长5厘米,宽1.5厘米的花。 相应的叶节点是深度为2的左节点,因此决策树应输出以下概率:
Iris-Setosa 为 0%(0/54),
Iris-Versicolor 为 90.7%(49/54),
Iris-Virginica 为 9.3%(5/54)。
###
###
tree_clf.predict_proba([[5,1.5]])
###array([[0. , 0.90740741, 0.09259259]])
###
tree_clf.predict([[5,1.5]])
###array([1])
###
决策树中的正则化
DecisionTreeClassifier类还有一些其他参数类似地限制了决策树的形状:
min_samples_split(节点在分割之前必须具有的最小样本数),
min_samples_leaf(叶子节点必须具有的最小样本数),
max_leaf_nodes(叶子节点的最大数量),
max_features(在每个节点处评估用于拆分的最大特征数)。
max_depth(树最大的深度)
###
###
from sklearn.datasets import make_moons
X,y = make_moons(n_samples=100,noise=0.25,random_state=53)
tree_clf1 = DecisionTreeClassifier(random_state=42)
tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4,random_state=42)
tree_clf1.fit(X,y)
tree_clf2.fit(X,y)
plt.figure(figsize=(12,4))
plt.subplot(121)
plot_decision_boundary(tree_clf1,X,y,axes=[-1.5,2.5,-1,1.5],iris=False)
plt.title('No restrictions')
plt.subplot(122)
plot_decision_boundary(tree_clf2,X,y,axes=[-1.5,2.5,-1,1.5],iris=False)
plt.title('min_samples_leaf=4')
Text(0.5, 1.0, 'min_samples_leaf=4')
###决策树模型对数据的敏感
np.random.seed(6)
Xs = np.random.rand(100, 2) - 0.5
ys = (Xs[:, 0] > 0).astype(np.float32) * 2
angle = np.pi / 4
rotation_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]])
Xsr = Xs.dot(rotation_matrix)
tree_clf_s = DecisionTreeClassifier(random_state=42)
tree_clf_s.fit(Xs, ys)
tree_clf_sr = DecisionTreeClassifier(random_state=42)
tree_clf_sr.fit(Xsr, ys)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_decision_boundary(tree_clf_s, Xs, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
plt.title('Sensitivity to training set rotation')
plt.subplot(122)
plot_decision_boundary(tree_clf_sr, Xsr, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
plt.title('Sensitivity to training set rotation')
plt.show()
###回归任务
np.random.seed(42)
m=200
X=np.random.rand(m,1)
y = 4*(X-0.5)**2
y = y + np.random.randn(m,1)/10
###
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X,y)
###
DecisionTreeRegressor(criterion='mse', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
###
###
export_graphviz(
tree_reg,
out_file=("regression_tree.dot"),
feature_names=["x1"],
rounded=True,
filled=True
)
#### 你的第二个决策树长这样
from IPython.display import Image
Image(filename="regression_tree.png",width=400,height=400,)
###对比树的深度对结果的影响
###
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(random_state=42, max_depth=2)
tree_reg2 = DecisionTreeRegressor(random_state=42, max_depth=3)
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
def plot_regression_predictions(tree_reg, X, y, axes=[0, 1, -0.2, 1], ylabel="$y$"):
x1 = np.linspace(axes[0], axes[1], 500).reshape(-1, 1)
y_pred = tree_reg.predict(x1)
plt.axis(axes)
plt.xlabel("$x_1$", fontsize=18)
if ylabel:
plt.ylabel(ylabel, fontsize=18, rotation=0)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_regression_predictions(tree_reg1, X, y)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2)
plt.text(0.21, 0.65, "Depth=0", fontsize=15)
plt.text(0.01, 0.2, "Depth=1", fontsize=13)
plt.text(0.65, 0.8, "Depth=1", fontsize=13)
plt.legend(loc="upper center", fontsize=18)
plt.title("max_depth=2", fontsize=14)
plt.subplot(122)
plot_regression_predictions(tree_reg2, X, y, ylabel=None)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2)
for split in (0.0458, 0.1298, 0.2873, 0.9040):
plt.plot([split, split], [-0.2, 1], "k:", linewidth=1)
plt.text(0.3, 0.5, "Depth=2", fontsize=13)
plt.title("max_depth=3", fontsize=14)
plt.show()
###
tree_reg1 = DecisionTreeRegressor(random_state=42)
tree_reg2 = DecisionTreeRegressor(random_state=42, min_samples_leaf=10)
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred1 = tree_reg1.predict(x1)
y_pred2 = tree_reg2.predict(x1)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred1, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", fontsize=18, rotation=0)
plt.legend(loc="upper center", fontsize=18)
plt.title("No restrictions", fontsize=14)
plt.subplot(122)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred2, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.title("min_samples_leaf={}".format(tree_reg2.min_samples_leaf), fontsize=14)
plt.show()