Python NumPy ndarray 数组的运算 广播 排序sort 去重unique 重复repeat
一、广播机制。
二、数组运算。
三、Numpy的计算速度。
四、数组排序sort 和 argsort。
五、重复repeat 和 title。
六、去重unique。
七、通用函数。
一、广播机制。
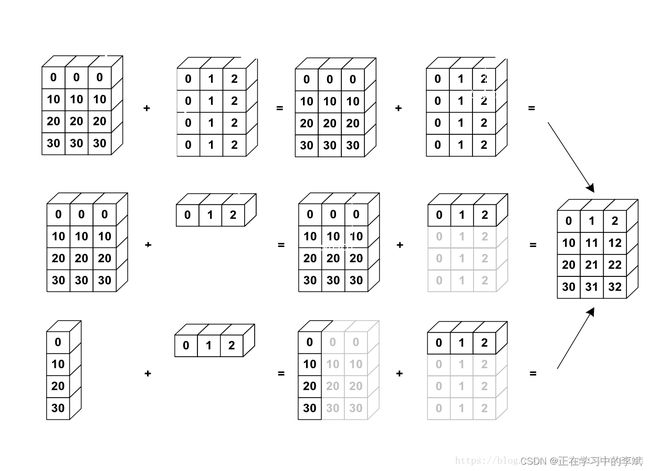
NumPy中的广播机制并不容易理解,特别是在进行高维数组计算的时候。为了更好地使用广播机制,需要遵循4个原则。
- 让所有的输入数组向其中shape最长的数组看齐,shape中不足的部分通过在前面加1补齐。
- 输出数组的shape是输入数组shape的各个轴上的最大值。
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为 1,则这个数组能够用来计算,否则出错。
- 当输入数组的某个轴的长度为1时,沿着此轴运算时使用此轴上的第一组值。
1. 在 python 中。
如果用python的列表进行相加,那只是简单的对两个列表进行拼接,无法完成数组运算。a-b 则会报错。
a = [[0, 0, 0], [10, 10, 10], [20, 20, 20], [30, 30, 30]]
b = [[0, 1, 2], [0, 1, 2], [0, 1, 2], [0, 1, 2]]
a, b, a + b
# 会报错
a-b
2. 在 numpy 中。
维度不同的数组是可以相加的。
import numpy as np
a = np.array([[0, 0, 0], [10, 10, 10], [20, 20, 20], [30, 30, 30]])
b = np.array([[0, 1, 2], [0, 1, 2], [0, 1, 2], [0, 1, 2]])
a, b, a + b
a = np.array([[0, 0, 0], [10, 10, 10], [20, 20, 20], [30, 30, 30]])
b = np.array([0, 1, 2])
a, b, a + b
#-------------------------------------------------------------------------------------
# 如果两个数组元素个数不一致,就不能相加
# numpy的广播指的是在不同维度上进行广播,而在同一维度上元素格式不一样是没法直接计算的。
a = np.array([0, 10, 20, 30])
b = np.array([0, 1, 2])
a, b, a.shape, b.shape
# 报错
a + b
# 将 a 变成 4*1 二维数组。则可以
a.reshape(-1, 1) + b
二、运算。
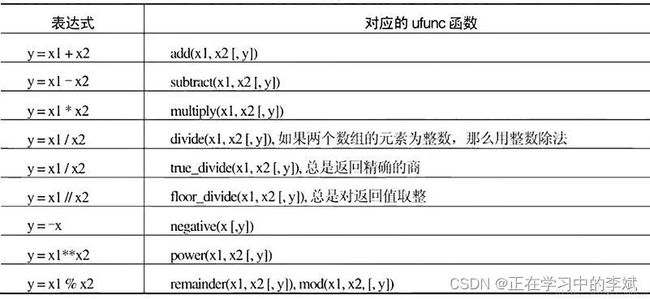
python中的运算符在Numpy中也全都可以使用,除了最常见的 ±/ 以外,还有取余(%),取商的整数部分(//),以及幂运算(*)
1. 数组与数值的运算
import numpy as np
x = np.array([1,2,3])
x + 10
x - 3.2
x * 2
x / 0.15
x // 3
x % 3
2. 数组与数组的运算
import numpy as np
x = np.array([1,2,3])
y = np.array([4,5,6])
x + y
x - y
x * y
x / y
x ** y # x的y次方
y // x # 求商
y % x # 取余
x.reshape(-1, 1) + y
x.reshape(-1, 1) - y
x.reshape(-1, 1) * y
x.reshape(-1, 1) / y
3. 比较与逻辑运算
在NumPy逻辑运算中,np.all函数表示逻辑and,对数组所有元素做’与’操作,所有为True则返回True。
np.any函数表示逻辑or,对数组所有元素做’或’操作,存在True则返回True。
import numpy as np
x = np.array([1,5,7])
y = np.array([4,5,6])
x<y
x[x<y]
x>y
x==y
x<=y
x>=y
x!=y
# ---------------------------------------------------------------------
# 在NumPy逻辑运算中,np.all函数表示逻辑and,对数组所有元素做'与'操作,
# 所有为True则返回True。np.any函数表示逻辑or,对数组所有元素做'或'操作,存在True则返回True。
np.all(x == y)
np.any(x == y)
三、Numpy的计算速度。
Numpy最大优势就在计算中实现矢量化,不用再对每个元素进行循环迭代,极大提升了效率。所以下面通过对10000个数进行平方求和,对比Numpy和普通循环迭代的计算速度。
import numpy as np
def pySum():
a = list(range(10000))
b = list(range(10000))
c = []
for i in range(len(a)):
c.append(a[i]**2 + b[i]**2)
return c
%timeit pySum()
# --------------------------------------------
def npSum():
a = np.arange(10000)
b = np.arange(10000)
c = a**2 + b**2
return c
%timeit npSum()
# ---------------------------------------------
def npSum():
a = np.arange(10000)
b = np.arange(10000)
c = np.add(np.power(a,2), np.power(b,2))
return c
%timeit npSum()
四、排序sort和argsort。
直接排序使用 sort()函数,间接排序使用argsort()函数。

import numpy as np
arr = np.array([7, 9, 5, 2, 9, 4, 3, 1, 4, 3])
arr.sort() # 或者 np.sort(arr)
arr
# -----------------------------------------------------------------
arr = np.array([[4, 2, 9, 5], [6, 4, 8, 3], [1, 6, 2, 4]])
arr.sort(axis=1)
# --------------------------------------------------------------------
arr = np.array([[4, 2, 9, 5], [6, 4, 8, 3], [1, 6, 2, 4]])
arr.sort(axis=0)
import numpy as np
arr = np.array([7, 9, 5, 2, 9, 4, 3, 1, 4, 3])
arr
# 返回的是索引
arr.argsort()
五、重复repeat和tile。
Numpy中数组扩展或者重复主要靠repeat()和tile()这两个函数,这两者本质都是进行复制的操作
1. repeat() 复制的是多维数组的每一个元素
import numpy as np
# 复制的是多维数组的每一个元素
arr = np.arange(5)
np.repeat(arr, 2)
# out array([0, 0, 1, 1, 2, 2, 3, 3, 4, 4])
# ------------------------------------------------------
# 二维数组重复
# 如果没有指明重复的axis,那么高维数组会flatten至一维
arr = np.arange(4).reshape(2, 2)
np.repeat(arr, 2)
# array([0, 0, 1, 1, 2, 2, 3, 3])
# 将高维flatten至一维,并非经常使用的操作。
# 更经常的操作还是再某一轴上进行复制,比如在行的方向上(axis=1),在列的方向上(axis=0)。
arr = np.arange(4).reshape(2, 2)
np.repeat(arr, 2, axis=0)
2. tile()复制的是多维数组本身,不需要 axis 关键字参数,仅通过第二个参数便可指定在各个轴上的复制倍数。
import numpy as np
# 行复制3倍,列复制2倍
arr = np.arange(4)
np.tile(arr, [3, 2])
六、去重unique。
1. 一维数组
import numpy as np
arr = np.array([1, 2, 2, 5, 3, 4, 3])
np.unique(arr)
# --------------------------------------------
# unique()函数里可以设置return_index=True参数,表示返回新列表元素在旧列表中的位置,并以列表形式储存。
a, index = np.unique(arr, return_index=True)
a, index
# out (array([1, 2, 3, 4, 5]), array([0, 1, 4, 5, 3]))
# --------------------------------------------------------------
# unique()函数里可以设置return_inverse=True参数,表示返回旧列表元素在新列表中的位置,并以列表形式储存。
a, index = np.unique(arr, return_inverse=True)
a, index
# out (array([1, 2, 3, 4, 5]), array([0, 1, 1, 4, 2, 3, 2]))
2. 二维数组
import numpy as np
arr = np.array([(1,2,3,4), (1,2,3,4), (7,8,3,4), (5,6,3,8)])
arr
# 删除多余重复行
np.unique(arr, axis=0)
# 设置return_counts=True参数,还返回每个唯一项出现在数组中的次数。
# 第一行出现2次,第二行出现1次,第三行出现2次
arr, uniq_cnt = np.unique(arr, axis=0, return_counts=True)
# out (array([[1, 2, 3, 4],
# [5, 6, 3, 8],
# [7, 8, 3, 4]]),
# array([2, 1, 1]))
# 获取非重复行
arr[uniq_cnt==1]
#------------------------------------------------------------------------------
a, s, p = np.unique(arr, axis=0, return_index=True, return_inverse=True)
七、通用函数。
最常用的9个函数,其中最主要的参数就是axis,通过指定axis来选择是进行横向还是纵向的统计,不具体指出的话就是整体对整个数组进行统计。
import numpy as np
arr = np.array([[ 0, 1, 20, 1, 4, 5],
[ 6, 7, 8, 8, 10, 11],
[ 3, 6, 6, -8, 14, 8]])
arr.sum() # 求和
arr.mean() # 平均
arr.var() # 方差
arr.std() # 标准差
arr.max(), arr.min() # 最大 最小值
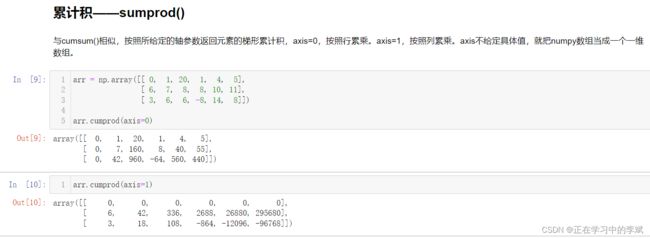
cumsum() # 累计和
sumprod() # 累计积