InteractE: Improving Convolution-Based Knowledge Graph Embeddings by Increasing Feature Interactions
其它关于卷积知识图谱补全:
ConvR:Adaptive Convolution for Multi-Relational Learning
ConvE:Convolutional 2D Knowledge Graph Embeddings
ConvKB代码:A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network
1 介绍
1.1 引言
本篇论文是对于论文ConvE的模型进行改进,与ConvR论文类似,其都发现ConvE在实现实体entity与relation之间,进行交互时,只是进行简单的进行entity和relation之间的向量进行简单的堆积,其交互能力很低(来源于ConvR论文),大于只有20%的交互,与ConvR相比,该论文InteractE采用另外一种策略,增加其交互能力。
1.2 提高交互方法
- feature permutation(特征进行全排类)
- a novel feature reshaping(新型的reshape方式)
- circular convolution(循环神经网络)
2 模型
2.1 Feature Permutation
生成 e s e_s es和 e r e_r er的t-random排列, P t = [ ( e s 1 , e r 1 ) , . . . . , ( e s t , e r t ) ] \mathcal P_{t} = [(e_s^1, e_r^1), ....,(e_s^t, e_r^t)] Pt=[(es1,er1),....,(est,ert)]作为一组,进行随机打乱,进行t次,每次随机打乱产生一组数据,产生t次数据,其作为输入数据的int_channel则为t,但由于所有的数据本质上是一样的,对每层进行卷积的卷积核应该一致,应该在初始时是一致的,在具体实现时采用分组卷积的形式。
2.2 Reshaping Function

- Stack
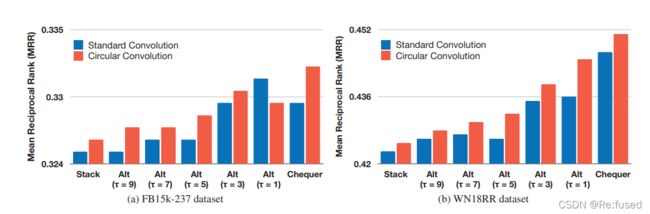
堆叠的形式,ConvE在实现时采用这种方式,其交互能力很低,只有20%,但其操作比较简单。
- Alternate
交替形式,其采用实体的feature和关系的feature交替的方式,能有效的提高交互,交互能力有所提升。
- Chequer
这种方式交互更加彻底,其在使用时,将其所有元组进行交替,能够更加充分。
2.3 循环卷积
常规的卷积,在使用时,边界与边界之间没有任何关系,因此提出循环卷积,在卷积的时候,使其边界之间的内容进行交互。其交互的方式是使边界 ⌊ k / 2 ⌋ \lfloor {k/2} \rfloor ⌊k/2⌋,其中k为kernal_size。在实现时,将 ⌊ k / 2 ⌋ \lfloor {k/2} \rfloor ⌊k/2⌋左侧内容放到右侧边界, ⌊ k / 2 ⌋ \lfloor {k/2} \rfloor ⌊k/2⌋右侧内容放到左侧;同理下侧放到上侧,上侧放到下侧。
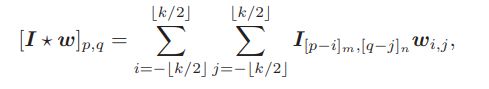
图解循环卷积:
2.4 整体模型图

- 将头实体 e s 和 e r e_s和e_r es和er进行全排列,进行t次全排列,产生t个通道
- 进行reshape,采用Chequer方式进行reshape
- 进行卷积,采用循环卷积
- 进行全连接,映射维度为 e s e_s es的维度一致
- 进行1-N评分,进行rank评分
2.5 评分函数
![]()
3 总结

4 代码
来源:在这
from helper import *
class InteractE(torch.nn.Module):
"""
Proposed method in the paper. Refer Section 6 of the paper for mode details
Parameters
----------
params: Hyperparameters of the model
chequer_perm: Reshaping to be used by the model
Returns
-------
The InteractE model instance
"""
def __init__(self, params, chequer_perm):
super(InteractE, self).__init__()
self.p = params
self.ent_embed = torch.nn.Embedding(self.p.num_ent, self.p.embed_dim, padding_idx=None); xavier_normal_(self.ent_embed.weight)
self.rel_embed = torch.nn.Embedding(self.p.num_rel*2, self.p.embed_dim, padding_idx=None); xavier_normal_(self.rel_embed.weight)
self.bceloss = torch.nn.BCELoss()
self.inp_drop = torch.nn.Dropout(self.p.inp_drop)
self.hidden_drop = torch.nn.Dropout(self.p.hid_drop)
self.feature_map_drop = torch.nn.Dropout2d(self.p.feat_drop)
self.bn0 = torch.nn.BatchNorm2d(self.p.perm)
flat_sz_h = self.p.k_h
flat_sz_w = 2*self.p.k_w
self.padding = 0
self.bn1 = torch.nn.BatchNorm2d(self.p.num_filt*self.p.perm)
self.flat_sz = flat_sz_h * flat_sz_w * self.p.num_filt*self.p.perm
self.bn2 = torch.nn.BatchNorm1d(self.p.embed_dim)
self.fc = torch.nn.Linear(self.flat_sz, self.p.embed_dim)
self.chequer_perm = chequer_perm
self.register_parameter('bias', Parameter(torch.zeros(self.p.num_ent)))
self.register_parameter('conv_filt', Parameter(torch.zeros(self.p.num_filt, 1, self.p.ker_sz, self.p.ker_sz))); xavier_normal_(self.conv_filt)
#96
def loss(self, pred, true_label=None, sub_samp=None):
label_pos = true_label[0];
label_neg = true_label[1:]
loss = self.bceloss(pred, true_label)
return loss
def circular_padding_chw(self, batch, padding):
upper_pad = batch[..., -padding:, :]
lower_pad = batch[..., :padding, :]
temp = torch.cat([upper_pad, batch, lower_pad], dim=2)
left_pad = temp[..., -padding:]
right_pad = temp[..., :padding]
padded = torch.cat([left_pad, temp, right_pad], dim=3)
return padded
def forward(self, sub, rel, neg_ents, strategy='one_to_x'):
sub_emb = self.ent_embed(sub)
rel_emb = self.rel_embed(rel)
comb_emb = torch.cat([sub_emb, rel_emb], dim=1)
chequer_perm = comb_emb[:, self.chequer_perm]
stack_inp = chequer_perm.reshape((-1, self.p.perm, 2*self.p.k_w, self.p.k_h))
stack_inp = self.bn0(stack_inp)
x = self.inp_drop(stack_inp)
x = self.circular_padding_chw(x, self.p.ker_sz//2)
x = F.conv2d(x, self.conv_filt.repeat(self.p.perm, 1, 1, 1), padding=self.padding, groups=self.p.perm)
x = self.bn1(x)
x = F.relu(x)
x = self.feature_map_drop(x)
x = x.view(-1, self.flat_sz)
x = self.fc(x)
x = self.hidden_drop(x)
x = self.bn2(x)
x = F.relu(x)
if strategy == 'one_to_n':
x = torch.mm(x, self.ent_embed.weight.transpose(1,0))
x += self.bias.expand_as(x)
else:
x = torch.mul(x.unsqueeze(1), self.ent_embed(neg_ents)).sum(dim=-1)
x += self.bias[neg_ents]
pred = torch.sigmoid(x)
return pred