Python深度学习基础(八)——线性回归
线性回归
- 引言
- 损失函数
- 解析解
-
- 公式
- 代码
- 实例
- 梯度下降
-
- 理论
- 随机梯度下降的手动实现代码
- torch中的随机梯度下降
引言
我们生活中可能会遇到形如
y = w 1 x 1 + w 2 x 2 + w 3 x 3 + b y=w_1x_1+w_2x_2+w_3x_3+b y=w1x1+w2x2+w3x3+b
的问题,其中有y为输出,x为输入,w为权值,b为偏置
假设我们有一个房价预测的问题,我们有很多条数据,每一个数据项有很多特征,这些特征就是x,而房价就是y,线性回归要解决的就是得出一批合适的w和b来实现x向y的映射,使得我们得到x时就可以预测出y。
损失函数
为了求得权值和偏置的最优值,我们需要定义损失函数,通过降低损失函数的损失进行权值和偏置的优化,我们常用的有如下三种损失值
均方误差
l ( w , b ) = 1 2 ( x w + b − y ) 2 l(w, b)=\frac{1}{2}(xw+b-y)^2 l(w,b)=21(xw+b−y)2
这里的1/2并没有什么含义,只是为了求导后计算方便
在多个样本上可以表述为
L ( W , b ) = 1 2 n ∑ i = 1 n ( X ( i ) W + b − Y ( i ) ) 2 L(W, b)= \frac{1}{2n}\sum_{i=1}^n(X^{(i)}W+b-Y^{(i)})^2 L(W,b)=2n1i=1∑n(X(i)W+b−Y(i))2
同时为了方便处理,通常我们会在数据后加一列1,这样偏置也会并入到权值当中,即
[ x 1 ( 1 ) x 2 ( 1 ) 1 x 1 ( 2 ) x 2 ( 2 ) 1 x 1 ( 3 ) x 2 ( 3 ) 1 ] ⋅ [ w 1 w 2 b ] = [ y ( 1 ) y ( 2 ) y ( 3 ) ] \begin{bmatrix} x_1^{(1)}&x_2^{(1)}&1\\ x_1^{(2)}&x_2^{(2)}&1\\ x_1^{(3)}&x_2^{(3)}&1\\ \end{bmatrix} \cdot \begin{bmatrix} w_1 \\ w_2 \\ b \end{bmatrix}= \begin{bmatrix} y^{(1)} \\ y^{(2)} \\ y^{(3)} \end{bmatrix} x1(1)x1(2)x1(3)x2(1)x2(2)x2(3)111 ⋅ w1w2b = y(1)y(2)y(3)
我们令
注:为了方便表示,这里用三个数据,每个数据有两个数据项的数据表示
我们令
W = [ w 1 w 2 b ] W=\begin{bmatrix} w_1 \\ w_2 \\ b \end{bmatrix} W= w1w2b
那么我们的均方误差就变成了
L ( W , b ) = 1 2 n ∑ i = 1 n ( X ( i ) W − Y ( i ) ) 2 L(W, b)= \frac{1}{2n}\sum_{i=1}^n(X^{(i)}W-Y^{(i)})^2 L(W,b)=2n1i=1∑n(X(i)W−Y(i))2
解析解
线性回归问题存在解析解
公式
首先我们在L上对W求导
∇ w L = 1 n ∑ i = 1 n ( X ( i ) W − Y ( i ) ) T X ( i ) \nabla _wL= \frac{1}{n} \sum_{i=1}^n(X^{(i)}W-Y^{(i)})^{T}X^{(i)} ∇wL=n1i=1∑n(X(i)W−Y(i))TX(i)
最优的解即为L=0的解,即
W ( ∗ ) T X ( i ) T X ( i ) − Y ( i ) T X ( i ) = 0 ⇒ W ( ∗ ) T = Y ( i ) T X ( i ) ( X ( i ) T X ( i ) ) − 1 ⇒ W ( ∗ ) = ( X ( i ) T X ( i ) ) − 1 X ( i ) T Y ( i ) W^{(*)T}X^{(i)T}X^{(i)}-Y^{(i)T}X^{(i)}=0 \\ \Rightarrow W^{(*)T}=Y^{(i)T}X^{(i)}(X^{(i)T}X^{(i)})^{-1} \\ \Rightarrow W^{(*)} = (X^{(i)T}X^{(i)})^{-1} X^{(i)T}Y^{(i)} W(∗)TX(i)TX(i)−Y(i)TX(i)=0⇒W(∗)T=Y(i)TX(i)(X(i)TX(i))−1⇒W(∗)=(X(i)TX(i))−1X(i)TY(i)
代码
如果使用numpy,假设我们有X和y这个过程可以表述为
# 第一步是增加一列1,这样可以使得w和b合并
X_b = np.c_[np.ones((X.shape[0], 1)), X]
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
其中np.linalg.inv是求矩阵的逆
实例
import torch
from torch.utils import data
import numpy as np
import random
首先我们定义一个生成数据的函数
def synthetic_data(w, b, num_examples):
X = torch.normal(0, 1, (num_examples, w.shape[0])) # 生成均值为0,方差为1的数据
y = torch.matmul(X, w) + b # 生成标签
y += torch.normal(0, 0.01, y.shape) # 均值为0,方差为0.01的正态分布
return X, y.reshape((-1, 1))
我们假设w为[2, -3.4],b为4.2,我们生成线性数据
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
我们将w和b合并
X = np.array(features)
X_b = np.c_[np.ones((X.shape[0], 1)), X]
y = np.array(labels)
获得解析解
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
theta_best
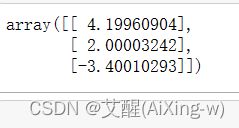
可以看到权值和偏置的解析解基本与真实值相同
梯度下降
理论
但是不是所有的问题都可以得到解析解,所以我们一般使用梯度下降的方式进行优化,优化方式是:各个参数沿着梯度的反方向更新,梯度方向就是方向导数最大的方向,用公式表示
( w , b ) ← ( w , b ) − ∇ ( w , b ) L (w, b) \leftarrow (w, b)-\nabla _{(w, b)}L (w,b)←(w,b)−∇(w,b)L
随机梯度下降的手动实现代码
数据迭代器
首先为了读出数据,我们先创建一个函数作为数据迭代器,其本质是生成器,安装小梯度的梯度大小生成数据
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i:min(i+batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
权值和偏置初始化
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
定义线性模型
def linreg(X, w, b):
return torch.matmul(X, w) + b
定义损失函数
def squared_loss(y_hat, y):
return (y_hat - y) ** 2 / 2
定义随机梯度下降优化器
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
参数设置
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
训练模型
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features,labels):
l = loss(net(X, w, b), y) # 小批量损失
l.sum().backward() # 总损失进行反向传递
sgd([w, b], lr, batch_size)
with torch.no_grad():
train_1 = loss(net(features, w, b), labels)
print(f'epoch {epoch+1}, loss:{float(train_1.mean()):f}')
结果如下:
epoch 1, loss:0.033043
epoch 2, loss:0.000118
epoch 3, loss:0.000050
求损失
print(f'w损失:{true_w - w.reshape(true_w.shape)}')
print(f'b损失:{true_b - b}')
结果如下:
w损失:tensor([ 0.0007, -0.0011], grad_fn=
)
b损失:tensor([0.0002], grad_fn=)
torch中的随机梯度下降
数据加载器
使用torch.utils中的data来构建数据加载器
使用data.TensorDataset从tensor格式的数据中构建数据集,传入的参数应该是数据和标签组成的元组
使用data.DataLoader,传入数据集和批量大小,以及是否打乱顺序,使用这个函数按照批量大小加载数据
def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
设置参数
batch_size = 10
data_iter = load_array((features, labels), batch_size)
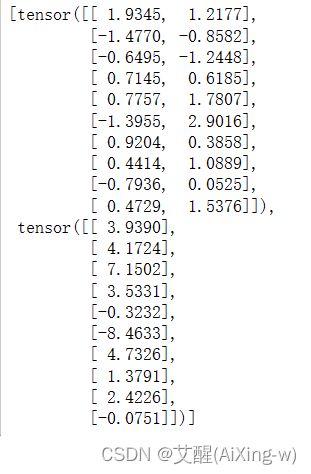
next(iter(data_iter))
结果如下:
构建模型
在torch中,Linear为全连接层,通过Sequential构建线性模型
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
help(nn.Linear)
在其中可以看到Attributes里边有weight和bias,通过这个函数我们可以获取权值和偏置

net[0].weight
结果如下:
Parameter containing:
tensor([[0.6657, 0.1449]], requires_grad=True)
net[0].bias
结果如下:
Parameter containing:
tensor([-0.6534], requires_grad=True)
help(net[0].weight)
这里我们可以看到使用data可以查看weight的数据

net[0].weight.data
tensor([[0.6657, 0.1449]])
初始化权值和偏置
我们使用均值为0,方差为0.01的正态分布的数据初始化weight,将偏置设置为0
net[0].weight.data.normal_(0, 0.01)
tensor([[-0.0092, 0.0053]])
net[0].weight.data
tensor([[-0.0092, 0.0053]])
net[0].bias.data.fill_(0)
tensor([0.])
net[0].bias.data
tensor([0.])
损失函数和优化器
选用均方误差作为损失函数,随机梯度下降优化参数
loss = nn.MSELoss()
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
训练
num_epochs= 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch:{epoch+1}, loss:{l:f}')
epoch:1, loss:0.000201
epoch:2, loss:0.000100
epoch:3, loss:0.000100
net[0].weight.data
tensor([[ 1.9992, -3.3989]])
net[0].bias.data
tensor([4.2002])
print(f'w损失:{net[0].weight.data - true_w}')
print(f'b损失:{net[0].bias.data - true_b}')
w损失:tensor([[-0.0008, 0.0011]])
b损失:tensor([0.0002])