caffe用自己的数据集训练深度网络模型——windows平台适用
斯坦福公开课-深度学习计算机视觉说到caffe用来训练一个基本的深度网络模型,改几个配置文件就好了,不用写代码!当时,我就震惊了!赶紧试试。
caffe训练深度网络模型
caffe训练深度神经网络不需要写代码,听上去是挺好的,但只是一个噱头。如果不写代码,caffe里面很多东西就不能自己更改,而且为了符合caffe的程序,达到训练深度网络模型的效果,caffe对输入输出会有严格要求,比如,想要定义自己网络层layer结构,使用自己的求解算法,这时候不自己写代码,基本不可能实现;caffe训练网络时,会要求你的样本有训练集和测试集,而且分类和标签都有严格规定,否则直接报错,不让你训练模型。
当然如果你只是想要用caffe做做简单实验,你可以用本文的方法试试,我不保证测试的正确率会高哦。
下面以 训练AlexNet模型用于图片二分类 为例,具体讲解不写代码的整个caffe训练(train)、测试(test)过程。
caffe训练深度神经网络的前期准备
前面说到,caffe训练深度神经网络如果不写代码,需要修改几个配置文件,所以一些前期工作还是要做的。
- 准备样本,也就是train样本(训练样本)。样本主要用来训练和测试,需要该样本有标记。需要注意的是,如果是对图片进行多分类,则每一类样本的数量比例最好1:1。
- 准备caffe源码,这里提供的是windows版本。
- 编译好caffe,如果还没有配置成功的,请移步这里。
- 当然还得有深度学习的基本知识,要不然几个配置文件还是看不懂的。
caffe训练的大致流程
- 将整个train样本分为train数据集和test数据集两个数据集。这里的train样本必须是有标记的,如果你已经有了train样本和test样本(test样本也必须有标记),可以直接将其作为train数据集和test数据集。
- 将train数据集和test数据集分别转化为对应的lmdb数据集(或者leveldb数据集,这两种数据库的区别是lmdb读取快,但是占用空间大)。
- 分别计算train数据集的均值,另存为.binaryproto均值文件。(AlexNet需要这个,有一些其他模型似乎不需要,如GoogLeNet)
- 修改模型的网络结构文件train_val.prototxt文件,添加lmdb数据集和均值文件的路径。(这个文件后面会说的)
- 修改模型的solver.prototxt,该文件包含一些超参数的设置,如迭代次数、学习率设置,以及网络结构文件的路径设置和是否使用GPU加速等。
- 使用编译好的caffe.exe进行模型训练和测试。
- 附加:使用classification.exe对未知标签的样本进行分类。
以上是基本流程,数值计算和模型训练基本上都要在cmd命令行下操作。下面是详细的过程
准备样本
很多人都有一些标注好的样本,而且已经分好了,但你如果不写代码就想用caffe来训练模型,那你的样本说不定得重新分,因为官方的caffe对样本的划分有自己的要求;如果不想重新划分样本,那还是写代码吧!
学过机器学习的人都知道,样本的重要性,这里我就只想强调一下:真的非常重要!
其实样本严格划分的作用在后面的配置文件修改中会有体现,本来应该先看看配置文件的,但为了一套流程的完整,还是先从样本准备开始说起。(再次提醒:这里的任务是对图片进行二分类,多分类是类似的)
- caffe训练时,需要有两个图片数据集分别用于训练和测试,这里就简称为train集(训练集)和test集(测试集),分别对应于train文件夹和test文件夹。
- train文件夹里面必须包含有所有类别的图片,且每一类的图片数量比例最好保持或者接近1:1,test文件夹也一样。train文件夹的图片应该要比test文件夹的多一些,我设置的比例一般为4:1,这个可以自己设置,但是train集至少应该比test集大几倍,而且这两个数据集不应该有重叠,test文件夹的图片不能在train文件夹出现,对train文件夹也是如此。
- 这两个数据集里的每一张图片必须要有标签,而且train集和test集分别对应一个标签文件,所以,还得有两个标签文件train.txt、test.txt。标签文件放在与train、test文件夹同目录下,就是为了好看、直观,如下所示:
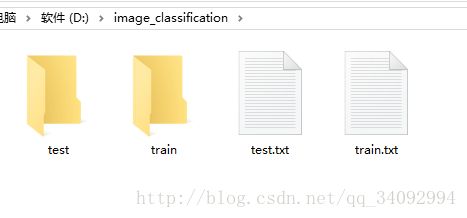
- 标签文件test.txt和train.txt里面的标签定义,也有要求。图片和标签之前以空格分开,必须是空格哦,本人试过tab间隔符,不行!这跟头栽的。每个图片只占一行,空格前面是图片名,图片名必须顶格,空格后面是标签(一般的标准数据集会提供标签,如果没有,那你就手动标注吧,研一都干过这事:),如下图,我的命名:
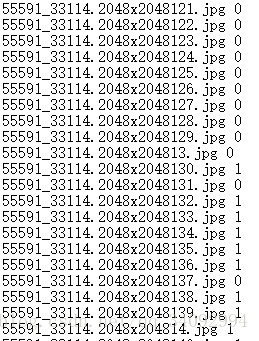
train文件夹里面的图片必须和train.txt里面的图片对应好,test文件夹也一样。
图片和标签文件都弄好后,就可以进行下一步了。(推荐大家使用NotePad编辑标签文件,不要使用window自带的记事本)
转换图片格式
很多人就要问了:caffe不能读取原始的.jpg和.png格式图片吗?答案是可以的,但是这种格式的图片不能作为caffe训练神经网络的输入,输入只能使用固定的格式:lmdb、leveldb(这其实是两种数据库)。于是我们就要转换图片格式。以train文件夹里的图片为例.
- caffe提供转换图片为指定格式的命令,在windows系统下,就是一个.exe文件,名字是convert_imageset.exe,这个文件在编译好的caffe目录下,具体路径为D:\caffe\tools\Release\目录下(这个目录是用我前一篇博客的方法编译出来的,如果不是按照我之前的方法,可能这个exe文件不在该目录下)
- 打开cmd命令行窗口(程序员不会用cmd?赶紧改行,OK?),跳转到D:\caffe\tools\Release\目录下,也就是convert_imageset.exe所在的目录,然后敲下命令
convert_imageset.exe -backend leveldb -resize_height 227 -resize_width 227 D:\image\train\ D:\image\train.txt D:\output_lmdb\train_lmdb上面是将图片转换为leveldb格式,但我常用的是lmdb格式,如果不加上“-backend leveldb”,默认就是转换为lmdb格式。所以命令改为:
convert_imageset.exe -resize_height 227 -resize_width 227 D:\image\train\ D:\image\train.txt D:\output_lmdb\train_lmdb后面的”-resize_height 227 -resize_width 227”是将图片大小重新设置为227x277,这是AlexNet的标准输入。“D:\image\train\”是你train文件夹的位置,“D:\image\train.txt”是你标签文件train.txt,后面的“D:\output_lmdb\train_lmdb”是你转换后的数据存放的位置,记住,output_lmdb需要自己新建,train_lmdb一定不能自己建立!否则会有错。
然后执行完命令,转换数据需要一定的时间。在没有报错的情况下,表明数据转换成功。得到D:\output_lmdb目录下的文件夹:train_lmdb
这个文件夹下会有以下两个文件:data.mdb和lock.mdb,前面一个比较大,就是我们整个图片转换后的数据。
同样的,可以建立test_lmdb:
convert_imageset.exe -resize_height 227 -resize_width 227 D:\image\test\ D:\image\test.txt D:\output_lmdb\test_lmdb
计算均值
在转换完图片数据后,就能够得到lmdb数据,这个就是caffe能够处理的数据。计算均值这一步是AlexNet特有的,要用到程序compute_image_mean.exe,这个程序与convert_imageset.exe在同一目录下。下面以计算train集为例。
同样打开cmd命令行窗口,跳转目录,执行以下命令:
compute_image_mean.exe D:\output_lmdb\train_lmdb D:\image\train_mean.binaryproto其中’D:\output_lmdb\train_lmdb’为train转换后的数据集的位置,’D:\image\train_mean.binaryproto’为你计算后的均值文件的路径和文件名。
该命令也需要执行一段时间,在没有报错的情况下,命令执行成功,然后就会在image目录下出现一个train_mean.binaryproto文件。
同样对test集也可以得到相应的均值文件test_mean.binaryproto。
建立深度网络模型AlexNet
其实现在典型的深度网络模型就那么几种,AlexNet、VGG-16、GoogLeNet、ResNet,AlexNet和GoogLeNet的网络结构文件caffe源码里面都有提供,在models文件夹下。不知道为什么,我编译好的caffe目录下没有models文件夹,更别说网络模型了,所以我就找到了caffe源码里面的models文件夹,里面有以下文件夹:
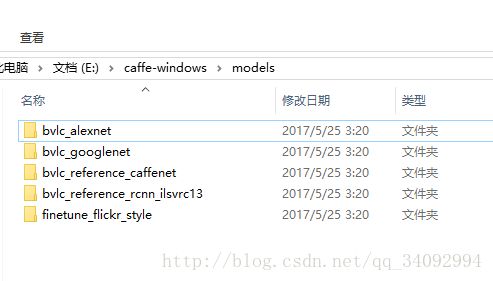
第一个文件夹就是AlexNet模型的,后面的GoogLeNet等等,其他常用的深度模型在caffe的model zoo里面基本都能找到,你要是想自己写,当然也是可以的。bvlc_alexnet文件夹下就会有以下几个文件,我们可以将他们都拷贝到我们的image目录下,除了readme.md文件:
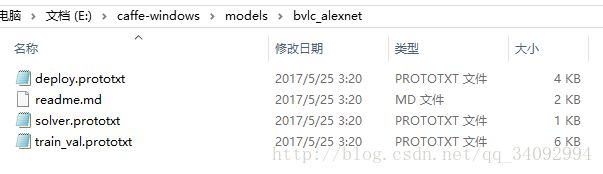
其中train_val.prototxt是网络结构文件,定义的是多层网络(layer),deploy.prototxt也是网络结构文件,但是这个文件是用于分类的,train_val.prototxt文件是用于训练的。
一开始我不明白,不都是同一个网络么,为何要分两个文件,如果仔细看这两个文件的话,你会发现,train_val.txt文件里,有两个数据输入层,一个用于train,里面定义了之前转换数据train_lmdb的路径,一个用于test,里面则定义了test_lmdb的路径,而deploy.prototxt则只有一层数据输入层,且没有数据的路径。实际使用中,使用train_val.prototxt训练时,由于文件里面已经定义train集和test集的路径,所以不需要手动在cmd中输入,而使用deploy.prototxt进行分类时,需要手动在cmd中输入图片的路径。
这两个文件的其他内容基本一致,还有一些细节处不一样,等到后面再说吧。基本上要记住的是我们训练的时候只用到train_val.prototxt和solver.prototxt两个文件就行了。
因为原本的AlexNet是在ImageNet上做1000个分类,所以它网络的输出为1000,在这里我们做的是2分类,所以,需要将输出改为2,因此需要更改train_val.prototxt文件,如下:
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2 //这里的值原本是1000,这里要改为2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}训练深度神经网络模型AlexNet
由于caffe自己定义有AlexNet的网络结构,所以我们不必自己定义,直接用就好了。前面一步只是做了一点小的更改,来适应我们的任务。现在修改train_val.prototxt和solver.prototxt文件来训练模型。
- 先从train_val.prototxt文件开始。之前一步已经改过一处,现在还有文件前面几处需要更改,基本上就是1-40行,如下:
name: "AlexNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN //这层是train集的数据输入层
}
transform_param {
mirror: true
crop_size: 227 //图片的长宽,由于之前已经resize所有图片为227x227,所以这里不需要更改
//将引号里面改为之前train集的均值文件的路径。注意路径分隔符,很容易出错,详情请看下面红字解释。
mean_file: "D:/image/train_mean.binaryproto"
}
data_param {
source: "D:/output_lmdb/train_lmdb" //将引号里面改为前面生成的train_lmdb的路径
batch_size: 128 //每次训练的时候,使用128张train集的图片
backend: LMDB //由于我转换图片为lmdb格式,所以这里不用改,如果你是leveldb,请修改。下面也有一处。
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST //这层是test集的数据输入层
}
transform_param {
mirror: false
crop_size: 227
mean_file: "D:/image/test_mean.binaryproto" //改为test集均值文件的路径
}
data_param {
source: "D:/output_lmdb/test_lmdb" //改为前面生成的test_lmdb的路径
batch_size: 64 每次训练的时候,使用64张test集的图片
backend: LMDB //转换后的数据格式
}注意,因为windows有点坑,本来路径分隔符是 ‘/’,微软为了显示自己与众不同,非要将windows路径分隔符默认为 ‘\’,所以,修改train_val.prototxt和solver.prototxt文件时,一定要额外注意,路径分隔符一定要使用 ‘/’,如上。
本来有几个参数,但是为了快速上手,先不说了,下面再提。
- 接下来修改solver.prototxt文件,这个文件主要包含一些超参数的设置。这个文件没多少行,我就全都贴上来了:
net: "D:/image/train_val.prototxt"//引号里面的是前面修改过的train_val.prototxt文件的位置,同样注意路径分隔符。
test_iter: 1000 //test集迭代的次数
test_interval: 1000 //训练多少次之后,用test集测试一次
base_lr: 0.01 //学习率
lr_policy: "step" //学习的策略,这个有很多讲究的,但一般是默认是step
gamma: 0.1 //与学习率更改有关
stepsize: 100000 //训练多少次之后,修改学习率
display: 20 //训练多少次之后,将训练误差显示在屏幕上(总不可能训练一次就显示,那样会显示多,屏幕会一直刷新)
max_iter: 450000 //最多训练多少次,也就是总的训练次数
momentum: 0.9 //上一次梯度更新的权重
weight_decay: 0.0005 //权重衰减项
snapshot: 10000 //训练多少次,保存一次模型
snapshot_prefix: "D:/image/trained_model/caffe_alexnet_train" //模型保存的位置,trained_model为同目录下的自己新建的文件夹,caffe_alexnet_train不是文件夹,不需要自己新建。
solver_mode: GPU //设置为使用GPU加速训练修改完成后,将train_val.prototxt和solver.prototxt文件都保存在image目录下(当然你也可以放在其他地方,我为了简单、好描述,就都放在一起了),现在,我的image文件夹的文件列表(转换的lmdb数据不在这个目录下)如下:
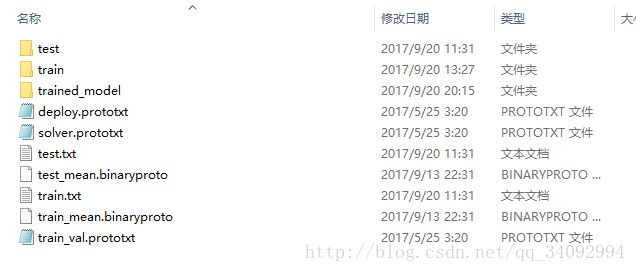
OK,经过一系列的配置,现在差不多都配置妥当了,可以开始训练了!
训练需要用到caffe.exe这个程序,这个程序在D:\caffe\tools\Release\目录下,打开cmd命令行,输入以下命令,回车执行:
//等号后面是之前修改的solver.prototxt的路径
caffe.exe train -solver=D:\image\solver.prototxt回车之后,如果跳出一大串信息,显卡信息、网络结构信息等等,一直刷新你的屏幕,并且不弹出错误信息,出现以下的迭代信息,train losss输出,就说明正在训练网络:
I0920 16:00:27.649086 6560 solver.cpp:397] Test net output #0: accuracy = 0.429297
I0920 16:00:27.650086 6560 solver.cpp:397] Test net output #1: loss = 0.961522 (* 1 = 0.961522 loss)
I0920 16:00:27.839097 6560 solver.cpp:218] Iteration 0 (-1.0869e-012 iter/s, 1.90837s/50 iters), loss = 1.54311
I0920 16:00:27.839097 6560 solver.cpp:237] Train net output #0: loss = 1.54311 (* 1 = 1.54311 loss)
I0920 16:00:27.839097 6560 sgd_solver.cpp:105] Iteration 0, lr = 0.0005
I0920 16:00:32.528365 6560 solver.cpp:218] Iteration 50 (10.6641 iter/s, 4.68861s/50 iters), loss = 5.26144e-007
I0920 16:00:32.528365 6560 solver.cpp:237] Train net output #0: loss = 5.26201e-007 (* 1 = 5.26201e-007 loss)
I0920 16:00:32.528365 6560 sgd_solver.cpp:105] Iteration 50, lr = 0.0005
I0920 16:00:34.219462 1856 data_layer.cpp:73] Restarting data prefetching from start.
I0920 16:00:37.195632 6560 solver.cpp:218] Iteration 100 (10.713 iter/s, 4.66724s/50 iters), loss = -1.21904e-006
I0920 16:00:37.196632 6560 solver.cpp:237] Train net output #0: loss = 0 (* 1 = 0 loss)
I0920 16:00:37.196632 6560 sgd_solver.cpp:105] Iteration 100, lr = 0.0005
I0920 16:00:40.894843 1856 data_layer.cpp:73] Restarting data prefetching from start.
I0920 16:00:41.826897 6560 solver.cpp:218] Iteration 150 (10.7991 iter/s, 4.63002s/50 iters), loss = 0
I0920 16:00:41.826897 6560 solver.cpp:237] Train net output #0: loss = 0 (* 1 = 0 loss)如果你的数据集比较好,solver,prototxt文件中的参数配置合理,会看到train loss会一直在下降。如果输出的东西太多,屏幕会一直刷新,之前显示的数据会被覆盖,这个时候,你可以将cmd输出重定向到一个output.txt文件中,等训练完成,再打开txt文件,查看显示数据。windows中原本只需要在命令行后面加上“>D:\output.txt”就可以重新向,如ping命令:
ping www.baidu.com >D:\output.txt这个时候cmd中就不会显示信息,直接执行完成,无任何输出,D盘下就会自动生成一个output.txt文件,文件的内容就是该ping命令的执行信息。按理来说caffe这样重定向也是可以的,但是上面的方法我试过了,不行!信息还是在cmd中显示,虽然会生成output.txt,但是里面没有任何信息,是空的。经过我的多方考究和多次实验,终于发现,caffe重定向输出需要在caffe命令后面加上“>D:\output.txt 2>&1”,于是上面的训练命令可以改为:
caffe.exe train -solver=D:\image\solver.prototxt >D:\output.txt 2>&1然后,cmd的输出就不显示了,然后显示在output.txt的文件里面了。训练的过程中,如果你发现loss在一段时间内不降反升,而且test的accuracy也比较高的时候,说明模型差不多训练好了,可以提前终止。或者你可以等到它训练次数达到你设定的最大值。这都看你。
利用训练好的AlexNet模型做分类
通过上面步骤的训练,你或许就能够得到一个较好的模型,利用这个模型就可以做分类任务啦。
根据之前修改的solver.prototxt文件,可以找到训练好的模型在trained_model文件夹内:如我的该文件夹内容如下:
文件名中的iter后面的数字“1000”表明迭代了1000次后保存的caffe模型。caffe模型的后缀名为caffemodel,很直观。
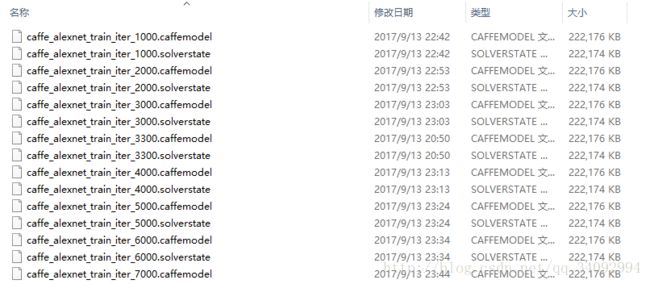
现在我们要挑选一个最优的模型来做分类任务,哪个最优?根据训练过程中的test accuracy来确定,test accuracy较高的就是比较好的模型。比如,我在迭代了10000次后,发现在迭代到6000次的时候,test accuracy是最高的,这个时候就可以使用这个iter_6000的caffemodel来进行分类。
之前有提到过一个deploy.prototxt文件,它是用来做分类的,我也已经放到image目录下,这个文件之前没有改过,是因为训练的时候没有用到,现在是分类任务,所以修改这个文件使用,基本上就是修改以下一处:
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2 //这里的值原本是1000,这里要改为2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}做分类任务需要用到一个label.txt文件,这个文件指明你的分类。比如我之前标注的有“0”和“1”两类标签,这时,label.txt文件的第0行为你的标签为“0”的类标,这里可以设置中文名“无”,也就是标签“0”对应“无”,将标签“1”对应“有”。也就是label.txt第一行为“无”,第二行为“有”,实验中,为了简便,我第一行还是写0,第二行写1,分别对应标签“0”、“1”。
分类任务主要使用classification.exe这个程序,这个程序在D:\caffe\examples\cpp_classification\Release\目录下,同样要用到cmd命令行,跳转到该目录下,输入命令:
classification.exe D:\image\deploy.prototxt D:\trained_model\caffe_alexnet_train_iter_6000.caffemodel D:\image\train_mean.binaryproto D:\image\labels.txt D:\image\1.jpgclassification.exe后面的第一个参数是deploy.prototxt文件名,第二个参数为caffemodel文件名,第三个参数为均值文件名,第四个参数为label.txt文件名,第五个参数为你想要检测的图片的图片名,这张图片可以是train集和test集里面的图片,也可以是其他的图片。以上由于不在同一目录下,需使用绝对路径定位到该文件。
输入命令后回车,如果不报错的话,一般1秒左右就能够输出label.txt定义的标签。
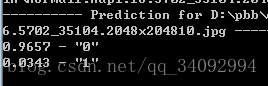
以下是我另一个工程的测试结果:
标签“0”、“1”前面的小数为该类别的置信度,也就是说这张测试的图片有0.9657的可能是“0”类的,只有0.0343的可能是“1”类的,实际这张图片的标记为“0”,结果还不错。
总结
以上简单介绍了一下基本的模型训练流程,至于参数调整等技巧,我还要仔细研究,就先不讲了。现在看来,训练出来的模型分类结果还行。
这一套训练方法是caffe绝无仅有的,不需要写代码,只需要修改几个配置文件,就能够训练自己的网络模型,就算没有写过什么代码,也毫无压力。而其他的深度学习框架都必须要写代码,之前有学过tensorflow,就是用python写代码,没有caffe这般的操作,心中再次佩服作者贾扬清一下,给国人点赞!
但是这种方法也有缺点,会有很多限制,比如网络结构自定义的范围较小,求解方式不能自定义,文件名、标签文件、命令等等都要按照要求来,因为中间用的命令比较多,比较难记忆,像我就根本没有记,用的时候再看,感觉还是写代码自由点。
当然,作为目前流行的深度学习框架,caffe绝不仅仅只能这么用,想写代码也是可以的,caffe由于是开源的,你可以直接使用C++对源码进行更改,也可以通过python和matlab接口进行编程。作为爱编程的你,一定要自己试试才知道其中的妙处!