【知识图谱导论-浙大】第二章:知识图谱的表示
前文:
- 【知识图谱导论-浙大】第一章:知识图谱概论
本节内容的视频讲解如下:
【知识图谱理论】(浙大2022知识图谱课程)第二讲-知识图谱的表示
什么是知识表示
简而言之,知识表示(Knowledge Representation, KR)就是用易于计算机处理的方式来描述人脑知识的方法。KR不是数据格式,不等同于数据结构,也不是编程语言,对于人工智能而言,数据与知识的区别在于KR支持推理。一篇比较久远的论文:R. Davis, H. Shrobe, and P. Szolovits. What is a Knowledge Representation? AI Magazine, 14(1):17-33, 1993,对KR的作用是这样描述的。

说明:
- Role I,事务的名称
- Role II,事务有了名字之后,在此基础上进行一层层抽象,一群学生中,一些人是本科生,一些人是硕士生,一些人是博士生,他们哪些学校的学生,这种对事务的进行抽象,建立万事万物之间的联系,就是本体的构建(ontology);
- Role III,有了万事万物之间的联系,就可以利用这些联系做相关的推理;
- Role IV,这种表示易于计算机处理,例如自然语言就不适合
- Role V,这中表示要易于人类理解,具有可解释
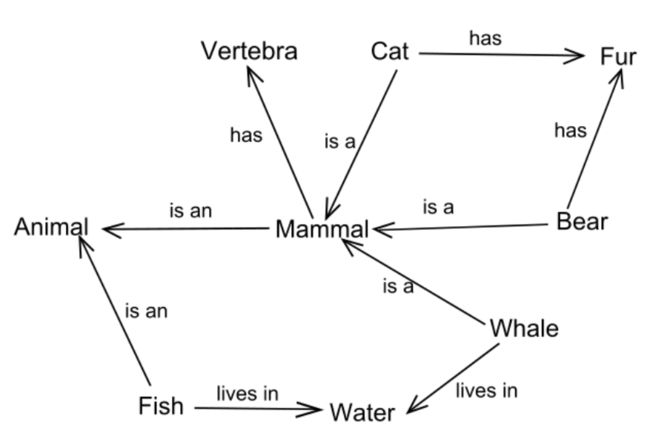
知识的符号表示
传统的知识表示方法就是符号表示。
知识的向量表示
基于连续向量的知识表示。联想到word2vec,一个最大的好处就是易于捕获隐式的知识,可以将推理的过程转换成向量之间的计算,当然引入的弊端是:如何解释?
知识不仅存在与文本中,图片,视频中都会存在知识,使用向量化的处理可以融合图片、视频相关中的知识参与到相关推理中,也就是现在比较流行的多模态。
知识图谱的符号表示
基于图的知识表示与建模
在知识图谱的具体实践中,不同的场景会对知识的建模采用不同表达能力的图表示方法。例如:
- 无向图,建模要求不高,偏向于数据挖掘领域场景
- 有向标记图:1.属性图(property graph) ;2. RDF图模型,3. 更为复杂的关系语言表示(对称关系、自反关系、传递关系等),就需要OWL这种本体描述语言
Property Graph——属性图
具有代表性的图数据库就是Neo4J,在工业界着中也有广泛的使用。
属性图的优点是表达方式灵活,如允许在边上增加属性,利于表示多元关系等。属性图在存储过程充分利用图的结构进行优化,在查询的过程中有较高的优势。
属性图的缺点是缺乏工业标准规范的支持,由于属性图不关注更深层次的语义表达,也不支持符号逻辑推理。
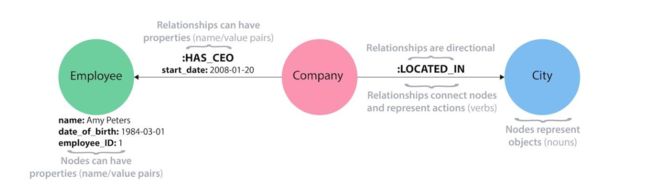
属性图是由顶点(Vertex)、边(Edge)、标签(Label)组成的有向图,其中关系类型中也还有属性(Property)。这里顶点也称为节点(Node),边也称为关系(Relationship)。属性图中,节点和关系都是比较重要的实体,节点上包含属性,属性可以以任何键值形式存在。
关系连接节点,每个关系都有一个方向、一个标签、一个开始节点和结束节点。关系的方向的标签使得属性图具有语义化特征。
关系也可以有属性,即边属性。可通过在关系上增加属性给图算法提供边的元信息,如创建时间。此外还可以通过边属性为边增加权重和特性等其他的额外信息。
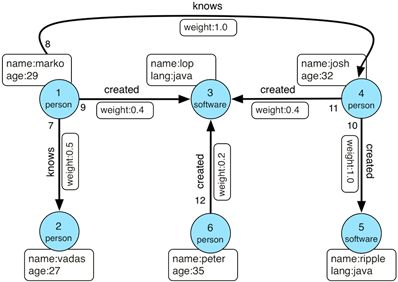
RDF——基于三元组的描述模型
RDF(Resource Description Framework,资源描述框架),由三个元素组成(S,P,O),即(subject(主),predicate(谓),object(宾));如:(subject(浙江大学),predicate(位于),object(杭州))。
一个RDF三元组代表关于客观世界的逻辑描述获客观事实。多个三元组头尾相连就构成了一个有向标记图——RDF图。
RDFS提供了基础的表达构建,用于定义类、属性等Schema术语,如:Class, subClassOf, type, Property, subPropertyOf, Domain, Range等,其中:
- Domain, Range: 用于定义某个关系的头尾节点类型
- subClassOf,subPropertyOf:用于定义类及属性之间的层次关系等
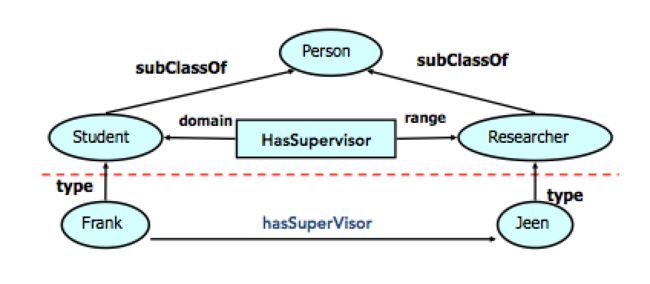
使用RDFS进行简单的符号推理:

OWL: Web Ontologies
rdf的表达能力还是比较有限的。在实际场景中需要定义更为复杂的概念、刻画更为复杂的概念关系,这时就需要用到OWL等本体表达语言。
本体ontology原来是一个哲学术语,在人工智能领域作为知识表示研究的对象。
OWL可以看成RDFS的拓展,增加了更多的语义表达构建。

那么OWL是如何表达的呢?下面了解一下OWL的表达构件:



知识图谱的向量表示
向量化的表示在人工智能的很多领域得到了应用。
词的分布式向量表示
最初的词向量使用的one-hot的表示方法。每个词向量的大小都是词典点的大小,在词的向量中,除了该词对应位置为1以外,其他皆为0。

这种方法显著的缺点是:空间消耗大,数据稀疏,无法表示词的语义等。类似文档的表示方法Bag-of-words:
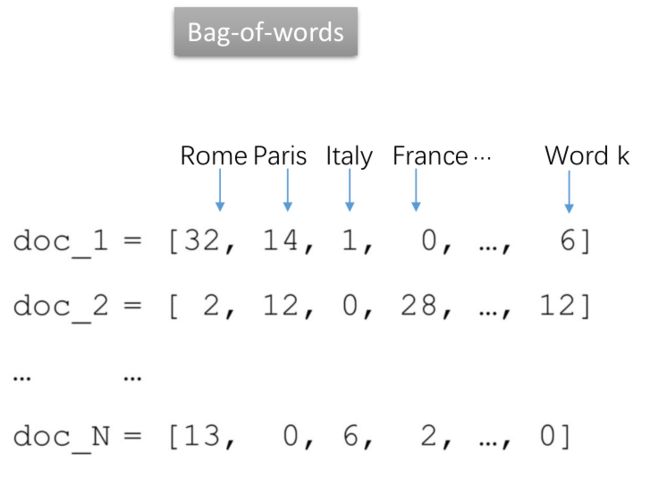
这种向量的大小也都是文档的大小,向量中词语对应位置的值就是词语在文档中出现的次数。
我们都知道词是有语义的,那么词的语义到底是由什么决定的呢?这个问题太复杂了,还涉及语言学。但是大家都认可的是:词的语义是由上下文决定的。人在运用语言时,其实是没有记住每个词的精确语义定义,大脑里也没有什么精确定义的词典,通常是类比一个词出现的上下文来理解这个词的语义。
word embedding(词向量学习模型得到)就是通过利用大料的语料数据,结合词语的上下文内容训练出词语的稠密、低维的向量化表示。例如word2vec的两种训练模式:
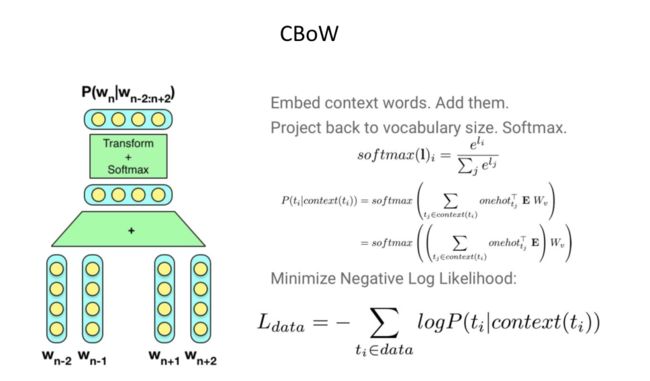
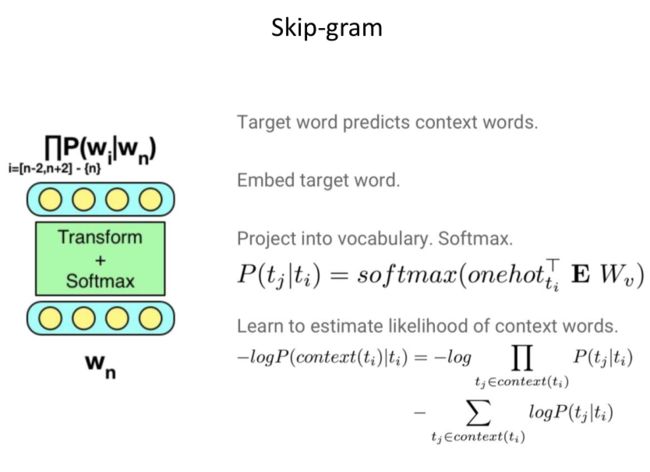
即使当前比较流行的预训练语言模型也都是利用词语的上下文信息来捕捉词的语义内容。
知识图谱嵌入模型:TransE
类似于word Embedding,我们可以利用主谓宾三元组结构来学习知识图谱中实体和关系的向量表示的模型,TransE就是一个比较有效的方式。
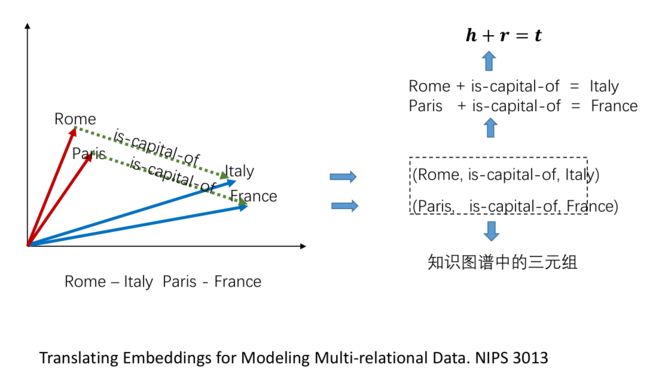
其中:
- h代表head,即关系中subject
- r代表relation,
- t代表tail,即关系中的object
那么h、r、t对应的向量应该满足h + r = t这个关系。评分函数、损失函数定义如下:
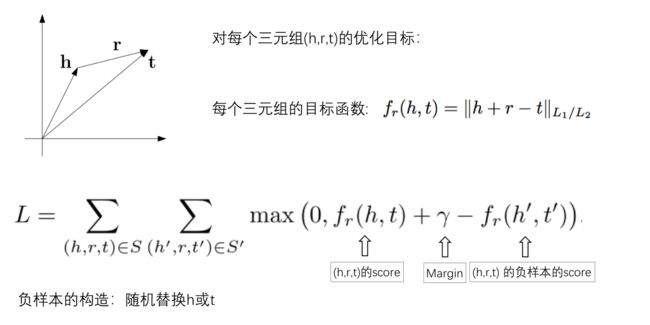
目标就是尽可能地让真实的三元组得分搞,负样本的得分低,然后使用梯度下降算法进行优化。当模型训练收敛之后,h + r 的结果与t应该是比较接近的。
知识图谱嵌入模型:DistMult
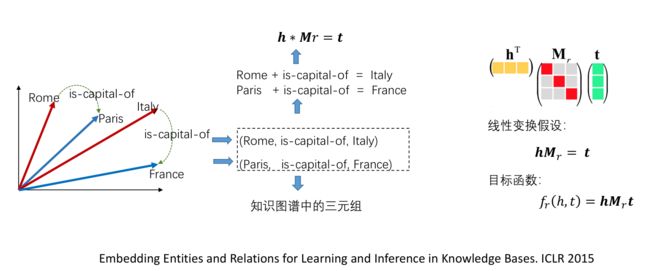
DistMult与TransE主要的区别是,h,r,t三者之间的关系。DistMult则使用的是乘法。
知识图谱嵌入模型:推理问题
嵌入的效果如何,最好的方式是通过推理去测试。即给定三元组中的两个元素,来推理第三个元素。例如:

在显示场景中有很多影响实体关系向量表示好坏的因素。一个比较大的问题是数据稀疏性问题:实体和关系的好坏取决于训练语料中,是否存在足够多的包含他们的三元组,如果某个实体是孤立实体,那么很自然地难以学习到好的效果。