When you write unit tests, it’s hard to find the right test cases. You want to be certain that you covered all the interesting cases, but you could simply not know or forget one of them. For example, if you unit test a function which receives an integer, you might think about testing 0, 1, and 2. But did you think about negative numbers? What about big numbers?
在编写单元测试时,很难找到正确的测试用例。 您想确定自己涵盖了所有有趣的案例,但是您根本就不知道或忘记其中一个案例。 例如,如果您对接收一个整数的函数进行单元测试,您可能会考虑测试0、1和2。但是您是否考虑过负数? 大数字呢?
We were just thinking about a testing strategy for integers. A strategy is a generator of data. The property testing framework hypothesis offers a lot of strategies for many types. You can install it with pip install hypothesis .
我们只是在考虑整数的测试策略。 策略是数据的生成器。 属性测试框架hypothesis为多种类型提供了许多策略 。 您可以使用pip install hypothesis进行pip install hypothesis 。
One thing we can do with those inputs — those tests strategies — is to check if the runtime is acceptable and if the tested function/method does not crash.
我们可以使用这些输入(即测试策略)来做的一件事是检查运行时是否可以接受以及所测试的函数/方法是否不会崩溃。
It would be better if we compare the output of our function against something. A check for equality is likely not possible, so we need to know a property of our function. An invariant which we always expect to hold. We need to base our test on an inherent property of the function.
如果我们将函数的输出与某些东西进行比较,那会更好。 可能无法进行相等性检查,因此我们需要知道函数的属性。 我们一直希望保持不变的不变式。 我们需要基于函数的固有属性进行测试。
To whet your appetite for property-based testing even more:
进一步激发您对基于属性的测试的兴趣:
示例:整数分解 (Example: Integer factorization)
We have a function factorize(n : int) -> List[int] which takes an integer and returns the prime factors:
我们有一个函数factorize(n : int) -> List[int] ,它接受一个整数并返回素数:
An integer n is called a prime number if it is positive and divisible by exactly two numbers: 1 and n.
如果整数n是正数并且可以被两个整数整除(即1和n),则称为素数。
We want that the product of returned integers is the number itself. So this is how we design the functions behavior:
我们希望返回的整数的乘积是数字本身。 这就是我们设计函数行为的方式:
- factorize(0) = [0] — an exception would have been reasonable as well factorize(0)= [0]-异常也将是合理的
- factorize(1) = [1] — strictly speaking, 1 is not a prime. factorize(1)= [1] —严格来说,1不是质数。
- factorize(-1) = [-1] — … and neither is -1 factorize(-1)= [-1] —…都不是-1
- factorize(-n) = [-1] + factorize(n) for n > 1 因式分解(-n)= [-1] +因式分解(n),n> 1
An implementation might look like this:
一个实现可能看起来像这样:
You might feel a bit uneasy about the condition in
您可能会对这种情况感到不安
while i <= int(math.ceil(number ** 0.5)) + 1:so you write a test to check for the important cases:
因此,您编写了一个测试来检查重要情况:
If the test parametrization is unfamiliar, you might want to read up on pytest.mark.parametrize. It’s awesome and those few lines run 8 tests:
如果测试参数不熟悉,则可能需要阅读pytest.mark.parametrize 。 很棒,那几行运行了8个测试:

How would a property-based test look like for factorize?
基于属性的测试对于factorize外观如何?
First, we need to think about the property we want to test. For factorize as we designed it, we know that the product of the returned numbers is equal to the number itself. We can put in any integer, but if the integers become too big, the runtime will be too long. So let’s constrain them in a reasonable range of +/- one million:
首先,我们需要考虑我们要测试的属性。 对于我们设计时的factorize ,我们知道返回数字的乘积等于数字本身。 我们可以输入任何整数,但是如果整数太大,则运行时间将太长。 因此,让我们将它们限制在+/-一百万的合理范围内:
Now we run the tests with pytest :
现在,我们使用pytest运行测试:
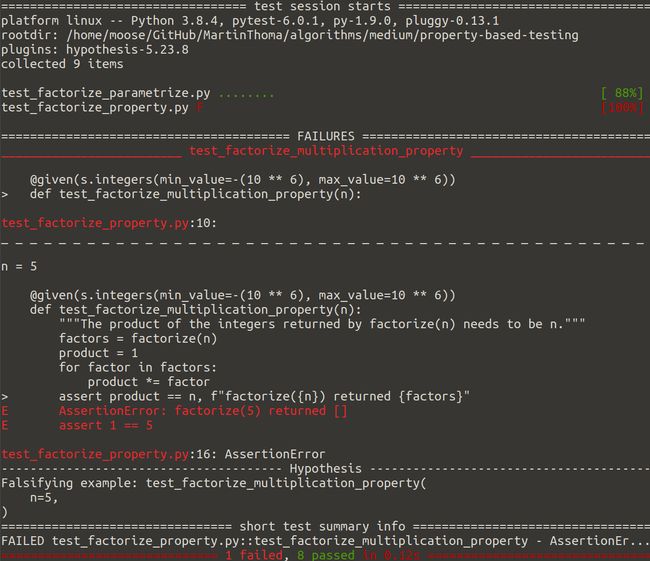
As you can see in the example above, hypothesis discovered that factorize(5) returned an empty list which does not multiply to 5. We can then quickly see that we actually made a mistake for all primes — we need to add the prime number. After adding the following line, the tests run just fine:
如您在上面的示例中看到的, hypothesis发现factorize(5)返回了一个不会乘以factorize(5)的空列表。然后我们可以很快看到我们实际上对所有素数都犯了一个错误-我们需要添加素数。 添加以下行后,测试运行正常:
if number != 1:
factors.append(number)A curious thing to notice in the failed example is that it is the smallest positive integer where it fails. This is no coincidence. The property-testing framework tries to find a simple example which makes the test fail. This process is called shrinking.
在失败的示例中要注意的一个奇怪的事情是它是失败的最小正整数。 这不是巧合。 属性测试框架试图找到一个使测试失败的简单示例。 这个过程称为收缩 。
假设产生了什么? (What did hypothesis generate?)
You can have a look at examples like this:
您可以看一下这样的示例:
from hypothesis import strategies as stst.lists(st.integers()).map(sorted).example()在哪里可以进行基于属性的测试? (Where can I apply property-based testing?)
This kind of pattern works for quite a couple of algorithms where verification is cheap:
这种模式适用于很多验证费用较低的算法:
Arg max: Iterate over the list and ensure that no other element is larger.
Arg max :遍历列表,并确保没有其他元素更大。
- Solving a set of equations: Verify that the solution is actually a solution. 解决一组方程:验证解决方案实际上是一个解决方案。
Constraint satisfaction: Verify that the solution satisfies all constraints.
约束满足 :验证解决方案是否满足所有约束。
All NP complete problems: This is a set of decision problems where it is hard to find an answer, but easy to verify a found answer. An example is the traveling salesman. Given a set of cities which the salesman has to visit, is there a tour he can take which has a length of at most L? Given such a tour, it is easy to verify. Computing such a tour can be hard, though.
所有NP完整问题 :这是一组决策问题,很难找到答案,但是很容易验证找到的答案。 一个例子是旅行推销员。 给定销售员必须访问的一组城市,他是否可以进行游览,游览时间最长为L? 进行这样的游览,很容易验证。 但是,计算这样的行程可能很困难。
Weaker, but still helpful are checks which verify if the returned value is in the set of candidates:
较弱但仍然有用的检查是用来验证返回的值是否在候选集合中:
Greatest common divisor: Ensure that it actually is a divisor.
最大除数 :确保它实际上是一个除数。
Shortest path: Ensure it is a path.
最短路径:确保它是一条路径。
- Sorting and ranking: Ensure exactly the same elements are in the list as before. Maybe you can also test for the sorting/ranking criterion? 排序和排名:确保列表中的元素与以前完全相同。 也许您还可以测试排序/排名标准?
- Filtering: Assert that the relevant data is still there / that the other data was removed. 过滤:确认相关数据仍然存在/其他数据已删除。
生成测试模式 (The Generate to Test Pattern)
Sometimes it is easy to generate a sample to test the function you’re interested in. For the factorization example above, you might have a list of known primes and you multiply random subsets of them. If you write a function that checks if a string is a palindrome, you can easily generate a palindrome first. If you want to check if a text contains a given string, you can add random text around that string and then check.
有时很容易生成一个样本来测试您感兴趣的函数。对于上面的因式分解示例,您可能有一个已知素数的列表,并将它们的随机子集相乘。 如果编写用于检查字符串是否为回文的函数,则可以轻松地首先生成回文。 如果要检查文本是否包含给定的字符串,可以在该字符串周围添加随机文本,然后进行检查。
示例:测试数据结构 (Example: Testing Data Structures)
I’ve implemented an interval data structure which has a method issubset
我已经实现了具有方法issubset的间隔数据结构
字符串验证 (String Verification)
hypothesis can generate some special strings, for example email addresses and IP addresses. This means you can easily check the positive cases for functions which decide if something is an IP address or an email address:
hypothesis可以生成一些特殊的字符串,例如电子邮件地址和IP地址。 这意味着您可以轻松检查功能的肯定情况,这些功能可以确定某些内容是IP地址还是电子邮件地址:
可逆功能 (Invertible functions)

If you have a function and its inverse function, such as encrypt / decrypt or a serialize / deserialize function, you can test them together. The testing strategy should then just give values within the domain.
如果您具有一个函数及其反函数,例如加密/解密或序列化/反序列化函数,则可以一起测试它们。 然后,测试策略应该只给出域内的值。
For example, if we wanted to test b64encode / b64decode , the test would be:
例如,如果我们要测试b64encode / b64decode ,则测试将是:
This test now also documents that those two functions belong together and are meant to be used in this order.
现在,该测试还记录了这两个功能属于同一类,并且应按此顺序使用。
神谕者 (Oracles)

In complexity theory, an oracle is a black box which offers a solution to a problem in instant time. In this context, it is just a second implementation which we trust to be correct. If you have a complex algorithmic problem, you might first want to implement a brute-force solution and then test your faster algorithm against that easier to understand solution. The brute-force algorithm is the oracle.
在复杂性理论中,先知是一个黑匣子,它可以即时解决问题。 在这种情况下,这只是我们相信正确的第二种实现。 如果您遇到复杂的算法问题,则可能首先要实施蛮力解决方案,然后针对该更容易理解的解决方案测试更快的算法。 蛮力算法是预言。
使用类型注释! (Use Type Annotations!)
I love type annotations I’ve you’re not using them, I highly recommend to read about type annotations and gradual typing.
我喜欢类型注释我没有使用它们,我强烈建议您阅读有关类型注释和渐进式打字的信息。
Type annotations are relevant for property-based testing as an annotated class can be used to generate random objects of that class. As a data scientist working on Machine Learning topics, I usually want this in my preprocessing / postprocessing steps, where the objects of interest might be rather complicated. Here is how hypothesis can support and generate those:
类型注释与基于属性的测试有关,因为带注释的类可用于生成该类的随机对象。 作为从事机器学习主题的数据科学家,我通常希望在预处理/后处理步骤中做到这一点,在这些步骤中,感兴趣的对象可能相当复杂。 假设可以如何支持和产生这些假设:
When you develop web applications with complex business logic it should also be helpful.
当您开发具有复杂业务逻辑的Web应用程序时,它也将有所帮助。
游戏名称 (The Name of the Game)
I have seen the same concept being called generative testing and also data-driven testing. The first one is fine; we do generate sample data for our tests.
我见过相同的概念,称为生成测试和数据驱动测试 。 第一个很好; 我们会为测试生成示例数据。
However, I would not call it data-driven testing. We didn’t get real-world data to generate our test cases.
但是,我不会将其称为数据驱动测试 。 我们没有获得真实的数据来生成我们的测试用例。
It’s also interesting to think about it the other way around: If we are now testing properties, what did we test before? Andrea Leopardi calls it example-based or table-based testing.
换个角度来思考也很有趣:如果我们现在正在测试属性,那么我们之前做了什么测试? Andrea Leopardi称之为基于示例或基于表的测试。
Example-based testing is good to cover known corner-cases, wheres property-based testing is good to discover unknown corner-cases.
基于示例的测试很好地覆盖了已知的极端情况,而基于属性的测试很好地发现了未知的极端情况。
摘要 (Summary)
Property-based testing does not replace example-based testing, but complements example-based testing. It sometimes documents properties in a very concise form and helps to find unknown edge cases. It takes more time to execute property-based tests than to execute example-based tests. hypothesis is a good Python framework to write property-based tests.
基于属性的测试不会替代基于示例的测试,而是对基于示例的测试的补充。 有时,它以非常简洁的形式记录属性,并有助于查找未知的极端情况。 与执行基于示例的测试相比,执行基于属性的测试需要更多的时间。 假设是编写基于属性的测试的良好Python框架。
下一步是什么? (What’s next?)
In this series, we already had:
在本系列中,我们已经有:
Part 1: The basics of Unit Testing in Python
第1部分: Python单元测试的基础
Part 2: Patching, Mocks and Dependency Injection
第2部分: 修补,模拟和依赖注入
Part 3: How to test Flask applications with Databases, Templates and Protected Pages
第3部分: 如何使用数据库,模板和受保护的页面测试Flask应用程序
Part 4: tox and nox
第4部分: 有毒和无毒
Part 5: Structuring Unit Tests
第5部分: 结构单元测试
Part 6: CI-Pipelines
第6部分: CI管道
Part 7: Property-based Testing
第7部分: 基于属性的测试
Part 8: Mutation Testing
第8部分: 变异测试
In future articles, I will present:
在以后的文章中,我将介绍:
- Static Code Analysis: Linters, Type Checking, and Code Complexity 静态代码分析:Linter,类型检查和代码复杂度
Let me know if you’re interested in other topics around testing with Python.
让我知道您是否对使用Python测试有关的其他主题感兴趣。
翻译自: https://levelup.gitconnected.com/unit-testing-in-python-property-based-testing-892a741fc119