谱聚类原理(深入浅出)
目录
- 0 总结
- 1. 谱聚类概述
- 2. 谱聚类基础之一:无向权重图
- 3. 谱聚类基础之二:相似矩阵
- 4. 谱聚类基础之三:拉普拉斯矩阵
- 5. 无向图切图
- 6. 谱聚类之切图聚类
-
- 6.1 RatioCut切图
- 6.2 Ncut切图
- 7. 优缺点
- 8. 谱聚类实施上的指导性细节
-
- 8.3 类别的数目
- python 案例
- 参考资料
0 总结
谱聚类算法是一个使用起来简单,但是讲清楚却不是那么容易的算法,它需要你有一定的数学基础。如果你掌握了谱聚类,相信你会对矩阵分析,图论有更深入的理解。同时对降维里的主成分分析也会加深理解。
下面总结下谱聚类算法的优缺点。
谱聚类算法的主要优点有:
1)谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到。
2)由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
谱聚类算法的主要缺点有:
1)如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。
2)聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
1. 谱聚类概述
谱聚类(spectral cluster),这里的谱指的是某个矩阵的特征值,该矩阵是什么,什么得来的,以及在聚类中的作用将会在下文解一一道来。
谱聚类的思想来源于图论,它把待聚类的数据集中的每一个样本看做是图中一个顶点,这些顶点连接在一起,连接的这些边上有权重,权重的大小表示这些样本之间的相似程度。
同一类的顶点它们的相似程度很高,在图论中体现为同一类的顶点中连接它们的边的权重很大,不在同一类的顶点连接它们的边的权重很小。
于是谱聚类的最终目标就是找到一种切割图的方法,使得切割之后的各个子图内的权重很大,子图之间的权重很小。
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。
- 方程作为线性算子,它的所有特征值的全体统称方阵的谱
- 方阵的谱半径为最大的特征值
- 矩阵A的谱半径: ( A T A ) (A^TA) (ATA)(方阵)的最大特征值
- 谱聚类:一般的说,是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据聚类的目的。
它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
要完全理解这个算法的话,需要对图论中的无向图,线性代数和矩阵分析都有一定的了解。
2. 谱聚类基础之一:无向权重图
由于谱聚类是基于图论的,因此我们首先温习下图的概念。
对于一个图 G G G,我们一般用点的集合 V V V 和边的集合 E E E 来描述。即为 G ( V , E ) G(V, E) G(V,E)。其中 V V V 即为我们数据集里面所有的点 ( v 1 , v 2 , . . . , v n ) (v_1,v_2,...,v_n) (v1,v2,...,vn)。对于 V V V 中的任意两个点,可以有边连接,也可以没有边连接。我们定义权重 w i j w_{ij} wij 为点 v i v_i vi 和点 v j v_j vj 之间的权重。由于我们是无向图,所以 w i j = w j i w_{ij}=w_{ji} wij=wji。
对于有边连接的两个点 v i v_i vi 和 v j v_j vj, w i j > 0 w_{ij}>0 wij>0,对于没有边连接的两个点 v i v_i vi 和 v j v_j vj, w i j = 0 w_{ij}=0 wij=0。对于图中的任意一个点 v i v_i vi ,它的度 d i d_i di 定义为和它相连的所有边的权重之和,即
d i = ∑ j = 1 n w i j d_i=\sum_{j=1}^{n}w_{ij} di=j=1∑nwij
利用每个点度的定义,我们可以得到一个 n × n n\times n n×n 的度矩阵 D D D, 它是一个对角矩阵,只有主对角线有值,对应第 i i i 行的第 i i i 个点的度数,定义如下:
D = ( d 1 … … … d 2 … ⋮ ⋮ d n ) \mathbf{D} = \left( \begin{array}{ccc}d_1&\ldots & \ldots \\\\\ldots & d_{2} & \ldots \\\\\vdots & \vdots & d_n\end{array} \right) D= d1…⋮…d2⋮……dn
利用所有点之间的权重值,我们可以得到图的邻接矩阵 W W W,它也是一个 n × n n\times{n} n×n 的矩阵,第 i i i 行的第 j j j 个值对应我们的权重 w i j w_{ij} wij。
除此之外,对于点集 V V V 的的一个子集 A ⊂ V A⊂V A⊂V,我们定义:
∣ A ∣ : = 子集 A 中点的个数 |A|:=子集A中点的个数 ∣A∣:=子集A中点的个数
v o l ( A ) : = ∑ i ∈ A d i vol(A): =\sum_{i∈A}d_i vol(A):=i∈A∑di
3. 谱聚类基础之二:相似矩阵
在上一节我们讲到了邻接矩阵 W W W,它是由任意两点之间的权重值 w i j w_{ij} wij 组成的矩阵。通常我们可以自己输入权重,但是在谱聚类中,我们只有数据点的定义,并没有直接给出这个邻接矩阵,那么怎么得到这个邻接矩阵呢?
基本思想是,距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,不过这仅仅是定性,我们需要定量的权重值。一般来说,我们可以通过样本点距离度量的相似矩阵 S S S 来获得邻接矩阵 W W W。
注意:(相似矩阵 S S S 是 n × n n\times{n} n×n 的,而邻接矩阵 W W W 是 n × m n\times{m} n×m 的,其中 m≤n,且 m 的大小取决于用下面哪种方法)
构建邻接矩阵 W W W 的方法有三类: ϵ ϵ ϵ-邻近法, K K K邻近法和全连接法。
- 对于 ϵ ϵ ϵ-邻近法,它设置了一个距离阈值 ϵ ϵ ϵ,然后用欧式距离 s i j s_{ij} sij 度量任意两点 x i x_i xi 和 x j x_j xj 的距离。即相似矩阵的 s i j = ∣ ∣ x i − x j ∣ ∣ 2 2 s_{ij}=||x_i−x_j||_2^2 sij=∣∣xi−xj∣∣22, 然后根据 s i j s_{ij} sij 和 ϵ ϵ ϵ 的大小关系,来定义邻接矩阵 W W W 如下:
w i j = { 0 s i j > ϵ ϵ s i j ≤ ϵ w_{ij}=\begin{cases}0\;\;s_{ij}>ϵ\\ϵ\;\;s_{ij}≤ϵ\end{cases} wij={0sij>ϵϵsij≤ϵ
从上式可见,两点间的权重要不就是 ϵ ϵ ϵ, 要不就是 0 0 0,没有其他的信息了。距离远近度量很不精确,因此在实际应用中,我们很少使用 ϵ ϵ ϵ-邻近法。
- 第二种定义邻接矩阵 W W W 的方法是 K K K 邻近法,利用 KNN 算法遍历所有的样本点,取每个样本最近的 k k k 个点作为近邻,只有和样本距离最近的 k k k 个点之间的 w i j > 0 w_{ij}>0 wij>0。但是这种方法会造成重构之后的邻接矩阵 W W W 非对称,我们后面的算法需要对称邻接矩阵。为了解决这种问题,一般采取下面两种方法之一:
-
第一种 K 邻近法是只要一个点在另一个点的 K 近邻中,则保留 s i j s_{ij} sij
w i j = w j i = { 0 x i ∉ K N N ( x j ) a n d x j ∉ K N N ( x i ) e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 2 2 σ 2 ) x i ∈ K N N ( x j ) a n d x j ∈ K N N ( x i ) w_{ij}=w_{ji}=\begin{cases}0\;\;x_i∉KNN(x_j)\ and\ x_j∉KNN(x_i)\\exp(-\frac{||x_i−x_j||_2^2}{2σ^2})\;\;x_i∈KNN(x_j)\ and\ x_j∈KNN(x_i)\end{cases} wij=wji={0xi∈/KNN(xj) and xj∈/KNN(xi)exp(−2σ2∣∣xi−xj∣∣22)xi∈KNN(xj) and xj∈KNN(xi) -
第二种 K K K邻近法是必须两个点互为K近邻中,才能保留 s i j s_{ij} sij
w i j = w j i = { 0 x i ∉ K N N ( x j ) o r x j ∉ K N N ( x i ) e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 2 2 σ 2 ) x i ∈ K N N ( x j ) a n d x j ∈ K N N ( x i ) w_{ij}=w_{ji}=\begin{cases}0\;\;x_i∉KNN(x_j)\ or\ x_j∉KNN(x_i)\\exp(-\frac{||x_i−x_j||_2^2}{2σ^2})\;\;x_i∈KNN(x_j)\ and\ x_j∈KNN(x_i)\end{cases} wij=wji={0xi∈/KNN(xj) or xj∈/KNN(xi)exp(−2σ2∣∣xi−xj∣∣22)xi∈KNN(xj) and xj∈KNN(xi)
- 第三种定义邻接矩阵 W W W的方法是全连接法,相比前两种方法,第三种方法所有的点之间的权重值都大于 0 0 0,因此称之为全连接法。可以选择不同的核函数来定义边权重,常用的有多项式核函数,高斯核函数和 S i g m o i d Sigmoid Sigmoid核函数。最常用的是高斯核函数 RBF,此时相似矩阵和邻接矩阵相同:
w i j = s i j = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 2 2 σ 2 ) w_{ij}=s_{ij}=exp(-\frac{||x_i−x_j||_2^2}{2σ^2}) wij=sij=exp(−2σ2∣∣xi−xj∣∣22)
其中, σ \sigma σ 的选取对结果有一定的影响,其表示为数据分布的分散程度。
引用:在了解三种构图方式后,还需要注意一些细节,对于第一二构图,一般是重构基于欧式距离的,而第三种方式,则是基于高斯距离的,注意到高斯距离的计算蕴含了这样一个情况:对于 ∣ ∣ x i − x j ∣ ∣ 2 ||x_i−x_j||^2 ∣∣xi−xj∣∣2 比较大的样本点,其得到的高斯距离反而是比较小的,而这也正是 S S S 可以直接作为 W W W 的原因,主要是为了将距离近的点的边赋予高权重。
在实际的应用中,使用第三种全连接法来建立邻接矩阵是最普遍的,而在全连接法中使用高斯径向核 RBF是最普遍的。
4. 谱聚类基础之三:拉普拉斯矩阵
单独把拉普拉斯矩阵(Graph Laplacians)拿出来介绍是因为后面的算法和这个矩阵的性质息息相关。它的定义很简单,拉普拉斯矩阵 L=D−W。D 即为我们第二节讲的度矩阵,它是一个对角矩阵。而W即为我们第二节讲的邻接矩阵,它可以由我们第三节的方法构建出。
拉普拉斯矩阵有一些很好的性质如下:
1)拉普拉斯矩阵是对称矩阵,这可以由 D 和 W 都是对称矩阵而得。
2)由于拉普拉斯矩阵是对称矩阵,则它的所有的特征值都是实数。
3)对于任意的向量 f f f,我们有
f T L f = 1 2 ∑ i , j n w i j ( f i − f j ) 2 f^TLf=\frac{1}{2}\sum_{i, j}^{n}w_{ij}(f_i-f_j)^2 fTLf=21i,j∑nwij(fi−fj)2
(证明过程)这个利用拉普拉斯矩阵的定义很容易得到如下:
f T L f = f T D f − f T W f = ∑ i = 1 n d i f i 2 − ∑ i , j = 1 n w i j f i f j = f^TLf=f^TDf-f^TWf=\sum_{i=1}^{n}d_if_i^2-\sum_{i, j=1}^{n}w_{ij}f_if_j= fTLf=fTDf−fTWf=i=1∑ndifi2−i,j=1∑nwijfifj=
( 1 2 3 ) ∙ ( 1 1 0 0 1 1 1 1 1 ) ∙ ( 1 2 3 ) [ 例子 ] \begin{pmatrix} 1 & 2 & 3\end{pmatrix}\bullet \begin{pmatrix}1 & 1& 0\\ 0& 1& 1\\ 1& 1& 1\\\end{pmatrix}\bullet\begin{pmatrix}1 \\2 \\3\end{pmatrix}\ \ \ \ \ \ [例子] (123)∙ 101111011 ∙ 123 [例子]
上式中, w i j w_{ij} wij 中,只是给了 j = 1 , 2 , … , n j=1,2,…,n j=1,2,…,n,而不管 i i i,也就是,一列一列的计算,如上式例子所示,左侧 f T f^T fT乘以矩阵第一列,再乘以 f f f,得到一个值,三列都×完,得到三个值,然后求和。
= 1 2 ( ∑ i = 1 n d i f i 2 − 2 ∑ i , j = 1 n w i j f i f j + ∑ i = 1 n d i f i 2 ) = 1 2 ∑ i , j n w i j ( f i − f j ) 2 =\frac{1}{2}\left({\sum_{i=1}^{n}d_if_i^2-2\sum_{i, j=1}^{n}w_{ij}f_if_j+\sum_{i=1}^{n}d_if_i^2}\right)=\frac{1}{2}\sum_{i, j}^{n}w_{ij}(f_i-f_j)^2 =21(i=1∑ndifi2−2i,j=1∑nwijfifj+i=1∑ndifi2)=21i,j∑nwij(fi−fj)2
4) 拉普拉斯矩阵是半正定的,且对应的 n n n 个实数特征值都大于等于 0 0 0,即 0 = λ 1 ≤ λ 2 ≤ . . . ≤ λ n 0=λ_1≤λ_2≤...≤λ_n 0=λ1≤λ2≤...≤λn, 且最小的特征值为 0,这个由性质3 很容易得出。
5. 无向图切图
谱聚类的目的是依据相似度矩阵把数据点聚为不同的集合,使得同一聚类的数据点尽量相似,不同类间数据尽量不相似。对于给定的数据集与相似度图,我们可以把这个问题用图论语言进行阐述:
我们想要找到一个图的割,这个割将图分为了若干子图,并且满足子图之间的连接权重非常低,同时每一个子图内的连接权重非常高。
我们采用最小割问题的研究工具来阐述谱聚类算法与子图分割算法的联系。给定权值矩阵为的相似图,最直接的构建图割的策略是解一个最小割问题。
对于无向图 G G G 的切图,我们的目标是将图 G(V,E) 切成相互没有连接的 k k k 个子图,每个子图点的集合为: A 1 , A 2 , . . A k A_1,A_2,..A_k A1,A2,..Ak,它们满足 A i ∩ A j = ∅ A_i∩A_j=∅ Ai∩Aj=∅,且 A 1 ∪ A 2 ∪ . . . ∪ A k = V A_1∪A_2∪...∪A_k=V A1∪A2∪...∪Ak=V.
对于任意两个子图点的集合 A , B ⊂ V , A ∩ B = ∅ A,B⊂V, A∩B=∅ A,B⊂V,A∩B=∅, 我们定义 A 和 B 之间的切图权重为:
W ( A , B ) = ∑ i ∈ A , j ∈ B w i j W(A,B)=∑_{i∈A,j∈B}w_{ij} W(A,B)=i∈A,j∈B∑wij
那么对于我们 k k k 个子图点的集合: A 1 , A 2 , . . A k A_1,A_2,..A_k A1,A2,..Ak( k k k代表聚类结果含多少类,由我们设定),我们定义切图损失函数 cut 为:
c u t ( A 1 , A 2 , . . . A k ) = 1 2 ∑ i = 1 k W ( A i , A i ‾ ) cut(A_1,A_2,...A_k)=\frac{1}{2}∑_{i=1}^kW(A_i,\overline{A_i}) cut(A1,A2,...Ak)=21i=1∑kW(Ai,Ai)
我们用系数 1 2 \frac{1}{2} 21 以保证每条边只计算一次。其中 A i ‾ \overline{A_i} Ai 为 A i A_i Ai 的补集,意为除 A i A_i Ai 子集外其他 V V V 的子集的并集。
对于 k = 2 k=2 k=2,这个图割算法是非常容易求解的(解一个最大流问题),但是在实际使用中,该损失函数一般不会给出一个令人满意的分割,因为这个最小割的解往往会把整个数据集分为一团和一个非常非常孤立的孤立点(如下图所示),这显然不是我们想要的聚类结果。
那么如何切图可以让子图内的点权重和高,子图间的点权重和低呢?一个自然的想法就是最小化 c u t ( A 1 , A 2 , . . . A k ) cut(A_1,A_2,...A_k) cut(A1,A2,...Ak) , 但是可以发现,这种极小化的切图存在问题,如下图:
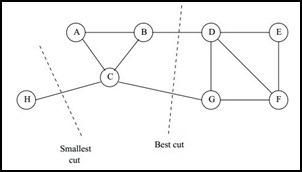
我们选择一个权重最小的边缘的点,比如 C 和 H 之间进行cut,这样可以最小化 c u t ( A 1 , A 2 , . . . A k ) cut(A_1,A_2,...A_k) cut(A1,A2,...Ak), 但是却不是最优的切图,如何避免这种切图,并且找到类似图中 “Best Cut” 这样的最优切图呢?我们下一节就来看看谱聚类使用的切图方法。
一个改进的方案是对划分加以约束,使得 A 1 , A 2 , . . . , A k A_1,A_2,...,A_k A1,A2,...,Ak 都相对来说比较"大"。基于该目的,两个常用的损失函数是 RatioCut 和 NCut,它们的定义如下:
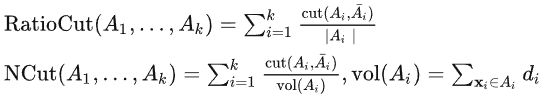
从直观上理解,RatioCut 直接用子集元素个数来衡量集合大小,而 NCut 则用了子集内所有元素的度来衡量大小,这两个目标函数都是为了类别能够尽量平衡。
但是加权图割就是一个 NP-hard 问题了,而整个谱聚类的过程可以归结为解决加权图割,同时松弛的 RatioCut 算法则诱导出非正则化的谱聚类。
6. 谱聚类之切图聚类
为了避免最小切图导致的切图效果不佳,我们需要对每个子图的规模做出限定,一般来说,有两种切图方式,第一种是RatioCut,第二种是Ncut。下面我们分别加以介绍。
目的是找到一条权重最小,又能平衡切出子图大小的边。
6.1 RatioCut切图
RatioCut切图为了避免第五节的最小切图,对每个切图,不光考虑最小化 c u t ( A 1 , A 2 , . . . A k ) cut(A_1,A_2,...A_k) cut(A1,A2,...Ak),它还同时考虑最大化每个子图点的个数,即:
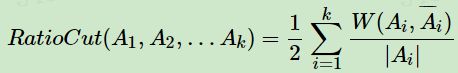
那么怎么最小化这个 RatioCut 函数呢?牛人们发现,RatioCut 函数可以通过如下方式表示。
我们引入 { A 1 , A 2 , ⋯ , A k } {\{A_1,A_2,\cdots ,A_k\}} {A1,A2,⋯,Ak}的指示向量 h j ∈ { h 1 , h 2 , . . h k } , j = 1 , 2 , . . . k h_j∈\{{h_1,h_2,..h_k\}} , j=1,2,...k hj∈{h1,h2,..hk},j=1,2,...k,对于任意一个向量 h j h_j hj, 它是一个 n n n 维向量(n为样本数), v i v_i vi表示第 i i i 个样本,我们定义 h i j h_{ij} hij为:
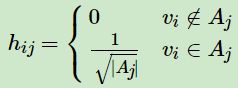
通俗理解就是,每个子集 A j A_j Aj 对应一个指示向量 h j h_j hj,而每个 h j h_j hj 里有 n n n 个元素,分别代表 n n n 个样本点的指示结果,如果在原始数据中第 i i i 个样本被分割到子集 A j A_j Aj 里,则 h j h_j hj 的第 i i i 个元素为 1 ∣ A j ∣ \frac{1}{\sqrt{\left| A_j\right|}} ∣Aj∣1,否则为 0。
∣ A j ∣ : = 子集 A j 中点的个数 |A_j|:=子集A_j中点的个数 ∣Aj∣:=子集Aj中点的个数
矩阵 h i j h_{ij} hij 即 H H H 可以理解为 n n n 行 j j j 列的矩阵,其中 n n n 代表样本个数, j j j 代表子图个数(我理解为降维后的维度数)。
补充:对指示向量的解释
y i ∈ { 0 , 1 } n y_i\in{\{{0, 1}\}^n} yi∈{0,1}n
∑ j = 1 n y i j = 1 \sum{^n_{j=1}y_{ij}=1} ∑j=1nyij=1
这个的意思是, 这个指示向量的维度为 n n n,而这个指示向量的每个元素只能是 0 或者 1,同时一个指示向量中只能有一个元素为 1。那么实际上 y i j = 1 y_{ij}=1 yij=1 的含义就是第 i i i 个样本属于第 j j j 个类别,其中
1 ≤ i ≤ n 1≤i≤n 1≤i≤n
1 ≤ j ≤ k ( k 代表子图个数) 1≤j≤k\ \ \ \ \ (k代表子图个数) 1≤j≤k (k代表子图个数)
那么我们对于 h i T L h i h^T_iLh_i hiTLhi,有:
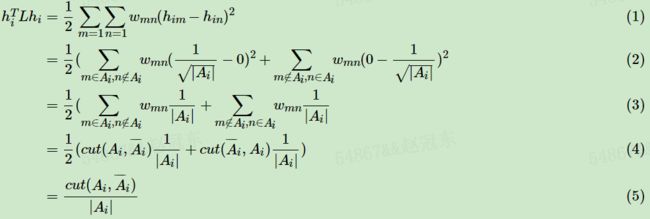
分解如下:
第一步到第二步,将指示变量 h i , m h_{i,m} hi,m, h i , n h_{i,n} hi,n 对应 A i A_i Ai 的元素分别代入;
第三,四,五步,分别做简单运算,以及将 ∑ m ∈ A i , n ∈ A i ‾ w m , n ∑_{m∈A_i,n∈\overline{A_i}}w_{m,n} ∑m∈Ai,n∈Aiwm,n替换为 c u t ( A i , A i ‾ ) cut(A_i,\overline{A_i}) cut(Ai,Ai);
可以看到,通过引入指示变量 h h h,将 L L L 矩阵 放缩到与 Ratiocut 等价,这无疑是在谱聚类中划时代的一举。
上述第(1)式用了上面第四节的拉普拉斯矩阵的性质3. 第二式用到了指示向量的定义。可以看出,对于某一个子图 i i i,它的RatioCut 对应于 h i T L h i h^T_iLh_i hiTLhi ,那么我们的 k k k 个子图呢?
为了更进一步考虑进所有的指示向量,令 H = { h 1 , h 2 , . . h k } H=\{{h_1,h_2,..h_k\}} H={h1,h2,..hk},其中 h i h_i hi 按列排列,由 h i h_i hi 的定义知每个 h i h_i hi 之间都是相互正交,即 h i ∗ h j = 0 , i ≠ j h_i∗h_j=0,i≠j hi∗hj=0,i=j,且有 h i ∗ h i = 1 h_i∗h_i=1 hi∗hi=1。
对应的 RatioCut 函数表达式为:

其中 t r ( H T L H ) tr(H^TLH) tr(HTLH) 为矩阵的迹。也就是说,我们的 RatioCut 切图,实际上就是最小化我们的 t r ( H T L H ) tr(H^TLH) tr(HTLH)。注意到 H T H = I H^TH=I HTH=I, 则我们的切图优化目标为:
![]()
将之前切图的思路以一种严谨的数学表达表示出来,对于上面极小化问题,由于 L L L 矩阵是容易得到的,所以目标是求满足条件的 H H H 矩阵,以使得 t r ( H T L H ) tr(H^TLH) tr(HTLH) 最小。
注意到一点,要求条件 H T H = I H^TH=I HTH=I 下的 H n × k H_{n\times k} Hn×k,首先是求得组成 H H H (按列排列)的每个 h i h_i hi(列),而每个 h i h_i hi 都是 Nx1 的向量,且向量中每个值都是二值分布(即取值0或者 1 ∣ A j ∣ \frac{1}{\sqrt{\left| A_j\right|}} ∣Aj∣1),那么对于每个元素,有 2 种选择,则 h i h_i hi中包含 n 个元素,则 h i h_i hi 就有 2 n 2^n 2n 种情况,对于整个 H n × k H_{n\times k} Hn×k 矩阵,则有 k ⋅ 2 n k\cdot{2^n} k⋅2n 种情况,对于 n 很大的数据,因此找到满足上面优化目标的 H H H 无疑是灾难性的NP-hard问题,显然我们不可能遍历所有的情况来求解,那么问题是不是没有解?
答案自然是否定的,虽然我们没办法求出精确的 ,但是我们可以用另外一种方法近似代替 h i h_i hi,当 k=2 的时候,可以用 L L L 的倒数第二小(动词:从后面数第二个)的特征向量(因为最小的特征向量为 1,其对应的特征值为0,不适合用来求解)来代替 ,关于具体为什么可以这么做,可以参考Rayleigh-Ritz method(对应论文为:A short theory of the Rayleigh-Ritz method),因为涉及泛函变分,这里就不多说了。
注意观察 t r ( H T L H ) tr(H^TLH) tr(HTLH)中每一个优化子目标 h i T L h i h^T_iLh_i hiTLhi ,其中 h 是单位正交基, L L L 为对称矩阵,此时 h i T L h i h^T_iLh_i hiTLhi 的最大值为 L L L 的最大特征值,最小值是 L L L 的最小特征值。如果你对主成分分析 PCA 很熟悉的话,这里很好理解。在 PCA 中,我们的目标是找到协方差矩阵(对应此处的拉普拉斯矩阵 L L L )的最大的特征值,而在我们的谱聚类中,我们的目标是找到目标的最小的特征值,得到对应的特征向量,此时对应二分切图效果最佳。也就是说,我们这里要用到维度规约的思想来近似去解决这个 NP 难的问题。
对于 h i T L h i h^T_iLh_i hiTLhi,我们的目标是找到最小的 L L L 的特征值,而对于 t r ( H T L H ) = ∑ i = 1 k h i T L h i tr(H^TLH)=∑_{i=1}^kh^T_iLh_i tr(HTLH)=∑i=1khiTLhi,则我们的目标就是找到 k k k 个最小的特征值,一般来说, k k k 远远小于 n n n,也就是说,此时我们进行了维度规约,将维度从 n n n 降到了 k k k,从而近似可以解决这个 NP 难的问题。
通过找到 L L L 的最小的 k k k 个特征值,可以得到对应的 k k k 个特征向量,这 k k k 个特征向量组成一个 n × k n\times{k} n×k 维度的矩阵,即为我们的 H H H。一般需要对 H H H 矩阵按行做标准化,即
那么当 k k k 取任意数字时,只需取 L L L 矩阵对应的最小那 k k k 个(毕竟倒数第二小只有 1 1 1 个),即可组成目标 H H H,最后,对 H H H 做标准化处理,如下:

由于我们在使用维度规约的时候损失了少量信息,导致得到的优化后的指示向量 h h h 对应的H现在不能完全指示各样本的归属,因此一般在得到 n × k n\times{k} n×k 维度的矩阵 H H H 后还需要对每一行进行一次传统的聚类,比如使用 K-Means 聚类。
现在 H 矩阵也完成了,剩下的就是对样本聚类了,要明白我们的目标不是求 t r ( H T L H ) tr(H^TLH) tr(HTLH) 的最小值是多少,而是求能最小化 t r ( H T L H ) tr(H^TLH) tr(HTLH) 的 H,所以聚类的时候,分别对 H 中的行进行聚类即可,通常是kmeans,也可以是GMM,具体看效果而定。
至于为什么是对 H的 行进行聚类,有两点原因:
1.注意到 H H H 除了是能满足极小化条件的解,还是 L L L 的特征向量,也可以理解为 W W W 的特征向量,而 W W W 则是我们构造出>的图,对该图的特征向量做聚类,一方面聚类时不会丢失原图太多信息,另一方面是降维加快计算速度,而且容易发现图背后的>模式。
2.由于之前定义的指示向量 h i h_i hi 是二值分布(取值0或者 1 ∣ A j ∣ \frac{1}{\sqrt{\left| A_j\right|}} ∣Aj∣1),但是由于 NP-hard 问题的存在导致 h i h_i hi 无法显式求解,只能利用特征向量进行近似逼近,但是特征向量是取任意值,结果是我们对 h i h_i hi 的二值分布限制进行放松,但这样一来 h i h_i hi 如何指示各样本的所属情况?
所以 kmeans 就登场了,利用 kmeans 对该向量进行聚类,如果是 k=2 的情况,那么 kmeans 结果就与之前二值分布的想法相同了,所以kmeans的意义在此, k k k 等于任意数值的情况做进一步类推即可。
以上是Ratiocut的内容。
6.2 Ncut切图
Ncut 切图和 RatioCut 切图很类似,但是把 Ratiocut 的分母 ∣ A i ∣ |A_i| ∣Ai∣ 换成 v o l ( A i ) vol(A_i) vol(Ai). 由于子图样本的个数多并不一定权重就大,我们切图时基于权重也更合我们的目标,因此一般来说 Ncut 切图优于 RatioCut 切图。
v o l ( A i ) : = ∑ i ∈ A i d i vol(A_i): =\sum_{i∈A_i}d_i vol(Ai):=i∈Ai∑di
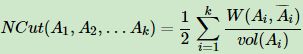
,对应的,Ncut 切图对指示向量 h 做了改进。注意到 RatioCut 切图的指示向量使用的是 1 ∣ A j ∣ \frac{1}{\sqrt{\left| A_j\right|}} ∣Aj∣1 标示样本归属,而Ncut切图使用了子图权重 1 v o l ( ∣ A j ∣ ) \frac{1}{\sqrt{ vol(\left| A_j\right|)}} vol(∣Aj∣)1来标示指示向量 h,定义如下:
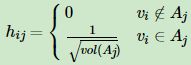
那么我们对于 h i T L h i h^T_iLh_i hiTLhi ,有:
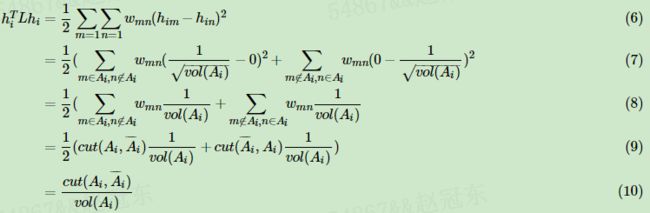
推导方式和 RatioCut 完全一致。也就是说,我们的优化目标仍然是

但是此时我们的 H T H ≠ I H^TH≠I HTH=I,而是 H T D H = I H^TDH=I HTDH=I。推导如下:
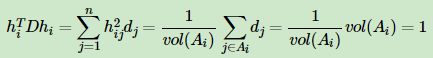
也就是说,此时我们的优化目标最终为:
![]()
此时我们的H中的指示向量 h 并不是标准正交基,所以在RatioCut里面的降维思想不能直接用。怎么办呢?其实只需要将指示向量矩阵H做一个小小的转化即可。
我们令 H = D − 1 / 2 F H=D^{−1/2}F H=D−1/2F, 则: H T L H = F T D − 1 / 2 L D − 1 / 2 F H^TLH=F^TD^{−1/2}LD^{−1/2}F HTLH=FTD−1/2LD−1/2F, H T D H = F T F = I H^TDH=F^TF=I HTDH=FTF=I,也就是说优化目标变成了:
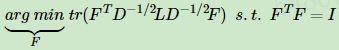
可以发现这个式子和RatioCut基本一致,只是中间的L变成了 D − 1 / 2 L D − 1 / 2 D^{−1/2}LD^{−1/2} D−1/2LD−1/2。这样我们就可以继续按照RatioCut的思想,求出 D − 1 / 2 L D − 1 / 2 D^{−1/2}LD^{−1/2} D−1/2LD−1/2的最小的前 k 个特征值,然后求出对应的特征向量,并标准化,得到最后的特征矩阵 F,最后对 F 进行一次传统的聚类(比如K-Means)即可。
一般来说, D − 1 / 2 L D − 1 / 2 D^{−1/2}LD^{−1/2} D−1/2LD−1/2 相当于对拉普拉斯矩阵L做了一次标准化,即 L i j d i ∗ d j \frac{L_{ij}}{\sqrt{d_i*d_j}} di∗djLij 。
7. 优缺点
-
优点
用谱聚类算法相对于传统的k-means算法会更高效,聚类的效果会均匀。谱聚类需要先将样本通过某种标准计算出样本间的相似度构建成相似度矩阵,也就是邻接矩阵。然后计算拉普拉斯矩阵,求出拉普拉斯矩阵对应的前k个最小的特征值,得到对应的特征向量组成的矩阵V后,用V来给样本在低维度上进行聚类,相比k-means直接对样本聚类会更快。
8. 谱聚类实施上的指导性细节
8.3 类别的数目
选择聚类的个数 k k k 对于所有的聚类算法而言都是非常重要的问题。基于分布模型的聚类问题已经有了非常自洽的聚类个数选取理论,这些理论大都是基于数据集的 l o g log log 似然,然后可以用频率学派或者是贝叶斯理论来进一步解释。
但是如果我们对于模型并没有什么假设的话,我们可以用很多方式来选取聚类个数。这些方法有 ad-hoc 测度(集合内的相似度与集合间相似度的比值)、信息论、间隙统计以及稳定性方法等。这些方法当然也可以直接用于谱聚类,但是正如我们上面所分析的那样,特征根间距方法是专门为谱聚类设计的有效分类方法,而特征根方法可以在 3 3 3 种不同的图拉普拉斯矩阵中使用。
这里一个很简单的实现方法就是选择聚类个数 k k k 以满足是非常小的,同时是相对来说比较大的.这个方法有很多理由,矩阵扰动理论是一个很好的解释,即在有且仅有 k k k 个连通分支的理想情况下特征根 0 0 0 的幂次为 k k k,而此时.其它的解释可以由谱图解释给出,此时图的许多几何变体可以在图拉普拉斯矩阵的第一特征值的帮助下表达或限制。从直觉上谱聚类对图进行割的尺寸与一开始的几个特征值的大小息息相关。
python 案例
from sklearn.cluster import SpectralClustering
import numpy as np
X = np.array([[1, 1], [2, 1], [1, 0],
[4, 7], [3, 5], [3, 6]])
clustering = SpectralClustering(n_clusters=2,
assign_labels='discretize',
random_state=0).fit(X)
clustering.labels_
属性 Attribute
>>> clustering.labels_
Out[2]: array([1, 1, 1, 0, 0, 0], dtype=int64)
>>> clustering
Out[3]: SpectralClustering(assign_labels='discretize', n_clusters=2, random_state=0)
>>> clustering.affinity
Out[3]: 'rbf'
>>> clustering.affinity_matrix_
Out[4]:
array([[1.00000000e+00, 3.67879441e-01, 3.67879441e-01, 2.86251858e-20,
2.06115362e-09, 2.54366565e-13],
[3.67879441e-01, 1.00000000e+00, 1.35335283e-01, 4.24835426e-18,
4.13993772e-08, 5.10908903e-12],
[3.67879441e-01, 1.35335283e-01, 1.00000000e+00, 6.47023493e-26,
2.54366565e-13, 4.24835426e-18],
[2.86251858e-20, 4.24835426e-18, 6.47023493e-26, 1.00000000e+00,
6.73794700e-03, 1.35335283e-01],
[2.06115362e-09, 4.13993772e-08, 2.54366565e-13, 6.73794700e-03,
1.00000000e+00, 3.67879441e-01],
[2.54366565e-13, 5.10908903e-12, 4.24835426e-18, 1.35335283e-01,
3.67879441e-01, 1.00000000e+00]]) #6个元素形成的 6*6的相似矩阵
>>> clustering.n_features_in_
Out[6]: 2 # 拟合期间看到的特征数。
>>> clustering.assign_labels
Out[8]: 'discretize'
参考资料
[1] 谱聚类(spectral clustering)原理总结 2016.12
[2] sklearn学习谱聚类 2022.7
[3] https://blog.csdn.net/baimafujinji/article/details/74169484 ; 2017.7
[4] https://zhuanlan.zhihu.com/p/23902409 ; 2016.11
[5] 一个谱聚类的教程 2021.11
[6] 谱聚类算法入门教程(二)—— 构造谱聚类算法的目标函数 2018.9
[7] 谱聚类(spectral clustering)及其实现详解 2021.11
[8] 谱聚类的原理和优化目标 2019.7