Observation-Centric SORT 论文+代码笔记 (更新中)
本文作为OC-SORT的论文阅读记录,中间可能会加入自己的看法,由于是tracking这块的初学者,文中若有错误的认识麻烦读者帮忙修正。
1 前言
OC-SORT是来自CVPR2022的一篇文章,采用的范式是MOT中的TBD(Tracking by Detection)。虽然学术界中JDE的研究越来越多,2022年开始也有很多基于Transformer的方法效果非常不错,但是目前工业界还是使用TBD这种方式比较多,类似还有Bytetrack等等,基本都可以满足跟踪的需求。
TBD范式中比较出名的一系列就是SORT系列,这其中笔者了解的有最初的鼻祖SORT,还有后期衍生出来的DeepSORT, StrongSORT, StrongSORT++, ByteTrack,还有本文要讨论的OC-SORT。
关于SORT系列方法具体解析可以参考下面的博客和帖子,个人认为写的很详细和易懂,方便随时查阅:
- SORT, DeepSORT:知乎上Harlet的总结https://zhuanlan.zhihu.com/p/97449724
- StrongSORT系列:https://blog.csdn.net/gubeiqing/article/details/123488715
- ByteTrack:https://blog.csdn.net/zhouchen1998/article/details/120932206
2 Motivation
通过回顾SORT方法,作者提出三个问题作为方法设计的动机:
- 高帧率视频不利于抑制目标运动产生的噪声 Sensitive to State Noise
比如,目标对象在连续帧之间的位移仅为几个像素,移动的距离可能和估计产生的噪声(这里我理解为误差/偏差)相同,这样一来卡尔曼滤波的估计结果会存在很大的方差。 - 误差累积 Temporal Error Magnification
当出现遮挡或者非线性运动(比如跳舞)的情况,1.中的状态噪声(误差)会进一步累积。 - Estimation-Centric
在1和2的基础上,以估计为中心的KF模型就会在丢失目标的情况下出现问题。卡尔曼滤波预测基于状态,检测只作为辅助信息。作者认为现在检测器的效果很好,可以更多关注这部分的信息。
3 方法
文章提出三项改进:
OOS(Observation-centric Online Smoothing):减少KF带来的累积误差
OCM(Observation-centric Momentum):在代价矩阵中加入轨迹的方向一致性,更好地实现匹配
OCR(Observation-centric Recovery):恢复由于遮挡造成的跟丢问题
3.1 Observation-centric Online **Smoothing,**OOS
这种在线平滑方式通过当前帧检测到的结果和之前帧的轨迹位置,来生成更多的虚拟点,以此辅助KF做预测。具体通过⼀个虚拟的轨迹对参数进行在线平滑,回溯到目标检测丢失的时候,可以修复在时间间隔内累积的误差。
3.2 Observation-centric **Momentum,**OCM
在计算IOU度量矩阵的时候,把速度/方向计算成代价矩阵放在原来的度量矩阵中,(个人理解类似模型训练的trick):
这部分看的不是很懂…
3.3 Observation-centric Recovery,OCR
OCR用于恢复轨迹,这部分依赖于检测值而不是错误的估计值。当轨迹丢失后检测目标再出现时,直接将丢失轨迹时检测值和重新出现的检测值相关联以恢复轨迹。
参考
————————————————————————————————————————————————————————————
代码部分
首先读入视频帧后,是yolox实现检测部分:
if ret_val:
## outputs是yolox输出的检测结果 维度是[n,7] n表示检测框的数量 7是7个参数
outputs, img_info = predictor.inference(frame, timer)
这里7个维度的参数应该和SORT中的7个状态变量一样:
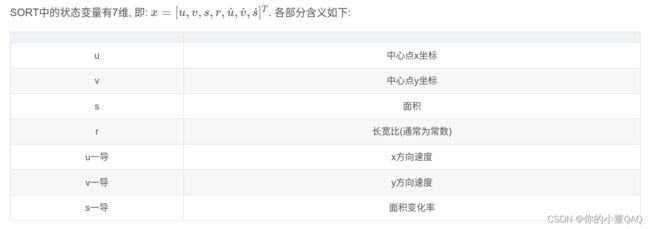
然后放进OCSORT算法中进行轨迹的预测和联合匹配:
online_targets = tracker.update(outputs[0], [img_info['height'], img_info['width']], exp.test_size)
update函数用来作轨迹的生成和匹配,下面主要记录这部分:
trackers/ocsort_tracker/ocsort.py
if output_results is None:
return np.empty((0, 5))
self.frame_count += 1
# post_process detections
if output_results.shape[1] == 5:
scores = output_results[:, 4]
bboxes = output_results[:, :4]
else:
output_results = output_results.cpu().numpy()
scores = output_results[:, 4] * output_results[:, 5] ##计算N个目标的置信度分数
bboxes = output_results[:, :4] # x1y1x2y2 N个目标的BBOX坐标
img_h, img_w = img_info[0], img_info[1]
scale = min(img_size[0] / float(img_h), img_size[1] / float(img_w))
bboxes /= scale
dets = np.concatenate((bboxes, np.expand_dims(scores, axis=-1)), axis=1) # 检测结果:bboxes+置信度得分
inds_low = scores > 0.1
inds_high = scores < self.det_thresh
inds_second = np.logical_and(inds_low, inds_high) # self.det_thresh > score > 0.1, for second matching 置信度在0.1-0.6 二次匹配
dets_second = dets[inds_second] # detections for second matching 二次筛选后的检测结果
remain_inds = scores > self.det_thresh
dets = dets[remain_inds] ##以我测试的视频为例 第一帧检测结果筛选前是41个人 筛选后是26个
正常生成轨迹框:
在第一帧就是常规的目标跟踪流程,首先是associate过程,三个变量的含义参考SORT中的解释(见表格):
"""
First round of association // oc-sort的associate过程
"""
matched, unmatched_dets, unmatched_trks = associate(
dets, trks, self.iou_threshold, velocities, k_observations, self.inertia)
for m in matched:
self.trackers[m[1]].update(dets[m[0], :])
| 变量 | 含义 |
|---|---|
| matched | 跟踪成功目标的矩阵。即前后帧都存在的目标,并且匹配成功同时大于iou阈值。 |
| unmatched_dets | 检测框中出现新目标,但此时预测框(跟踪框)中仍不不存在该目标 (比如第一帧中就只有这个变量不为空),那么就需要在创建新目标对应的预测框/跟踪框(KalmanBoxTracker类的实例对象),然后把新目标对应的KalmanBoxTracker类的实例对象放到跟踪器链(列表)中。同时如果因为“跟踪框和检测框之间的”两两组合的匹配度IOU值小于iou阈值【或其他匹配方式】,则也要把目标检测框放到unmatched_detections中。 |
| matched_trks | 当跟踪目标失败或目标离开了画面时,也即目标从检测框中消失了,就应把目标对应的跟踪框(预测框)从跟踪器链中删除。 unmatched_trackers列表中保存的正是跟踪失败即离开画面的目标,但该目标对应的预测框/跟踪框(KalmanBoxTracker类的实例对象)此时仍然存在于跟踪器链(列表)中,因此就需要把该目标对应的预测框/跟踪框(KalmanBoxTracker类的实例对象)从跟踪器链(列表)中删除出去。同时如果因为“跟踪框和检测框之间的”两两组合的匹配度IOU值小于iou阈值,则也要把跟踪目标框放到unmatched_trackers中. |
kf预测轨迹框,放入ret中:
# create and initialise new trackers for unmatched detections 在第一帧 所有检测轨迹都标记为unmatched 为所有检测框匹配跟踪框
for i in unmatched_dets:
trk = KalmanBoxTracker(dets[i, :], delta_t=self.delta_t) ### 将新增的未匹配的检测结果dets[i,:]传入KalmanBoxTracker
self.trackers.append(trk) # 将新创建和初始化的跟踪器trk 传入trackers
i = len(self.trackers)
for trk in reversed(self.trackers): # 对新的卡尔曼跟踪器集进行倒序遍历
if trk.last_observation.sum() < 0:
d = trk.get_state()[0] # 获取trk跟踪器的状态 [x1,y1,x2,y2] 返回当前边界框的估计值
else:
"""
this is optional to use the recent observation or the kalman filter prediction,
we didn't notice significant difference here
"""
d = trk.last_observation[:4]
if (trk.time_since_update < 1) and (trk.hit_streak >= self.min_hits or self.frame_count <= self.min_hits):
# +1 as MOT benchmark requires positive
ret.append(np.concatenate((d, [trk.id+1])).reshape(1, -1)) ## 跟踪成功目标的box与id放入ret列表中
i -= 1
# remove dead tracklet
if(trk.time_since_update > self.max_age):
self.trackers.pop(i)
if(len(ret) > 0):
return np.concatenate(ret)
return np.empty((0, 5))
参考
[1] https://blog.csdn.net/wjpwjpwjp0831/article/details/124767905?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124767905-blog-124358924.pc_relevant_antiscanv2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124767905-blog-124358924.pc_relevant_antiscanv2&utm_relevant_index=2