【影像组学】分类器模型设计- 随机森林 + 支持向量机
文章目录
- 1. 随机森林分类
- 2. 支持向量机分类
1. 随机森林分类
-
决策树(
Decision Tree)
• 是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率。
• 决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。 -
在 Python 中实现决策树
• 函数:sklearn.tree.DecisionTreeClassifier (from sklearn.tree import DecisionTreeClassifier)
• 模型初始化:dt_model = DecisionTreeClassifier()
• 训练数据:dt_model.fit(X, y) -
随机森林
• 随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。 -
随机森林的主要优势
• 具有极好的准确率
• 能够有效地运行在大数据集上
• 能够处理具有高维特征的输入样本
• 能够评估各个特征在分类问题上的重要性(权重) -
在 Python 中实现随机森林分类
• 函数:from sklearn.ensemble import RandomForestClassifier
• 模型初始化:model_rf = RandomForestClassifier()
• 训练数据:model_rf.fit(X, y) -
随机森林分类 python 代码:
R代码参考:R语言-分类之随机森林篇# 导入包 import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler from scipy.stats import ttest_ind, levene from sklearn.linear_model import LassoCV from sklearn.utils import shuffle from sklearn.ensemble import RandomForestClassifier # 随机森林分类器 from sklearn.model_selection import train_test_split # 训练集测试集分割 # 导入数据 xlsx_a = 'data/featureTable/aa.xlsx' xlsx_b = 'data/featureTable/bb.xlsx' data_a = pd.read_excel(xlsx_a) data_b = pd.read_excel(xlsx_b) print(data_a.shape,data_b.shape) # (212, 30) (357, 30) # t 检验特征筛选 index = [] for colName in data_a.columns[:]: if levene(data_a[colName], data_b[colName])[1] > 0.05: if ttest_ind(data_a[colName], data_b[colName])[1] < 0.05: index.append(colName) else: if ttest_ind(data_a[colName], data_b[colName],equal_var=False)[1] < 0.05: index.append(colName) print(len(index)) # 25 print(index) # ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'K', 'M', 'N', 'P', 'Q', 'R', 'U', 'V', 'W', 'X', 'Y', 'Z', 'AA', 'AB', 'AC', 'AD'] # t 检验后数据处理 data_a = data_a[index] data_b = data_b[index] rows_a,cols_a = data_a.shape rows_b,cols_b = data_b.shape labels_a = np.zeros(rows_a) labels_b = np.ones(rows_b) data_a.insert(0, 'label', labels_a) data_b.insert(0, 'label', labels_b) data = pd.concat([data_a,data_b]) data = shuffle(data) data.index = range(len(data)) X = data[data.columns[1:]] y = data['label'] X = X.apply(pd.to_numeric, errors='ignore') colNames = X.columns X = X.fillna(0) X = X.astype(np.float64) X = StandardScaler().fit_transform(X) X = pd.DataFrame(X) X.columns = colNames print(data.shape) # (569, 26) # LASSO 特征筛选 alphas = np.logspace(-4,1,50) model_lassoCV = LassoCV(alphas = alphas,max_iter = 100000).fit(X,y) coef = pd.Series(model_lassoCV.coef_, index = X.columns) print(model_lassoCV.alpha_) print('%s %d'%('Lasso picked',sum(coef != 0))) print(coef[coef != 0]) index = coef[coef != 0].index # 提取权重不为 0 的特征数据 X = X[index] np.set_printoptions(threshold=np.inf) # 设置输出结果不带省略 # 分割训练集、测试集 X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state = 15) # X 数据,y label 分组,test_size=0.3 训练集:测试集=7:3,random_state = 15(随机种子) # 随机森林分类 model_rf = RandomForestClassifier( n_estimators = 200 # default 100 设置随机森林中有多少棵树 , criterion = 'entropy' # 分类标准:'gini' and 'entropy'熵,default 'gini',gini 指数 , random_state = 20 # default = None(随机种子) , class_weight = 'balanced' # default = None 分类出的数据组别之间平衡处理 ) model_rf.fit(X_train,y_train) # 训练集训练 # print(model_rf.score(X_test,y_test)) # 测试集准确率 # print(model_rf.predict(X_test)) # 测试集各病例基于训练集模型的预测结果 # print(model_rf.predict_proba(X_test)) # 测试集预测结果的预测概率 # print(model_rf.n_features_) # 拟合模型过程中用了多少特征 # print(model_rf.feature_importances_) # 各特征的权重,权重加和=1 print(model_rf.get_params()) # 构建模型时的各项参数
2. 支持向量机分类
-
支持向量机:support vector machines, SVM
• 一种二分类模型(实际是可以做多分类的,对 SVM 加工)
• 基本模型:定义在特征空间上的间隔最大的线性分类器(实际具有非线性)
• 基本思想:求解能够正确划分训练数据集并且几何间隔最大的分离 超平面(类比二位空间中的直线,三维空间中的平面,可以划分两个病例分类。)
• 具有核技巧,这使它成为实质上的非线性分类器
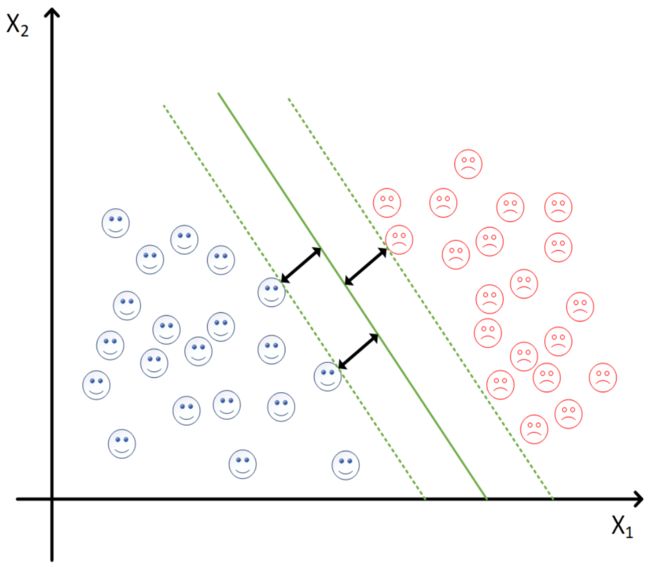
-
核函数
• 实际应用中,大部分数据不是线性可分的,即不存在满足条件的超平面
• 通过核函数可以将数据映射到高维空间,解决原始空间线性不可分问题
• 常用核函数:线性核函数(linear),多项式核函数(poly),径向基核函数(rbf),sigmoid 核函数(S 形)

-
rbf 径向基核函数的重要参数
• 参数γ(gamma):定义了单个样本的影响范围,γ 越大,支持向量越多(考虑的样本越多,考虑所有样本容易过拟合,如下图黄线)
• 惩罚因子C:定义了对“犯规”样本的容忍程度
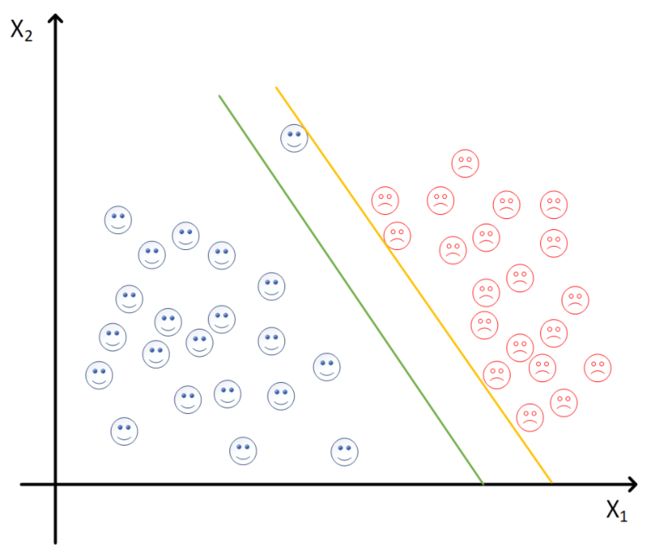
-
在 Python 中实现支持向量机分类
• 函数:from sklearn.svm import SVC
• 模型初始化:model_svc = svm.SVC(kernel = ‘rbf’, gamma = 0.05, C = 1)设置核函数 kernel、参数 γ 和惩罚因子 C。
• 数据训练:model_svc.fit(X_train, y_train)
• 准确率:model_svc.score(X, y)
• 获取参数:model_svc.get_params() -
参考资料:
分类算法之支持向量机:SVM(理论篇)
分类算法之支持向量机:SVM(应用篇) -
支持向量机分类 python 代码:
除了导入模块不同,SVM 分类前的步骤与随机森林分类相同。# 导入包 import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler from scipy.stats import ttest_ind, levene from sklearn.utils import shuffle from sklearn.linear_model import LassoCV from sklearn.model_selection import train_test_split from sklearn.svm import SVC # 支持向量分类器 # 导入数据 xlsx_a = 'data/featureTable/aa.xlsx' xlsx_b = 'data/featureTable/bb.xlsx' data_a = pd.read_excel(xlsx_a) data_b = pd.read_excel(xlsx_b) print(data_a.shape,data_b.shape) # (212, 30) (357, 30) # t 检验特征筛选 index = [] for colName in data_a.columns[:]: if levene(data_a[colName], data_b[colName])[1] > 0.05: if ttest_ind(data_a[colName], data_b[colName])[1] < 0.05: index.append(colName) else: if ttest_ind(data_a[colName], data_b[colName],equal_var=False)[1] < 0.05: index.append(colName) print(len(index)) # 25 print(index) # ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'K', 'M', 'N', 'P', 'Q', 'R', 'U', 'V', 'W', 'X', 'Y', 'Z', 'AA', 'AB', 'AC', 'AD'] # t 检验后数据处理 data_a = data_a[index] data_b = data_b[index] rows_a,cols_a = data_a.shape rows_b,cols_b = data_b.shape labels_a = np.zeros(rows_a) labels_b = np.ones(rows_b) data_a.insert(0, 'label', labels_a) data_b.insert(0, 'label', labels_b) data = pd.concat([data_a,data_b]) data = shuffle(data) data.index = range(len(data)) X = data[data.columns[1:]] y = data['label'] X = X.apply(pd.to_numeric, errors='ignore') colNames = X.columns X = X.fillna(0) X = X.astype(np.float64) X = StandardScaler().fit_transform(X) X = pd.DataFrame(X) X.columns = colNames print(data.shape) # (569, 26) # LASSO 特征筛选 alphas = np.logspace(-4,1,50) model_lassoCV = LassoCV(alphas = alphas,max_iter = 100000).fit(X,y) coef = pd.Series(model_lassoCV.coef_, index = X.columns) print(model_lassoCV.alpha_) print('%s %d'%('Lasso picked',sum(coef != 0))) print(coef[coef != 0]) index = coef[coef != 0].index # 提取权重不为 0 的特征数据 X = X[index] np.set_printoptions(threshold=np.inf) # 设置输出结果不带省略 # 分割训练集、测试集 X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state = 15) # X 数据,y label 分组,test_size=0.3 训练集:测试集=7:3,random_state = 15(随机种子) # SVM 分类 model_svm = SVC(kernel='rbf', gamma = 'scale', probability=True) # 设置核函数为 rbf # gamma = 'scale' =1/(特征数×方差);'auto' = 1/特征数;还可以写浮点数,具体需要做参数优化 # probability=True 设置为 True,后面才能查看概率 # 训练集拟合模型 model_svm.fit(X_train,y_train) # print(model_svm.score(X_test,y_test)) # 测试集准确率 # print(model_svm.predict(X_test)) # 测试集各病例基于训练集模型的预测结果 # print(model_svm.predict_proba(X_test)) # 测试集预测结果的预测概率 print(model_svm.get_params()) # 构建模型时的各项参数