pandas时序数据分析
数据是一个每小时广告的点击数
原数据形式如下:

分析
1.整体分析
先按时间顺序将数据进行画图,由于原时间格式不太对,所以先转化一下,这样会比较方便地提取时间信息。
import pandas as pd
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
csv_data = pd.read_csv("ads.csv")
#转化时间特征
csv_data['datatime']= pd.to_datetime(csv_data['Time'])
date_gb=csv_data.groupby('datatime').agg({'Ads':'sum'})
date_gb.plot(figsize=(12,6),grid=True)
结果如下:

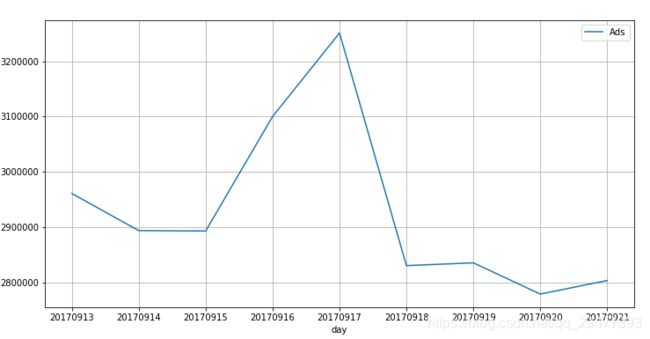
2.对'day'分析。
先构建day属性。然后对day聚合求和,计算每天的总点击数
#构建day特征
csv_data['day'] = csv_data['datatime'].apply(lambda x: x.strftime('%Y%m%d'))
#print(csv_data)
day_gb=csv_data.groupby('day').agg({'Ads':'sum'})
day_gb.plot(figsize=(12,6),xticks = range(0,len(day_gb)),grid=True)
如下图,发现在9月17号这天点击数最大。
3.对hour分析
先构建hour特征,求每天某时刻的平均点击次数
csv_data['hour'] = csv_data['datatime'].apply(lambda x: x.strftime('%H'))
hour_gb=csv_data.groupby('hour').agg({'Ads':'mean'})
hour_gb.plot(figsize=(12,6),xticks = range(0,len(hour_gb)),grid=True)
如下图,每天的18 19点时平均的点击次数最大。

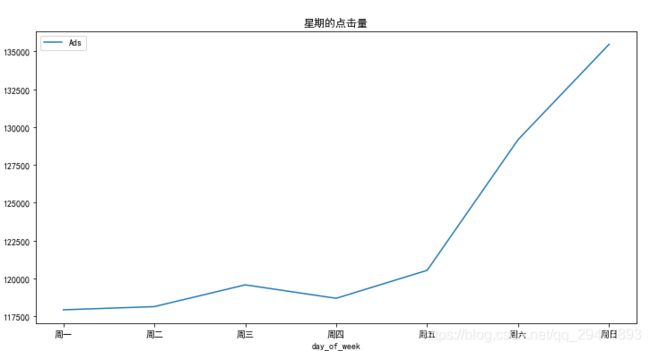
4.对week分析
统计每周星期几的平均点击次数
csv_data['day_of_week'] = csv_data['datatime'].apply(lambda x: x.weekday_name)
cats = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
csv_data.groupby('day_of_week').agg({'Ads':'mean'}).reindex(cats).plot(figsize=(12,6))
ticks = list(range(0, 7, 1))
labels = "周一 周二 周三 周四 周五 周六 周日".split()
plt.xticks(ticks, labels)
plt.title('星期的点击量')
如下图,可见每周末的平均点击量最高
完整代码
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 18 15:14:03 2020
@author: cong
"""
import pandas as pd
#from pandas import Series, DataFrame
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
csv_data = pd.read_csv("ads.csv")
#转化时间特征
csv_data['datatime']= pd.to_datetime(csv_data['Time'])
date_gb=csv_data.groupby('datatime').agg({'Ads':'sum'})
date_gb.plot(figsize=(12,6),grid=True)
#构建day特征
csv_data['day'] = csv_data['datatime'].apply(lambda x: x.strftime('%Y%m%d'))
#print(csv_data)
day_gb=csv_data.groupby('day').agg({'Ads':'sum'})
day_gb.plot(figsize=(12,6),xticks = range(0,len(day_gb)),grid=True)
csv_data['hour'] = csv_data['datatime'].apply(lambda x: x.strftime('%H'))
hour_gb=csv_data.groupby('hour').agg({'Ads':'mean'})
hour_gb.plot(figsize=(12,6),xticks = range(0,len(hour_gb)),grid=True)
csv_data['day_of_week'] = csv_data['datatime'].apply(lambda x: x.weekday_name)
cats = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
csv_data.groupby('day_of_week').agg({'Ads':'mean'}).reindex(cats).plot(figsize=(12,6))
ticks = list(range(0, 7, 1))
labels = "周一 周二 周三 周四 周五 周六 周日".split()
plt.xticks(ticks, labels)
plt.title('星期的点击量')