【深度学习原理第9篇】DenseNet模型详解
目录
-
- 一、背景概述
- 二、DenseNet
-
- 2.1 DenseBlock
- 2.2 Transition Layer
- 2.3 DenseNet网络结构
- 实验结果
一、背景概述
DenseNet是2017年CVPR的最佳论文,它不同于ResNet中的残差结构,也不同于GoogLetNet中的Inception网络结构。DenseNet提出了一种新的提升性能的思路,即作者通过对特征层的极致利用,使模型有了更好的性能,并且相比ResNet进一步减少了参数,提高了性能,特征层的极致利用表现在更密集的特征连接,密集连接也是本篇文章的核心。让我们一起来学习它吧。
二、DenseNet
论文地址:https://arxiv.org/pdf/1608.06993.pdf
下图为DenseNet网络结构简单描述,我们可以看出它由多个DenseNet Block组成。

2.1 DenseBlock

我们可以看上图,上图为DenseNet的Dense Block结构,DenseNet就是由多个这样的Dense Block结构组成,它的核心思想就是后面每个层都会接受其前面所有层作为其额外的输入,可以看到最后Transition Layer处,所有颜色的线都有,也就是前面所有层都作为输入。如下面的公式,i 层的输出Xi 是前i-1层作为输入经过非线性变换得到。
DenseNet公式如下:
![]()
分析:图中X0,X1,X2,X3,Xi-1表示特征图,Hi表示非线性变换,非线性变换H是BN+ReLU+Conv(1×1)+Conv(3×3)的组合,[]表示将所有输出的特征层按通道组合拼接在一起,在一个卷积模块乃至整个Dense Block中,特征尺寸不变,这是为了拼接Concat时方便,1×1与3×3卷积,借鉴了以前的经典网络中减少参数的办法,算是一个小trick,现在网络基本都会用1×1和3×3来降低参数。
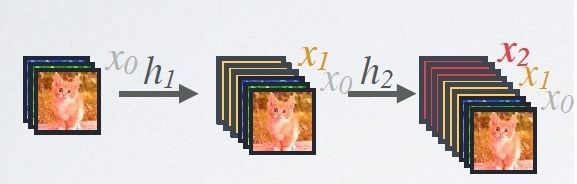
如上图,假设输入的特征层是x0,经过h1非线性变换后,得到x1和初始的x0堆叠,这是一个新的特征层,保留了x0和x1的特征。当网络程度不断加深,就可以实现前面所有层与后面层的具有密集连接。这样就实现了特征重用。
代码如下:
def dense_block(x, blocks, name):
for i in range(blocks):
x = conv_block(x, 32, name=name + '_block' + str(i + 1))
return x
def conv_block(x, growth_rate, name):
bn_axis = 3
x1 = layers.BatchNormalization(axis=bn_axis,
epsilon=1.001e-5,
name=name + '_0_bn')(x)
x1 = layers.Activation('relu', name=name + '_0_relu')(x1)
x1 = layers.Conv2D(4 * growth_rate, 1,
use_bias=False,
name=name + '_1_conv')(x1)
x1 = layers.BatchNormalization(axis=bn_axis, epsilon=1.001e-5,
name=name + '_1_bn')(x1)
x1 = layers.Activation('relu', name=name + '_1_relu')(x1)
x1 = layers.Conv2D(growth_rate, 3,
padding='same',
use_bias=False,
name=name + '_2_conv')(x1)
x = layers.Concatenate(axis=bn_axis, name=name + '_concat')([x, x1])
return x
代码中有个for循环,表示由多少个卷积模块组成。即卷积模块重复多少次。
对比ResNet
ResNet公式如下
![]()
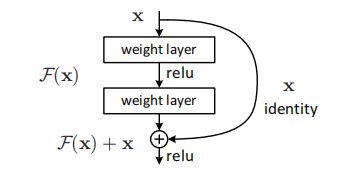
ResNet有一个残差边,所以加了个x
2.2 Transition Layer
Transition layer由BN + Conv(1×1) +2×2 average-pooling组成。Transition Layer将不同DenseBlock之间进行连接的模块,主要功能是整合上一个DenseBlock获得的特征,缩小上一个DenseBlock的宽高,达到下采样效果,特征图的宽高减半。
注:再次重申一下,作者希望各个Dense Block内的 feature map 的大小统一,这样做concatenation就直接堆叠即可,不必考虑size问题。也就是每一个Dense Block中的feature map 尺寸一样。
实现代码:
def transition_block(x, reduction, name):
bn_axis = 3
x = layers.BatchNormalization(axis=bn_axis, epsilon=1.001e-5,
name=name + '_bn')(x)
x = layers.Activation('relu', name=name + '_relu')(x)
x = layers.Conv2D(int(backend.int_shape(x)[bn_axis] * reduction), 1,
use_bias=False,
name=name + '_conv')(x)
x = layers.AveragePooling2D(2, strides=2, name=name + '_pool')(x)
return x
2.3 DenseNet网络结构
有了前面的知识,我们可以分析整个DenseNet网络结构了。
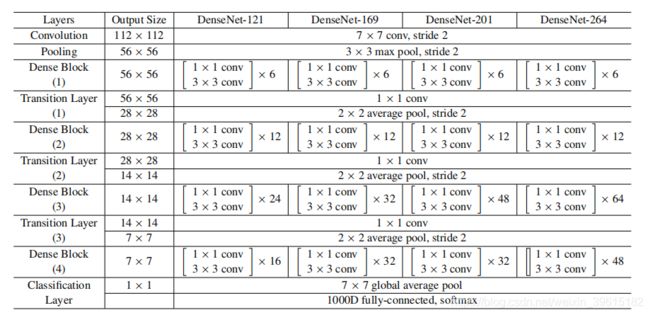
我们来看看这个结构,首先最上面有DenseNet-121,DenseNet-169,DenseNet-201以及DenseNet-264,其中121表示有121个卷积层,我们可以简单计算一下,
1 + 2 * 6 + 1 + 2 * 12 + 1 + 2 * 24 + 1 + 2 *16 + 1 = 121
整个结构由一开始的卷积Convolution(7×7卷积核,步长为2),再接一个池化Pooling,之后就是多个DenseBlock和Transition Layer,DenseBlock进行密集连接,而Transition Layer进行整合,并下采样average pool。最后7×7average pool后,加一个全连接fully-connected,这个全连接用softmax作为激活函数,也可以视为softmax层。
实验结果
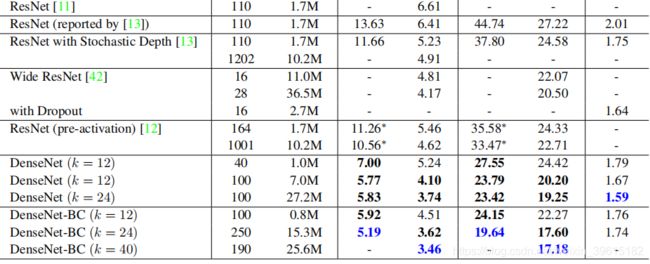
如图,相比ResNet,DenseNet的性能是更好的,其中k=24表示每一个DenseBlock输出的feature map都是24通道的,也是之前说的Dense Block中每个feature map的通道数都相同,这样方便Concat。DenseNet是将抽取的特征层并利用到极致,减少信息丢失,这一点它做的非常好,但是这个模型到现在也不是很流行。这是因为尽管它充分利用了特征,但是如果网络再复杂一些,可能开销就比较大了。但是这个对特征层利用的密集连接思想,意义巨大。
