轻量级卷积神经网络MobileNets详细解读
引言
随着深度学习的飞速发展,计算机视觉领域内的卷积神经网络种类也层出不穷。从1998年的LeNet网络到2012引起深度学习热潮年的AlexNet网络,再到2014年的VGG网络,再到后来2015的ResNet网络,深度学习网络在图像处理上表现得越来越好。但是这些网络都在不断增加网络深度和宽度来提高网络的准确度,如深度残差网络(ResNet)其层数已经多达152层。网络准确度虽然得到了极大提高,但是网络参数量变得越来越大,网络变得越来越复杂,运行模型需要大量的算力资源。这些网络模型对于像手机这样的移动端嵌入式设备并不适用。2017年,轻量级卷积神经网络MobileNet V1横空出世,使得深度卷积神经网络模型在移动终端,嵌入式设备上的应用成为了可能。
MobeileNet网络是由Google团队提出,专注于移动端或嵌入式等设备的轻量级神经网络。该系列网络有三个版本,分别是MobileNet V1,MobileNet V2,MobileNet V3,分别于2017年,2018,2019年提出。下面分别对这三个网络模型依次做解读。
一、MobileNet V1网络模型
网络中的创新点:
Deptwise Convolution(大大减少运算量和参数数量)。
增加超参数。
MobileNet V1版本的主要创新点在于将标准卷积替换为深度可分离卷积。深度可分离卷积相比于标准卷积,能够有效地减少计算量和模型参数。如下表所示,使用深度可分离卷积的MobileNet,相比于使用标准卷积的MobileNet,在ImageNet数据集上的精度下降了1.1%,但是模型参数减少了约7倍,加乘计算量减少了约9倍。

图1.1
深度可分离卷积(Depthwise separable convolution)
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中。深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,如图1.2所示。Depthwise convolution和传统卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。图1.3中更清晰地展示了两种操作。对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量(输入特征图通道数=卷积核个数=输出特征图个数)。
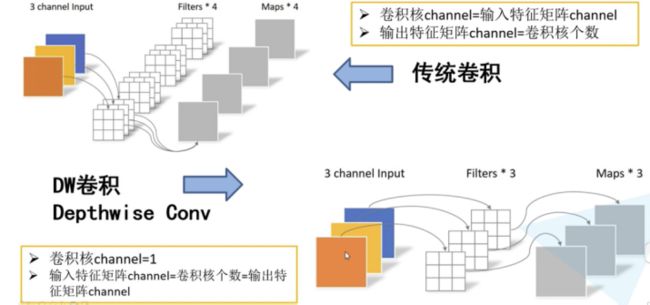
图1.2
图1.3
卷积计算量
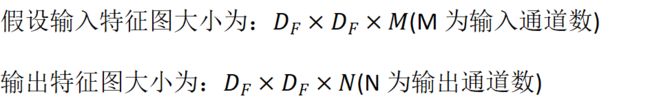
普通卷积

深度可分离卷积

图1.4
图1.4左:具有 batchnorm 和 ReLU 的标准卷积层。右:具有 Depthwise 和 Pointwise 层的 Depthwise Separable 卷积,然后是 batchnorm 和 ReLU 。
模型结构及其参数

MobileNet V1模型与Google Net,VGG16准确率对比

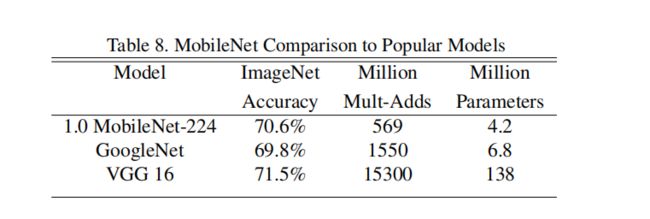
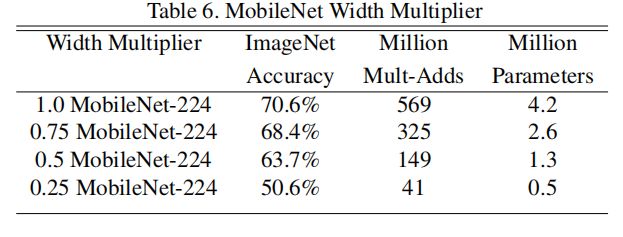
不同超参数值的模型对比
代表卷积核个数的倍率,用于控制卷积过程中卷积核的个数。Table6为不同时模型的准确率,计算量和参数量的变化情况。
不同超参数值的模型对比
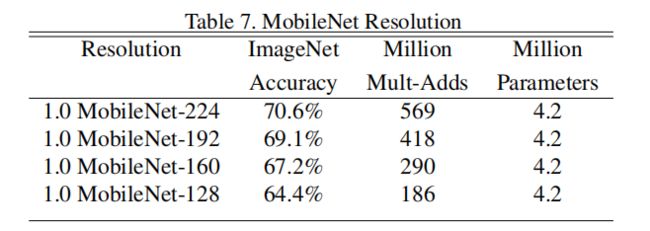
为分辨率参数,不同输入图像尺寸对模型准确率计算量和参数量的对比见Table7.
二、MobileNet V2网络模型结构
我们在MobileNetV1 中发现很多 DW 卷积权重为 0,其实是无效的。很重要的一个原因是因为 ReLU 激活函数对 0 值的梯度是 0,后续无论怎么迭代这个节点的值都不会恢复了,所以如果节点的值变为 0 就会“死掉”。而 ResNet 的残差结构可以很大程度上缓解这种特征退化问题。所以很自然的MobileNetV2 尝试引入 Residuals 模块并针对 ReLU 激活函数进行研究。
MobileNet v2网络简介
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。刚刚说了MobileNet v1网络中的亮点是DW卷积,那么在MobileNet v2中的亮点就是Inverted residual block(倒残差结构),如下下图所示,左侧是ResNet网络中的残差结构,右侧是MobileNet v2中的到残差结构。在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。
网络中的创新点:
Inverted Residuals (倒残差结构 )
Linear Bottlenecks(结构的最后一层采用线性层)
倒残差结构(Inverted Residuals )
倒残差结构就是首先采用卷积核升维操作,接下来用卷积核大小为DW卷积进行卷积,最后采用卷积核进行降维处理。其中激活函数为Relu6激活函数。如图2.1中(b)所示,(a)为普通残差结构,Relu6激活函数如图2.2所示。
图2.1
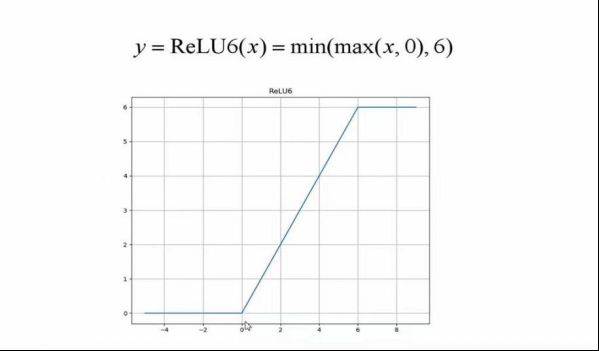
图2.2
图2.3
在使用倒残差结构时需要注意下,并不是所有的倒残差结构都有shortcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(只有当shape相同时,两个矩阵才能做加法运算,当stride=1时并不能保证输入特征矩阵的channel与输出特征矩阵的channel相同)如图2.4所示。
图2.4
网络模型结构
下图是MobileNet v2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1x1卷积的扩展因子),c代表输出特征矩阵的channel,n为倒残差结构重复的次数,s代表步距(注意:这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。
图2.5
三、MobileNet V3网络模型结构
简介
MobileNetV3 是由 google 团队于2019 年提出的,其原始论文为 Searching for MobileNetV3。
MobileNetV3 有以下四点创新点:
更新了激活函数,使用h-swish函数
更新 Block (bneck)
使用 NAS 搜索参数 (Neural Architecture Search)
重新设计耗时层结构
相比于 MobileNetV2 版本而言,具体 MobileNetV3 在性能上有哪些提升呢?在原论文摘要中,作者提到在 ImageNet 分类任务中正确率上升了 3.2%,计算延时还降低了 20%,如图3.1所示。
图3.1
更新BlocK (bneck)
首先我们来看一下在 MobileNetV3 中 block 如何被更新的。乍一看没有太大的区别,最显眼的部分就是加入了 SE 模块,即注意力机制;其次是更新了激活函数。
图3.2
这里的注意力机制想法非常简单,即针对每一个 channel 进行池化处理,就得到了 channel 个数个元素,通过两个全连接层,得到输出的这个向量。值得注意的是,第一个全连接层的节点个数等于 channel 个数的 1/4,然后第二个全连接层的节点就和 channel 保持一致。这个得到的输出就相当于对原始的特征矩阵的每个 channel 分析出来了其重要程度,越重要的赋予越大的权重,越不重要的就赋予越小的权重。我们用下图来进行理解,首先采用平均池化将每一个 channel 变为一个值,然后经过两个全连接层之后得到通道权重的输出,值得注意的是第二个全连接层使用 Hard-Sigmoid 激活函数。然后将通道的权重乘回原来的特征矩阵就得到了新的特征矩阵。
图3.3
在 MobileNetV3 中 block 的激活函数标注的是 NL,表示的是非线性激活函数的意思。因为在不同层用的不一样,所以这里标注的是 NL。一样的,最后 1 × 1 1 \times 11×1 卷积后使用线性激活函数(或者说就是没有激活函数)。
重新设计激活函数
我们来重点讲一讲重新设计激活函数这个部分,之前在 MobileNetV2 都是使用 ReLU6 激活函数。现在比较常用的是 swish 激活函数,即 x 乘上 sigmoid 激活函数。使用 swish 激活函数确实能够提高网络的准确率,但是呢它也有一些问题。首先就是其计算和求导时间复杂,光一个 sigmoid 进行计算和求导就比较头疼了。第二个就是对量化过程非常不友好,特别是对于移动端的设备,为了加速一般都会进行量化操作。为此,作者提出了一个叫做 h-swish 的激活函数。
在说 h-swish 之前,首先要说说 h-sigmoid 激活函数,它其实是 ReLU6 ( x + 3 ) / 6 \text{ReLU6}(x+3)/6ReLU6(x+3)/6。可以看出来它和 sigmoid 非常接近,但是计算公式和求导简单太多了。由于 swish 是 x 乘上 sigmoid,自然而言得到 h-swish 是 x 乘上 h-sigmoid。可以看到 swish 激活函数的曲线和 h-swish 激活函数的曲线还是非常相似的。作者在原论文中提到,经过将 swish 激活函数替换为 h-swish,sigmoid 激活函数替换为 h-sigmoid 激活函数,对网络的推理速度是有帮助的,并且对量化过程也是很友好的。注意,h-swish 实现虽然说比 swish 快,但和 ReLU 比还是慢不少。
重新设计耗时层结构
关于重新设计耗时层结构,原论文主要讲了两个部分。首先是针对第一层卷积层,因为卷积核比较大,所以将第一层卷积核个数从 32 减少到 16。作者通过实验发现,这样做其实准确率并没有改变,但是参数量小了呀,有节省大概 2ms 的时间!
第二个则是精简 Last Stage。作者在使用过程中发现原始的最后结构比较耗时。精简之后第一个卷积没有变化,紧接着直接进行平均池化操作,再跟两个卷积层。和原来比起来明显少了很多层结构。作者通过实验发现这样做正确率基本没有损失,但是速度快了很多,节省了 7ms 的推理时间,别看 7ms 少,它占据了全部推理时间的 11%
MobileNetV3 网络结构
下表给出的是MobileNetV3-large 的网络配置。Input 表示输入当前层的特征矩阵的 shape,#out 代表的就是输出的通道大小。exp size 表示 bneck 中第一个升维的 1 × 1 卷积输出的维度,SE 表示是否使用注意力机制,NL 表示当前使用的非线性激活函数,s 为步距 stride。bneck 后面跟的就是 DW 卷积的卷积核大小。注意最后有一个 NBN 表示分类器部分的卷积不会去使用 BN 层。
还需要注意的是第一个bneck 结构,它的 exp size 和输出维度是一样的,也就是第一个 1 × 1 卷积并没有做升维处理,所以在 pytorch 的官方实现中,第一个 bneck 结构中就没有使用 1 × 1卷积了,直接就是 DW 卷积了。
与MobileNetV2 一致,只有当 stride = 1 且 input channel = output channel 的时候才有 shortcut 连接。
Input表示输入尺寸
Operator中的NBN表示不使用BN,最后的conv2d 1x1相当于全连接层的作用
exp size表示bottleneck中的第一层1x1卷积升维,维度升到多少(第一个bottleneck没有1x1卷积升维操作)
out表示bottleneck输出的channel个数
SE表示是否使用SE模块
NL表示使用何种激活函数,HS表示HardSwish,RE表示ReLu
s表示步长(s=2,长宽变为原来一半)
网络配置如下图所示:
互补搜索技术组合
(1)资源受限的NAS(platform-aware NAS):计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search)。
(2)NetAdapt:用于对各个模块确定之后网络层的微调。
对于模型结构的探索和优化来说,网络搜索是强大的工具。研究人员首先使用了神经网络搜索功能来构建全局的网络结构,随后利用了NetAdapt算法来对每层的核数量进行优化。对于全局的网络结构搜索,研究人员使用了与Mnasnet中相同的,基于RNN的控制器和分级的搜索空间,并针对特定的硬件平台进行精度-延时平衡优化,在目标延时(~80ms)范围内进行搜索。随后利用NetAdapt方法来对每一层按照序列的方式进行调优。在尽量优化模型延时的同时保持精度,减小扩充层和每一层中瓶颈的大小。
实验结果
ImageNet分类实验结果如下: