《PyTorch深度学习实践》第十三课(循环神经网络RNN高级版)
b站刘二视频,地址:
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
网络模型
通过RNN模型,实现输出名字,对应出国家的功能
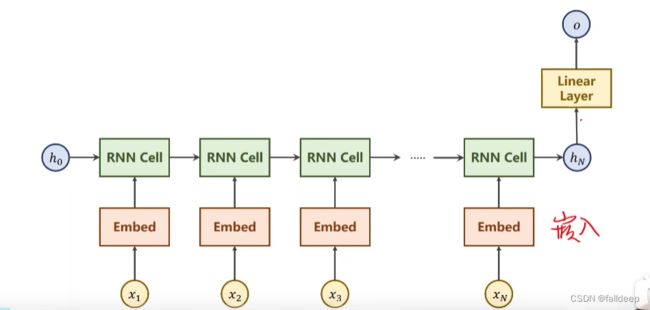
构造数据列表
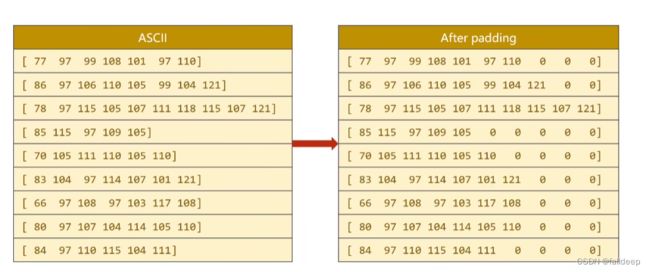
长短不一,构造成一样
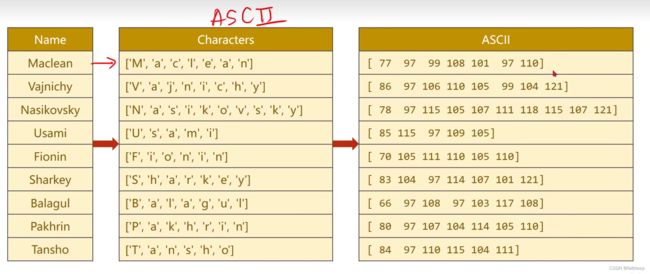
将国家做成输出索引

导入数据
如果以后数据集为pickle及其他的都可以用这种方法

模型
embedding层参数

GRU层参数
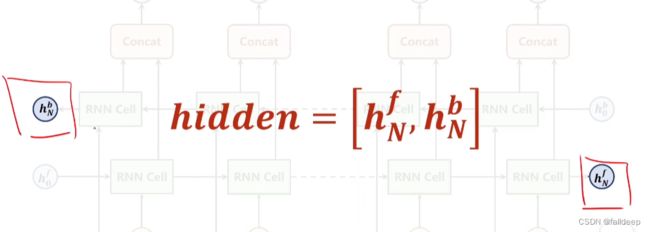
 bidirection双向神经网络
bidirection双向神经网络
双向,两边都走一遍,再拼接起来,起到了连接上下文的作用
最终输出的output,hidden
其中output是上面的h0到hn,output是【hnf,hnb】

最终的hidden是两个

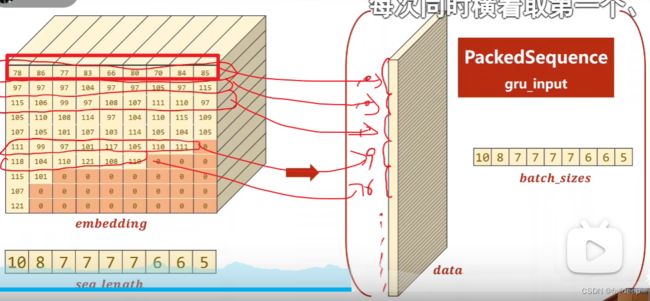
gru中因为序列长短不一,许多填充的是0,没必要参加运算,可以加速,使用 pack_padded_sequence
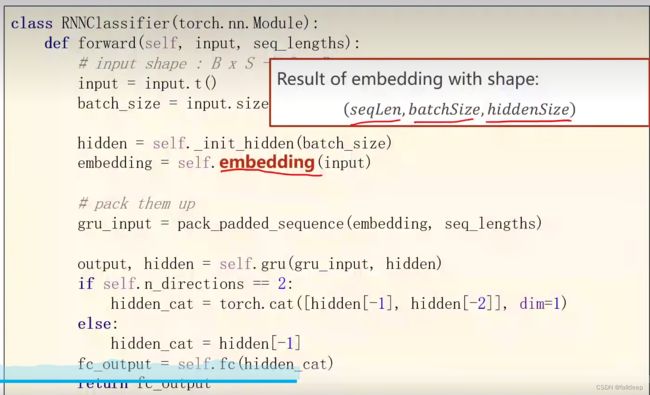
embedding 过程
返回一个PackedSquence object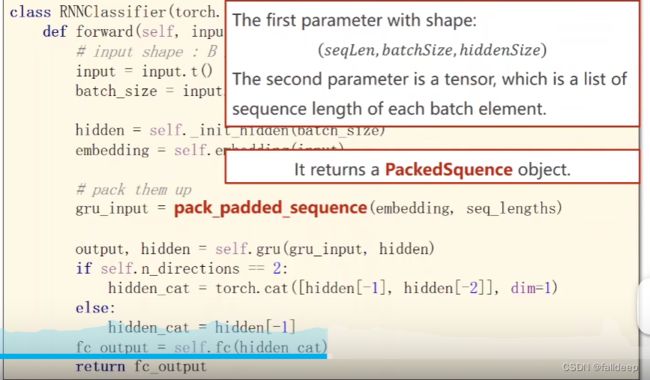
把为0的去除,其他的拼接在一起,但是他要求的是输入序列的长度递减,所以不行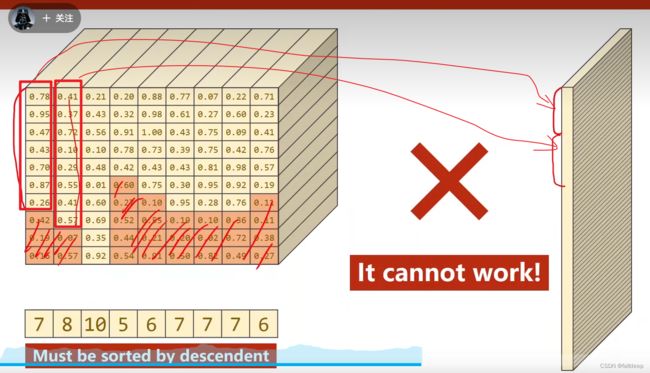
因此需要排序
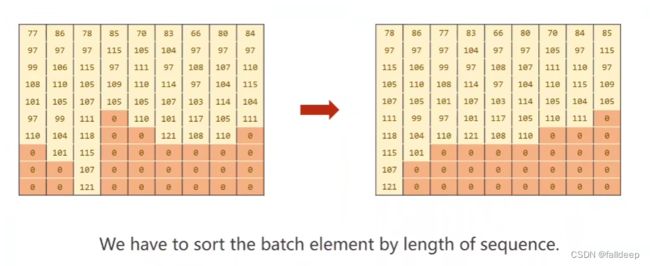
接下来是横着取值,按照时间序列取值,可以并行计算
留下了batch_sizes,gru就可以据此得出需要取多少行
 由名字转换为tensor的过程
由名字转换为tensor的过程
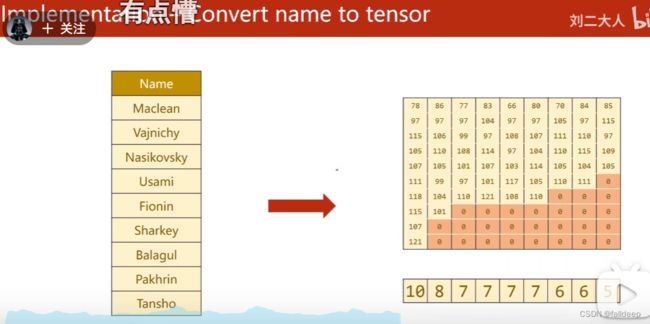
step1 转换为ascII
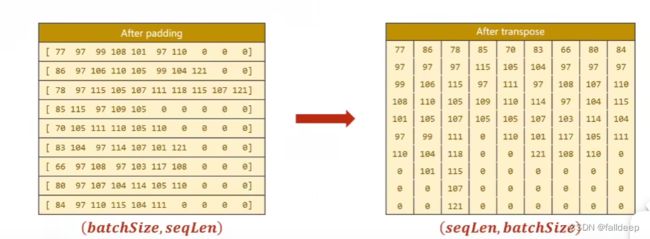
step2 做填充

step3做转置
step4 排序

完整代码
import csv
import gzip
import math
import time
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2
N_EPOCHS = 200
N_CHARS = 128
USE_GPU = False
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' %(m, s)
def name2list(name):
arr = [ord(c) for c in name]#得到ascii码
return arr, len(arr)
def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
def make_tensors(names, countries):
sequences_and_lengths = [name2list(name) for name in names]# s[0] name s[1] 长度
name_sequences = [s1[0] for s1 in sequences_and_lengths]
seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_lengths])
countries = countries.long()
#make tensor of name, BatchSize x seqlen
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seqlen) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seqlen] = torch.LongTensor(seq)
#sort by length to use pack padded sequence
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True) #sort 返回两个值 1.排序完的表 2.相对应的索引
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tensor), \
create_tensor(seq_lengths), \
create_tensor(countries)
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
filename = 'names_train.csv.gz' if is_train_set else 'name_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader)
self.names = [row[0] for row in rows]
self.len = len(self.names)
self.countries = [row[1] for row in rows]
self.country_list = list(sorted(set(self.countries)))
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list)
def __getitem__(self, idx):
return self.names[idx], self.country_dict[self.countries[idx]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict = dict()
for idx, country_name in enumerate(self.country_list, 0):
country_dict[country_name] = idx
return country_dict
def idx2country(self, index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num
trainset = NameDataset(True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(True)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=True)
N_COUNTRY = trainset.getCountriesNum()
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers,
bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
# 如果是双向的,最终hidden是两,要乘上2
def init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions,
batch_size, self.hidden_size)
return create_tensor(hidden)
def forward(self, input, seq_lengths):
# input shape : B x S -> S x B
input = input.t()
batch_size = input.size(1)
hidden = self.init_hidden(batch_size)
embedding = self.embedding(input)
#pack them up
gru_input = pack_padded_sequence(embedding, seq_lengths)
output, hidden = self.gru(gru_input, hidden)
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):#1 代表索引i从1开始,也代表轮数
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch}', end='')
print(f'[{i * len(inputs)} / {len(trainset)}]', end='')
print(f'loss={total_loss / (i * len(inputs))}')
return total_loss
def testModel():
correct = 0
total = len(testset)
print('evaluating trained model ...')
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%.2f' % (100 * correct / total)
print(f'Test set: Accuracy {correct} / {total} {percent}%')
return correct / total
if __name__ == '__main__':
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
# 字母表的个数 隐层 国家数 层数
if USE_GPU: #用GPU训练
device = torch.device("cuda:0")
classifier.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
start = time.time()
print("Training for %d epochs..." % (N_EPOCHS + 1))
acc_list = []
for epoch in range(1, N_EPOCHS + 1):
trainModel()
acc = testModel()
acc_list.append(acc)
epoch = np.arange(1, len(acc_list) + 1, 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()