深度学习第二周
1. 深度学习框架
近年来,深度学习在很多机器学习任务中都有着非常出色的表现,在图像识别、语音识别、自然语言处理、机器人、网络广告投放、医学自动诊断和金融等领域都有着广泛应用。面对繁多的应用场景,深度学习框架有助于建模者聚焦业务场景和模型设计本身,省去大量而繁琐的代码编写工作,其优势主要表现在如下两个方面:
- 节省编写大量底层代码的精力:深度学习框架屏蔽了底层实现,用户只需关注模型的逻辑结构,同时简化了计算逻辑,降低了深度学习入门门槛;
- 省去了部署和适配环境的烦恼:深度学习框架具备灵活的移植性,可将代码部署到CPU、GPU或移动端上,选择具有分布式性能的深度学习框架会使模型训练更高效。
深度学习框架的本质:
自动实现建模过程中相对通用的模块,建模者只实现模型中个性化的部分,这样可以在“节省投入”和“产出强大”之间达到一个平衡
在构建模型的过程中,每一步所需要完成的任务均可以拆分成个性化和通用化两个部分:
- 个性化部分:往往是指定模型由哪些逻辑元素组合,由建模者完成;
- 通用部分:聚焦这些元素的算法实现,由深度学习框架完成。

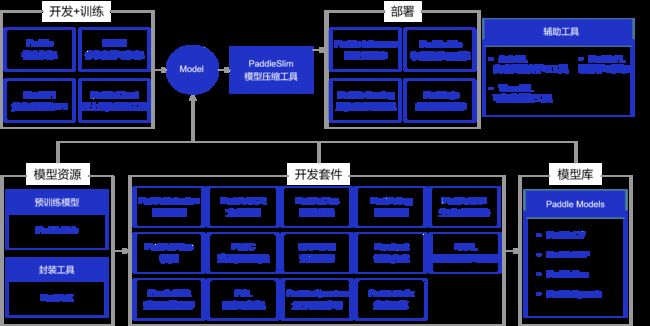
2.飞桨的一些介绍
飞桨深度学习开源开放平台包含核心框架、基础模型库、端到端开发套件与工具组件。
各组件的使用的场景:
飞桨的四大领先技术:

PaddlePaddle的安装与卸载:
开始使用_飞桨-源于产业实践的开源深度学习平台 (paddlepaddle.org.cn)
3.房价预测
步骤:

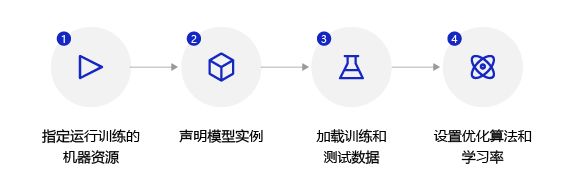
batch的取值会影响模型训练效果,batch过大,会增大内存消耗和计算时间,且训练效果并不会明显提升(每次参数只向梯度反方向移动一小步,因此方向没必要特别精确);batch过小,每个batch的样本数据没有统计意义,计算的梯度方向可能偏差较大。由于房价预测模型的训练数据集较小,因此将batch设置为10。
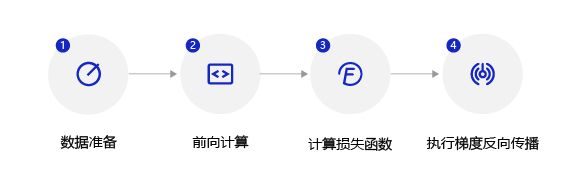
- 数据准备:将一个批次的数据先转换成nparray格式,再转换成Tensor格式;
- 前向计算:将一个批次的样本数据灌入网络中,计算输出结果;
- 计算损失函数:以前向计算结果和真实房价作为输入,通过损失函数square_error_cost API计算出损失函数值(Loss)。飞桨所有的API接口都有完整的说明和使用案例,可以登录飞桨官网API文档获取;
- 反向传播:执行梯度反向传播
backward函数,即从后到前逐层计算每一层的梯度,并根据设置的优化算法更新参数(opt.step函数)。
测试模型:
1.配置模型预测的机器资源
2.将训练好的模型参数加载到模型实例中。
3. 将训练好的模型参数加载到模型实例中。
两者对比现在能开出来的好处:直观上代码段简洁好多。:(
4.NumPy
简介:NumPy(Numerical Python的简称)是高性能科学计算和数据分析的基础包。使用飞桨构建神经网络模型时,通常会使用NumPy实现数据预处理和一些模型指标的计算,飞桨中的Tensor数据可以很方便的和ndarray数组进行相互转换。
NumPy的功能:
- ndarray数组:一个具有矢量算术运算和复杂广播能力的多维数组,具有快速且节省空间的特点;(房价预测模型中用到了)
- 对整组数据进行快速运算的标准数学函数(无需编写循环);
- 线性代数、随机数生成以及傅里叶变换功能;
- 读写磁盘数据、操作内存映射文件。
创建ndarray数组:
创建ndarray数组最简单的方式就是使用array函数,它接受一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的NumPy数组。
以下是四个函数:
array:创建嵌套序列(比如由一组等长列表组成的列表),并转换为一个多维数组。arange:创建元素从0到10依次递增2的数组。zeros:创建指定长度或者形状的全0数组。(零矩阵)ones:创建指定长度或者形状的全1数组。(单位矩阵)
查看ndarray数组的属性:
四个属性:
shape:数组的形状 ndarray.shape,1维数组(N, ),二维数组(M, N),三维数组(M, N, K)。dtype:数组的数据类型。size:数组中包含的元素个数 ndarray.size,其大小等于各个维度的长度的乘积。ndim:数组的维度大小,ndarray.ndim, 其大小等于ndarray.shape所包含元素的个数。
改变ndarray数组的数据类型和形状 : 数组名.astype()
ndarray的运算:
ndarray数组可以像普通的数值型变量一样进行加减乘除操作,主要包含如下两种运算:
- 标量和ndarray数组之间的运算
- 两个ndarray数组之间的运算
ndarray数组的索引和切片 :
ndarray数组的索引和切片的使用方式与Python中的list类似。通过[ -n , n-1 ]的下标进行索引,通过内置的slice函数,设置其start,stop和step参数进行切片,从原数组中切割出一个新数组。
多维ndarray数组的索引和切片具有如下特点:
- 在多维数组中,各索引位置上的元素不再是标量而是多维数组。
- 以逗号隔开的索引列表来选取单个元素。
- 在多维数组中,如果省略了后面的索引,则返回对象会是一个维度低一点的ndarray。
ndarray数组的统计方法 :
mean:计算算术平均数,零长度数组的mean为NaN。std和var:计算标准差和方差,自由度可调(默认为n)。sum:对数组中全部或某轴向的元素求和,零长度数组的sum为0。max和min:计算最大值和最小值。argmin和argmax:分别为最大和最小元素的索引。cumsum:计算所有元素的累加。cumprod:计算所有元素的累积。
随机数np.random,创建随机ndarray数组(随机梯度下降)
线性代数(如矩阵乘法、矩阵分解、行列式以及其他方阵数学等)是任何数组库的重要组成部分,NumPy中实现了线性代数中常用的各种操作,并形成了numpy.linalg线性代数相关的模块
diag:以一维数组的形式返回方阵的对角线(或非对角线)元素,或将一维数组转换为方阵(非对角线元素为0)。dot:矩阵乘法。trace:计算对角线元素的和。det:计算矩阵行列式。eig:计算方阵的特征值和特征向量。inv:计算方阵的逆。
NumPy文件:
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)
5.手写数字识别任务
MNIST数据集:
MNIST数据集是从NIST的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。Yann LeCun等人从SD-1和SD-3中各取一半数据作为MNIST训练集和测试集,其中训练集来自250位不同的标注员,且训练集和测试集的标注员完全不同。
编写适合当前任务的数据处理程序,一般涉及如下五个环节:
- 读入数据
- 划分数据集
- 生成批次数据
- 训练样本集乱序
- 校验数据有效性
"横纵式"教学法:
纵向概要介绍模型的基本代码结构和极简实现方案。
横向深入探讨构建模型的每个环节中,更优但相对复杂的实现方案。
例如:
在模型设计环节,除了在极简版本使用的单层神经网络(与房价预测模型一样)外,还可以尝试更复杂的网络结构,如多层神经网络、加入非线性的激活函数,甚至专门针对视觉任务优化的卷积神经网络。
优势:
- 帮助读者轻松掌握深度学习内容:采用这种方式设计教学案例,读者在学习过程中接收到的信息是线性增长的,在难度上不会有阶跃式的提高。
- 模拟真实建模的实战体验:先使用熟悉的模型构建一个可用但不够出色的基础(Baseline),再逐渐分析每个建模环节可优化的点,一点点的提升优化效果,让读者获得真实建模的实战体验
API 文档-API文档-PaddlePaddle深度学习平台
数据归一化(标准化)是数据预处理的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,为避免影响数据分析结果、消除指标之间的量纲影响,须对数据进行标准化处理。
使用深度学习构建训练时,通常需要数据归一化,以利于网络的训练,而在训练结果可视化中,通常需要反归一化。
训练样本乱序: 先将样本按顺序进行编号,建立ID集合index_list。然后将index_list乱序,最后按乱序后的顺序读取数据。
生成批次数据: 先设置合理的batch_size,再将数据转变成符合模型输入要求的np.array格式返回。同时,在返回数据时将Python生成器设置为yield模式,以减少内存占用。
6.异步数据读取
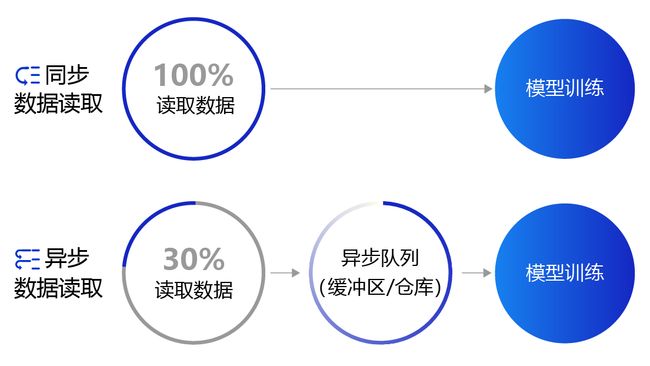
- 同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
- 异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
- 异步队列:数据读取和模型训练交互的仓库,二者均可以从仓库中读取数据,它的存在使得两者的工作节奏可以解耦。
- 解耦是指两个或两个以上的体系或两种运动形式间通过相互作用而彼此影响以至联合起来的现象