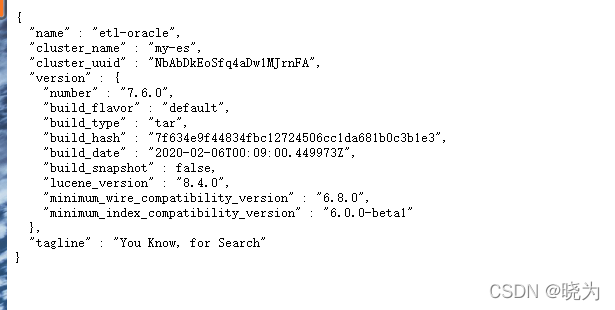
Elasticsearch安装以及语法学习
一、简介
借助官网介绍
Elasticsearch简介
您知道,用于搜索(和分析)
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎。Logstash和Beats有助于收集,聚合和丰富您的数据并将其存储在Elasticsearch中。使用Kibana,您可以交互式地探索,可视化和共享对数据的见解,并管理和监视堆栈。Elasticsearch是建立索引,搜索和分析魔术的地方。
Elasticsearch为所有类型的数据提供实时搜索和分析。无论您是结构化文本还是非结构化文本,数字数据或地理空间数据,Elasticsearch都能以支持快速搜索的方式有效地对其进行存储和索引。您不仅可以进行简单的数据检索,还可以聚合信息来发现数据中的趋势和模式。随着数据和查询量的增长,Elasticsearch的分布式特性使您的部署可以随之无缝地增长
学习理解
ES一般作为搜索引擎存在。现在官网上ELK协议栈作为了一个整体,还有其他的相关工具。已经有了其他方向的实践和探索
在生产实践中主要用来大数据的存储索引分析。可以和neo4j整合生成节点图。与hive整合作为存储映射,与深度学习相关整合作为相似性搜索使用
二、架构和基本概念
ES概述
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它
不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列
的数据)进行索引、搜索、排序、过滤。
Elasticsearch比传统关系型数据库如下:
Relational DB ‐> Databases ‐> Tables ‐> Rows ‐> Columns
Elasticsearch ‐> Indices ‐> Types ‐> Documents ‐> Fields
因为大家对于上面的Elasticsearch比传统关系型数据库的理解 其实并不符合真实含义(type并不是标的含义)为了避免混淆 在ES7之后已经不再将type作为一种类型了 可能之后会消失 在ES7中默认了type并且一个索引只有一个type
架构
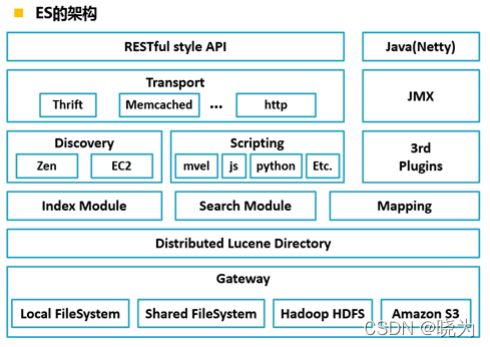
Gateway是ES用来存储索引的文件系统,支持多种类型。
Gateway的上层是一个分布式的lucene框架。
Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等
ES模块之上是 Discovery、Scripting和第三方插件。
Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,
这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。
Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本
语句性能稍低。ES也支持多种第三方插件。
再上层是ES的传输模块和JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是
java的管理框架,用来管理ES应用。
最上层是ES提供给用户的接口,可以通过RESTful接口和ES集群进行交互。
核心概念
索引 index
一个索引就是一个拥有几分相似特征的文档的集合。
类型 type
一个索引中可以有多个类型 但是在ES6时就只能有一个了 在ES7中已经默认一个不可更改了
文档document
一个文档是一个可被索引的基础信息单元 文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
字段 field
是一个文档的多个表现形式 也可以理解为文档是一行数据 而字段是一行中的某个字段 在现实使用中一般都是将一个索引数据作为二维表形式来使用
映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,一般写入索引数据时ES会自动推断数据类型。但是现实生产不推荐。应先建立mapping来确定字段的各个维度。
设置 settings
settings
集群、节点、分片复制
集群是由多台装有ES的服务器组成的系统来对外提供服务
节点为每台装有ES的服务器
分片复制在大数据中是个常用概念 目的是提升存储以及保证数据安全。分片是每个索引的存储可以分成多个部分 存储在不同的节点上 复制是对于每个部分的备份
三、安装
安装Elasticsearch
集群模式每一台都要安装ES。配置文件每一台都要相同除了一些关于本机的配置来组成集群
es-head以及kibana和tomcat安装一台即可
1.创建es普通用户
ES不能用root用户启动,只能用普通用户
#创建用户
useradd es
#创建一个es用户的目录
mkdir ‐p /data/es
chown ‐R es /data/es
#设置密码
passwd es
2.为es用户添加sudo权限
visudo
#添加内容:
es ALL=(ALL) ALL
使用es用户登录完成下面步骤
3.下载上传安装包并解压
进入官网下载 https://www.elastic.co/cn/
最好将ES以及kibana一起下载了 相关版本要对应
我下载的为7.6.0版本
对于ES的相关安装 我安装了ES,Kibana,ES-head,IK分词器,tomcat
相关资源在我的网盘中
链接:https://pan.baidu.com/s/1GQIXFP8xPW0mWisTZoZQXA
提取码:sf1g
我都解压到了/data/es目录下
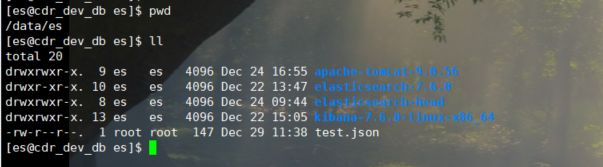
4.修改配置文件
集群要每一台都安装并且配置
进入es的配置文件目录:
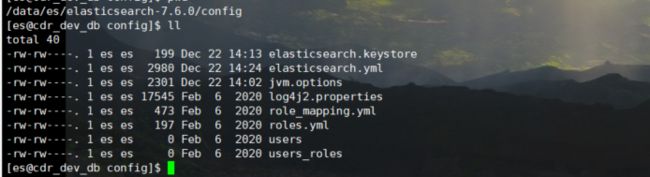
vim elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#集群名字
cluster.name: my-es
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#节点名称
node.name: etl-oracle
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#数据存储地址
path.data: /data/es/elasticsearch-7.6.0/datas
#
# Path to log files:
#log文件地址
path.logs: /data/es/elasticsearch-7.6.0/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#内存配置
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#本机ip地址
network.host: ip
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#允许跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# --------------------------------- Discovery ----------------------------------
#我的是单机的此处添加类型为单机
discovery.type: single-node
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#集群类型需要修改以下的配置 集群每一台的节点的ip
#如果要在其他主机上形成包含节点的群集,则必须使用discovery.seed_hosts设置提供群集中其他节点的列表
#discovery.seed_hosts: ["host1", "host2"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#集群类型需要修改以下的配置 集群每一台的节点的ip
#当您第一次启动全新的Elasticsearch集群时,会出现一个集群引导步骤,该步骤确定在第一次选举中计票的主要合#格节点集。 在开发模式下,如果未配置发现设置,则此步骤由节点本身自动执行。 由于此自动引导本质上是不安全#的,因此当您在生产模式下启动全新集群时,必须明确列出符合条件的节点的名称或IP地址,这些节点的投票应在第#一次选举中计算。 使用cluster.initial_master_nodes设置设置此列表。
#cluster.initial_master_nodes: ["node-1", "node-2"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
vim jvm.option
#根据自己服务器配置设置内存
-Xms4g
-Xmx4g

5.修改服务器的一些配置解决启动的错误
问题一 : 普通用户打开文件的最大数据限制
报错信息: max file descriptors [4096] for elasticsearch process likely too low, increase to at least
[65536]
错误原因: ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
sudo vim /etc/security/limits.conf
#添加如下内容:
#es为你创建的普通用户
es soft nofile 65536
es hard nofile 131072
es soft nproc 2048
es hard nproc 4096
问题二: 普通用户启动线程数限制
报错信息: max number of threads [1024] for user [es] likely too low, increase to at least [4096]
报错原因: 无法创建本地线程问题,用户最大可创建线程数太小
sudo vi /etc/security/limits.d/90‐nproc.conf
#es
es soft nproc 4096
问题三: 普通用户调大虚拟内存
错误信息: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at
least [262144]
错误原因: 最大虚拟内存太小
sudo sysctl ‐w vm.max_map_count=262144
#注意: 此命令每次启动es前, 都得执行一下才行
备注:以上三个问题解决完成之后,重新连接secureCRT或者重新连接xshell生效 需要保存、退出、重新登录才可生效
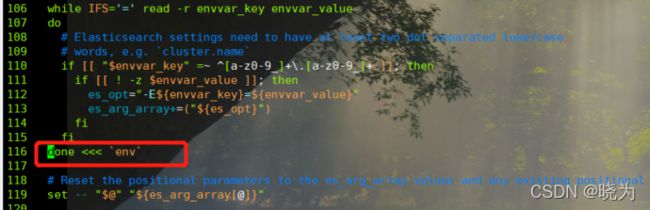
问题4
启动时可能还会报错关于elasticsearch-env文件的。当时没有记录错误 但是修改方案在下面
#修改大概116行的为下面代码
116 done <<< `env`
6.启动命令
#集群模式每台都要启动
nohup /data/es/elasticsearch-7.6.0/bin/elasticsearch 2>&1 &
访问页面:
http://ip:9200/?pretty 每台可查看
想要查看日志的话就去配置中设置的日志地址找my-es.log
安装Elasticsearch-head
因为es自带的页面 也就是上述的访问页面太丑没法看 所以安装Elasticsearch-head
1.安装node.js
node.js是一种运行环境 用来运行javascript语言 相当于运行java的jvm
可以在上面的分享资源中找到。
我安装的是node-v16.11.1-linux-x64.tar.gz
解压:

创建软连接:
sudo ln ‐s /data/node-v16.11.1-linux-x64/bin/node /usr/local/bin/node
sudo ln ‐s /data/node-v16.11.1-linux-x64/bin/npm /usr/local/bin/npm
查看是否成功:
2.安装es-head
可以下载源码自己编译
也可以用我的资源包里面的
编译会出现各种不可预料的情形 推荐直接用资源包解压来用
上传解压:
修改配置文件:
vim Gruntfile.js
//找到以下代码:
//修改一行: hostname: 'ip',
connect: {
server: {
options: {
hostname: 'ip',
port: 9100,
base: '.',
keepalive: true
}
}
}
cd /data/es/elasticsearch-head/_site
vim app.js
//将localhost改为ip
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://ip:9200";

启动停止命令
#进入目录
cd /data/es/elasticsearch-head/node_modules/grunt/bin
#前台启动 注意要用./执行 sh执行可能会报错
./grunt server
#后台启动 先后台命令启动 再退出ssh连接才真正后台启动了 其他前端后台启动也是这样
nohup ./grunt server >/dev/null 2>&1 &
exit
#杀掉
netstat ‐nltp | grep 910
kill -9 pid
访问页面:
http://ip:9100/
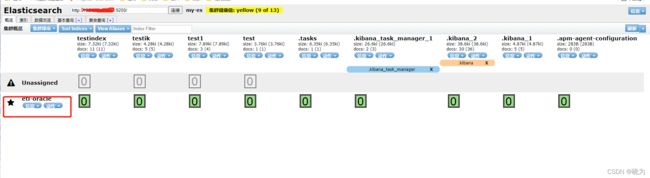
我的是单台机器 所以健康值为黄色的 正常集群启动后健康值为绿色才对
安装Kibana
1.简介
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。你用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。你可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
2.上传解压
要与ES的版本保持一致 可以在官网也可以在我分享的资源中获取
3.修改配置文件
vim /data/es/kibana-7.6.0-linux-x86_64/config/kibana.yml
#修改以下内容
kibana.ymlserver.host: "ip"
elasticsearch.hosts: ["http://ip:9200"]

4.启动命令
#进入bin目录
#启动
nohup sh kibana >/dev/null 2>&1 &
#停止
##查看进程号
ps ‐ef | grep node
##然后使用kill ‐9杀死进程即可
5.访问页面
http://192.168.101.45:5601/
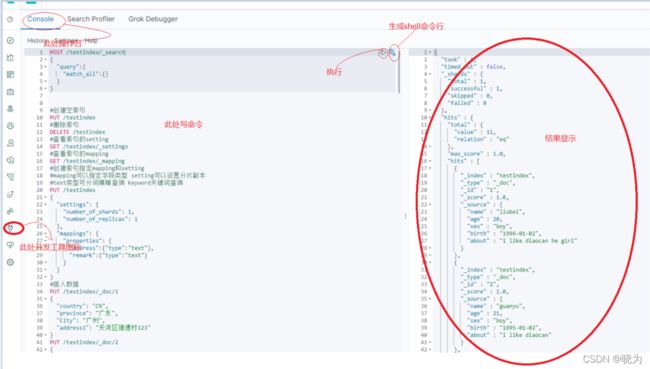
一般在上图开发工具中进行开发
安装ik分词器
注意:集群模式每一台都需要安装
搜索的核心需求是全文检索,全文检索简单来说就是要在大量文档中找到包含某个单词出现的位置,在传统关系型数据库中,数据检索只能通过 like 来实现 而在es中是通过分词来实现的
ES对于文本搜索的一个重要的功能就是分词,分词就是将传入ES中可分析字段中的数据进行词的切分。然后对于相关词建立倒排索引。
倒排索引扽为两部分 一部分就是单词词典 一部分为倒排列表 倒排索引可以这么理解:ES中存储单元是文档。而文档有一个唯一的id。倒排索引通过对于内容进行分词 将词作为搜索的key 文档id作为我们要获取的value。
与之相对应的是正排索引 也就是正排索引 以文档id作为key 以文档内容作为获取的value
ES在搜索时根据分词分出的词来去倒排索引中获取响应的文档id 再通过文档id去正排索引中获取文档内容
对于ES中的分词器来说有以下几种:
| 分词器 | 用途 |
|---|---|
| Standard Analyzer | 标准分词器,适用于英语等 |
| Simple Analyzer | 简单分词器,基于非字母字符进行分词,单词会被转为小写字母 |
| Whitespace Analyzer | 空格分词器,安装空格进行切分 |
| Stop Analyzer | 和简单分词器类似,但是增加了停用词的功能 |
| Keyword Analyzer | 关键词分词器,输入文本等于输出文本 |
| Pattern Analyzer | 利用正则表达式对文本进行切分,支持停用词 |
| Language Analyzer | 针对特定语言的分词器 |
| Fingerprint Analyzer | 指纹分析分词器,通过创建标记进行重复检测 |
对于ES的文本分析来说有几种自带的分词器 对于中文的切分不友好 所以安装IK分词器插件 来支持对于中文的词切分
1.下载安装解压
可以再githup上下载:https://github.com/medcl/elasticsearch-analysis-ik
注意:要下载对应版本的 我的是7.6.0
也可以在上面分享的资源中获取
cd /data/es/elasticsearch-7.6.0/plugins
mkdir ik
#将压缩包解压到ik目录下
2.重新启动es
#停止
ps ‐ef|grep elasticsearch|grep bootstravelap |awk '{print $2}' |xargs kill ‐9
#启动
nohup /data/es/elasticsearch-7.6.0/bin/elasticsearch 2>&1 &
说明:ik带有两个分词器:
ikmaxword : 会将文本做最细粒度的拆分; 尽可能多的拆分出词语
句子:我爱我的祖国
结果: 我|爱|我的|祖|国|祖国
ik_smart : 会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有
句子:我爱我的祖国
结果: 我|爱|我|的|祖国
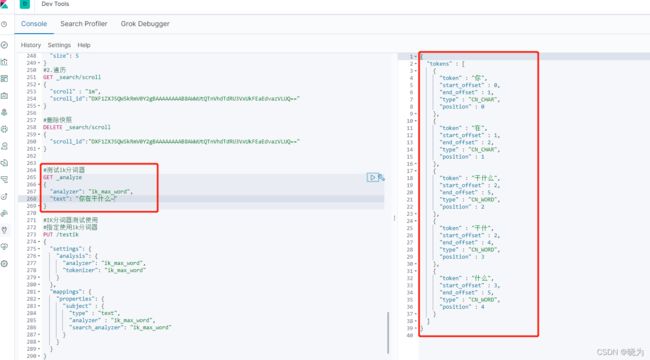
3.测试
#测试ik分词器
GET _analyze
{
"analyzer": "ik_max_word",
"text": "你在干什么~"
}
4.热词更新
注意:配置热词服务只需要一台服务器安装即可
对于ik分词来说我们使用的是已经分好的词库了。如果说有些网络上的热词,热梗或者某些行业的专业术语等等想要识别的话就需要更新词库。
更新词库又不想重启es的就配置热词更新
查看ik自带的词库:

可见词典都是.dic格式文件 而且每个词分为一行
配置热词服务器:
#进入目录
cd /data/es/elasticsearch-7.6.0/plugins/ik/config
#修改配置文件
vim IKAnalyzer.cfg.xml
#修改下面内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">自己的词典地址</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">自己的词典地址</entry>
</properties>
设置热词服务器:
下载上传解压tomcat。可自己下载亦可以用我得资源
#进入目录
cd /data/es/apache-tomcat-9.0.56/webapps/ROOT
#新建词典文件
vim hot.dic
#文件内容 可自行写入
蓝瘦香菇
黄河之水
#启动tomcat
cd /data/es/apache-tomcat-9.0.56/bin
sh startup.sh
访问页面:
http://ip:8080/hot.dic
如果是乱码也无所谓 只要hot.dic是utf8格式就可以
将http://ip:8080/hot.dic配置到上面的ik配置文件中即可
配置热词服务器:
#进入目录
cd /data/es/elasticsearch-7.6.0/plugins/ik/config
#修改配置文件
vim IKAnalyzer.cfg.xml
#修改下面内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://ip:8080/hot.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://ip:8080/hotstop.dic</entry>
</properties>
重启es
#停止
ps ‐ef|grep elasticsearch|grep bootstravelap |awk '{print $2}' |xargs kill ‐9
#启动
nohup /data/es/elasticsearch-7.6.0/bin/elasticsearch 2>&1 &
这样ES就会每隔1分钟去读取我们的远程词典来更新词库了
查看日志:

测试分词器:
#测试ik分词器
GET _analyze
{
"analyzer": "ik_max_word",
"text": "黄河之水天上来~"
}
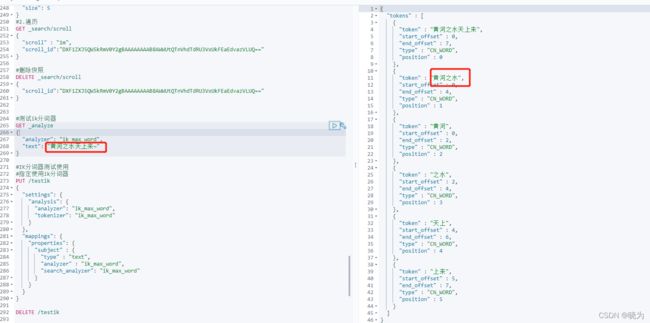
可以配置停止词典 停止词典配置上的话就不会再去分词停止词典中的词了
#######################################################
######################至此安装完成######################
#######################################################
四、ES的使用以及语法
下面均以ES7语法在kibana中来实现(其他的版本可以自己添加type):
ES一个很大的优势就是提供了rest api供用户操作数据
| HTTP | 用途 |
|---|---|
| PUT | 用于创建 |
| GET | 用于获取 |
| POST | 用于更新 有些查询可以和GET一样用 |
| Delete | 用于删除 |
基本语句
1.集群管理
_cat相关查看集群
比如aliases别名 health健康状态 nodes节点 indices索引等等
2.索引相关操作
索引相关操作 指定HTTP url中第一位就是索引 比如 PUT /索引名
#创建空索引
PUT /testindex
#创建索引指定mapping和setting
#mapping可以指定字段类型 setting可以设置分片副本
#text类型可分词模糊查询 keyword关键词查询
PUT /testindex
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"address":{"type":"text"},
"remark":{"type":"text"}
}
}
}
#删除索引
DELETE /testindex
#查看索引的setting
GET /testindex/_settings
#查看索引的mapping
GET /testindex/_mapping
3.文档数据相关操作
文档作为ES中存储的数据格式 我们对其进行相关增删改查操作
新增一条文档
#首先创建索引
PUT /testindex
#插入一条数据 指定文档id
PUT /testindex/_doc/1
{
"country": "中国",
"province": "北京",
"City": "北京",
"address1": "东长安街"
}
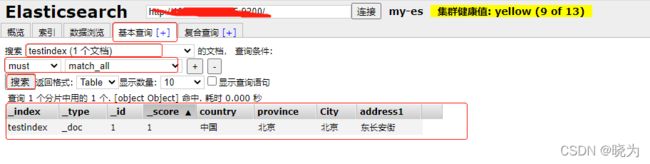
可以通过es-head插件来直观的查看插入的数据
流程为:基本查询 - 搜索创建的文档 - 选择方法 must match_all(自动的) --搜索
值显示为索引名称 type 文档唯一id 所得分数 之后就是我们插入的字段了
测试时可以获取所有(must match_all) 但是生产不可如此 可能会造成GC
查看es-head插件
#创建文档不指定id
#此时只能使用POST来创建
POST /testindex/_doc/
{
"country": "中国",
"province": "北京",
"City": "北京",
"address1": "东长安街"
}
查看es-head插件

可以看到ES自动生成了唯一id
#如果再次插入数据 与之前字段不同呢
#删除country字段 增加address2字段
PUT /testindex/_doc/2
{
"province": "中国",
"City": "北京",
"address1": "东长安街",
"address2": "西长安街"
}
查看es-head插件
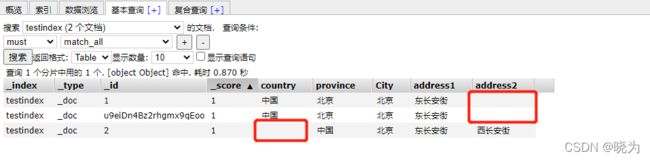
可见之前的字段被补充为空 之后创建新字段 之前的数据补充为空
生产一般先指定好字段和字段的类型
删除一条文档
#指定删除的文档id
DELETE /testindex/_doc/u9eiDn4Bz2rhgmx9qEoo
查看es-head插件
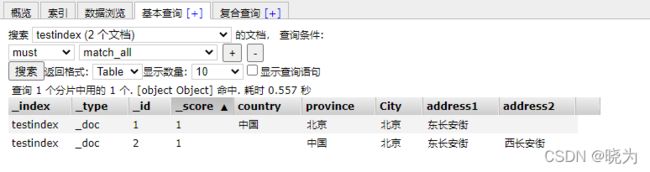
删除文档只是逻辑删除 不是直接在磁盘中删除
文档一条数据修改
#全量修改 指定id
#也可以用post
PUT /testindex/_doc/1
{
"country": "中国",
"province": "天津",
"City": "天津",
"address1": "开发区"
}
查看es-head插件

ES中同一id写入会覆盖这一条文档
#部分修改
#只能用post
POST /testindex/_update/2
{
"doc": {
"City":"北京海淀"
}
}
查看es-head插件
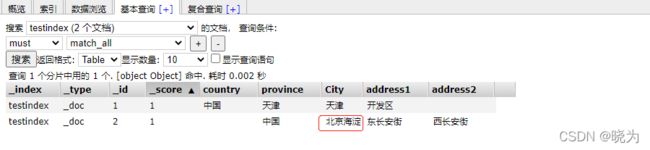
批量插入
#指定索引
POST /testindex/_bulk
{"index":{"_id":3}}
{"country": "中国","province": "北京","City": "丰台","address1": "体育馆"}
{"index":{"_id":4}}
{"country": "中国","province": "北京","City": "海淀","address1": "五棵松"}
查看es-head插件
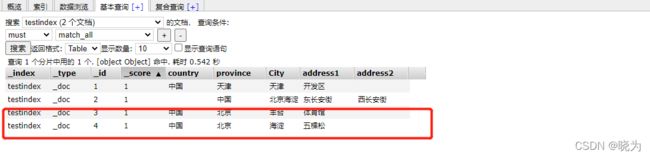
#在请求体中设置索引
POST _bulk
{"create":{"_index":"testindex","_id":5}}
{"country": "中国","province": "北京","City": "昌平","address1": "平西府"}
{"create":{"_index":"testindex","_id":6}}
{"country": "中国","province": "北京","City": "西城","address1": "西单"}
查看es-head插件
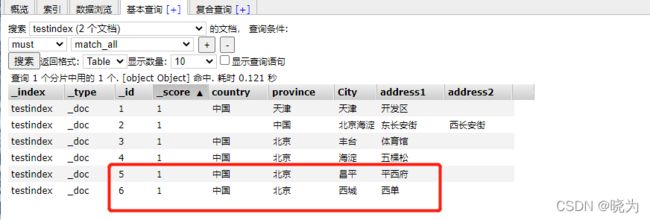
查询语句
查询返回值
| 返回值 | 解释 |
|---|---|
| Hits | 返回结果中最重要的部分是 hits ,它包含 total 字段来表示匹配到的文档总数,并且一个 hits 数组包含所查询结果前十个文档。在 hits 数组中每个结果包含文档的 _index 、 _type 、 _id ,加上 _source 字段。这意味着我们可以直接从返回的搜索结果中使用整个文档。这不像其他的搜索引擎,仅仅返回文档的ID,需要你单独去获取文档。每个结果还有一个_score ,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照 _score 降序排列的。如果我们没有指定任何查询,那么所有的文档具有相同的相关性,因此对所有的结果而言 1 是中性的 _score 。max_score 值是与查询所匹配文档的 _score 的最大值 |
| took | took 值告诉我们执行整个搜索请求耗费了多少毫秒 |
| Shard | _shards 部分 告诉我们在查询中参与分片的总数,以及这些分片成功了多少个失败了多少个。正常情况下我们不希望分片失败,但是分片失败是可能发生的。如果我们遭遇到一种灾难级别的故障,在这个故障中丢失了相同分片的原始数据和副本,那么对这个分片将没有可用副本来对搜索请求作出响应。假若这样,Elasticsearch 将报告这个分片是失败的,但是会继续返回剩余分片的结果。 |
| timeout | timed_out 值告诉我们查询是否超时。默认情况下,搜索请求不会超时。 如果低响应时间比完成结果更重要,你可以指定 timeout 为 10 或者 10ms(10毫秒),或者 1s(1秒):GET /_search?timeout=10ms在请求超时之前,Elasticsearch 将会返回已经成功从每个分片获取的结果。 |
1.基本查询
全量查询
#全量查询 get或者post
GET /testindex/_search
{
"query":{
"match_all":{}
}
}

主键查询
#指定文档id 查询数据
GET /testindex/_doc/1

2.花式查询
借助网上的一份数据来进行测试
#删除索引
DELETE /testindex
#新建索引
PUT /testindex
#批量插入数据
POST /testindex/_bulk
{"index": { "_id": 1 }}
{ "name" : "liubei", "age" : 20 , "sex": "boy", "birth": "1996-01-02" , "about": "i like diaocan he girl"}
{ "index": { "_id": 2 }}
{ "name" : "guanyu", "age" : 21 , "sex": "boy", "birth": "1995-01-02" , "about": "i like diaocan" }
{ "index": { "_id": 3 }}
{ "name" : "zhangfei", "age" : 18 , "sex": "boy", "birth": "1998-01-02" , "about": "i like travel" }
{ "index": { "_id": 4 }}
{ "name" : "diaocan", "age" : 20 , "sex": "girl", "birth": "1992-01-02" , "about": "i like travel and sport"}
{ "index": { "_id": 5 }}
{ "name" : "panjinlian", "age" : 25 , "sex": "girl", "birth": "1991-01-02" , "about": "i like travel and wusong"}
{ "index": { "_id": 6 }}
{ "name" : "caocao", "age" : 30 , "sex": "boy", "birth": "1988-01-02" , "about": "i like xiaoqiao" }
{ "index": { "_id": 7 }}
{ "name" : "zhaoyun", "age" : 31 , "sex": "boy", "birth": "1997-01-02" , "about": "i like travel and music" }
{ "index": { "_id": 8 }}
{ "name" : "xiaoqiao", "age" : 18 , "sex": "girl", "birth": "1998-01-02" , "about": "i like caocao" }
{ "index": { "_id": 9 }}
{ "name" : "daqiao", "age" : 20 , "sex": "girl", "birth": "1996-01-02" , "about": "i like travel and history"}
{ "index": { "_id": 10 }}
{ "name" : "zhuge", "age" : 20 , "sex": "boy", "birth": "1996-01-02" , "about": "i like travel and history"}
{ "index": { "_id": 11 }}
{ "name" : "gaunyu", "age" : 20 , "sex": "boy", "birth": "1993-01-02" , "about": "i like travel and chunqiu"}
查看:
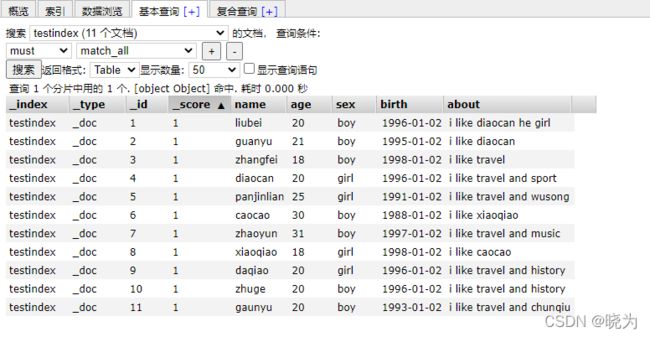
通过关键词查询
通过match匹配
查询喜欢夜读春秋的人
#match 关键词搜索
GET /testindex/_search
{
"query": {
"match": {
"about": "chunqiu"
}
}
}

复合查询
当出现多个查询语句组合的时候,可以用bool来包含。bool合并聚包含:must,must_not或者should,
should表示or的意思
查询喜欢旅游并且不读春秋的人
#bool 复合查询
## must为必须 must_not 为必须不 should 为或者
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"match": {
"about": "travel"
}}
],
"must_not": [
{"match": {
"about": "chunqiu"
}}
]
}
}
}
精准匹配
通过上面的match来匹配是经过分词后匹配
精确匹配用于精确的过滤
比如输入 ”我爱你”
在match下面匹配可以为包含:我、爱、你、我爱等等的解析器
在term语法下面就精准匹配到:”我爱你”
#term 精准匹配 term 匹配一个 terms匹配多个
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"terms": {
"about": [
"travel",
"sport"
]
}}
]
}
}
}
范围匹配
Range过滤允许我们按照指定的范围查找一些数据:操作范围:gt::大于,gae::大于等于,lt::小于,lte::小于等于
查找出大于20岁, 小于等于25岁的学生
#range过滤 gt::大于,gte::大于等于,lt::小于,lte::小于等 于
GET /testindex/_search
{
"query": {
"range": {
"age": {
"gt": 20,
"lte": 25
}
}
}
}
exists和missing过滤
exists 和missing过滤可以找到文档中是否包含某个字段或者没有某个字段的数据
#exists和missing过滤 exists 存在 missing 不存在 此处判断是字段存在不存在 而不是字段的值
GET /testindex/_search
{
"query": {
"exists": {
"field": "age"
}
}
}
filter 过滤
filter过滤可以过滤字段的值
#filter 过滤
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"match": {
"about": "travel"
}}
],
"filter": {"term": {
"age": "20"
}}
}
}
}
分页查询
分页查询分为size+from浅分页和size+from浅分页
#size+from浅分页
#from定义了目标数据的偏移量, size定义当前返回的事件数目
GET /testindex/_search
{
"query": {
"match_all": {}
},
"from": 5,
"size": 20
}
这种浅分页只适合少量数据,因为随from增大,查询的时间就会越大,而且数据量越大,查询的效率指数下降
#scroll深分页 scroll就是维护了当前索引段的一份快照信息--缓存
#两步 1.生成快照 2.遍历快照
#?scroll=3m 设置缓存的过期时间
#1.生成快照
GET /testindex/_search?scroll=3m
{
"query": {
"match_all": {}
},
"size": 5
}
#2.遍历
GET _search/scroll
{
"scroll" : "1m",
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAiPcWWUtQTnVhdTdRU3VxUkFEaEdvazVLUQ=="
}
#删除快照
DELETE _search/scroll
{
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAiPcWWUtQTnVhdTdRU3VxUkFEaEdvazVLUQ=="
}
查询排序
排序语句 相当于sql的order by
#多条件查询 sort语句与query语句平级 相当于sql中查询出数据再排序
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"term": {
"about": {
"value": "travel"
}
}},
{"range": {
"age": {
"gte": 20,
"lte": 30
}
}}
]
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
3.聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值max、平均值avg等等。
返回结果会附带原始数据的。若不想要不附带原始数据的结果。可以使用size关键字。
基本概念
#聚合查询
#聚合查询在es中的字段应该是keyword类型
#聚合查询就是相当于sql的分组聚合
#有两个概念 一个是桶(分组group by) 一个是指标(聚合指标 sum/count/max/min)
#下面语句中 query:可以先查询再聚合函数
#aggs:聚合命令
#NAME:聚合的名字 用户自定义
#AGG_TYPE:聚合类型,代表我们想要怎么统计数据。主要有两大类的聚合类型:桶聚合和指标聚合
#AGG_TYPE{}:聚合的一些参数 也可以聚合函数内部再聚合 比如下面的aggs1和aggs2
#也可以一个查询多个聚合 比如下面的NAME1和NAME2
#size=0代表不需要返回query查询结果,仅仅返回aggs统计结果
GET /testindex/_search
{
"query": {},
"aggs": {
"NAME": {
"AGG_TYPE": {}
,"aggs2": {
"NAME": {
"AGG_TYPE": {}
}
}},
"NAME2": {
"AGG_TYPE": {}
}
},
"size": 0
}
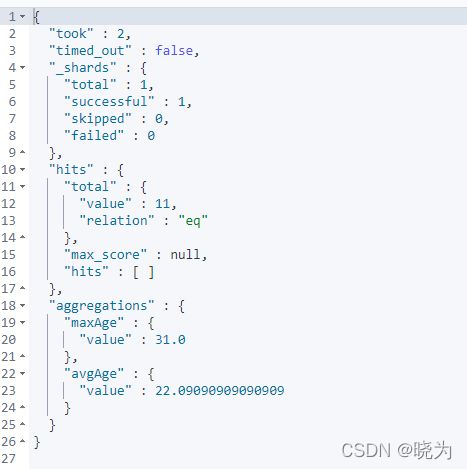
指标聚合
#指标聚合
#value count:统计总数;
#Cardinality:类似SQL的count(DISTINCT 字段)
#sum:求和
#max:最大值
#min:最小值
#avg: 平均值
GET /testindex/_search
{
"aggs": {
"avgAge": {
"avg": {
"field": "age"
}
},
"maxAge": {
"max": {
"field": "age"
}
}
},
"size": 0
}
结果:
分组聚合
#分组聚合
#terms:类似sql的group by;
#Histogram(柱状图, [ˈhɪstəɡræm])聚合:根据数组间隔分组,例如:价格100间隔分组,0,100,200等等;
#Date histogram聚合:根据时间间隔分组,例如:按月、天、小时分组;
#Range:按数值范围,例如0-150、150-200一组,200-500一组。
#桶聚合一般不单独使用,都是配合指标聚合一起使用,对数据分组之后肯定要统计桶内数据,在ES中如果没有明确指定指标聚合,默认使用Value Count指标聚合,统计桶内文档总数
GET /testindex/_search
{
"aggs": {
"termsTest": {
"terms": {
"field": "sex",
"size": 10
}
}
},
"size": 0
}
结果:
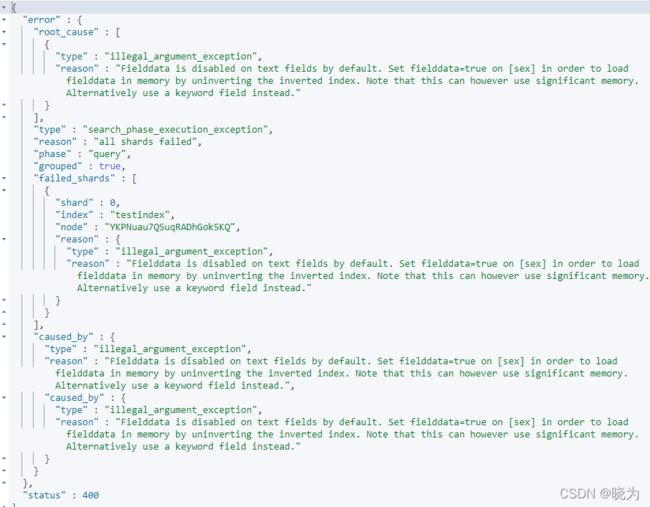
产生报错 这是因为当时写入索引时es时动态识别数据类型的 ES将数据识别为了text
而在ES中索引建立后字段类型就不可更改了
一种办法:用 sex.keyword 或者指定filedata 但是filedata太吃资源 所以不考虑
另一种办法:重建索引指定字段为keyword同步数据
在这里使用第二种办法:
同步数据
#新建索引
#指定时间字段以及keyword字段
PUT /testindex2
{
"mappings" : {
"properties" : {
"about" : {
"type" : "text"
},
"age" : {
"type" : "long"
},
"birth" : {
"type" : "date",
"format": "yyyy-MM-dd"
},
"name" : {
"type" : "text"
},
"sex" : {
"type" : "keyword"
}
}
}
}
#查看索引
GET /testindex2/_mapping
#同步数据
POST _reindex
{
"source": {"index": "testindex"},
"dest": {"index": "testindex2"}
}
结果:

数据已经同步过来了
继续测试分组聚合数据
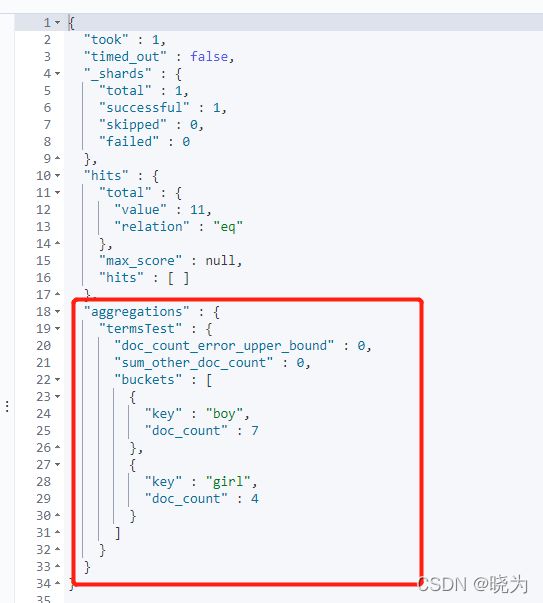
terms
#terms
GET /testindex2/_search
{
"aggs": {
"termsTest": {
"terms": {
"field": "sex"
}
}
},
"size": 0
}
histogram
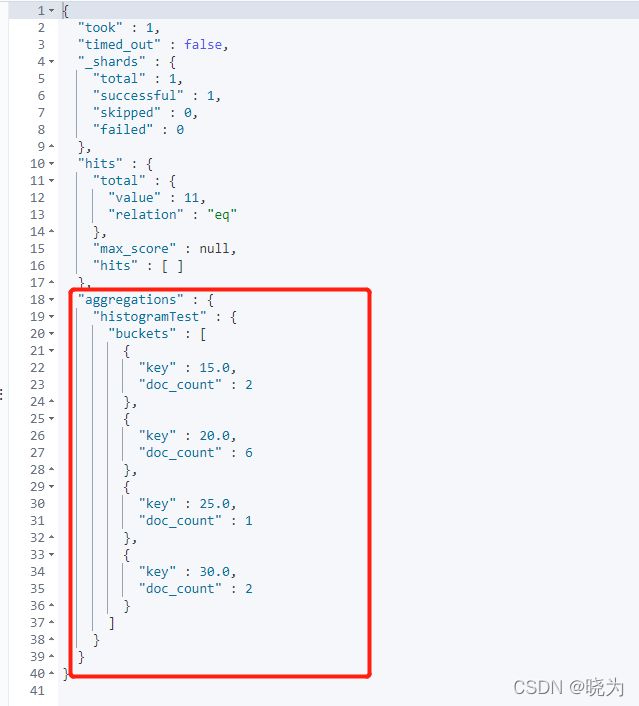
#Histogram
GET /testindex2/_search
{
"aggs": {
"histogramTest": {
"histogram": {
"field": "age",
"interval": 5
}
}
},
"size": 0
}
date_histogram
#Date Histogram
GET /testindex2/_search
{
"aggs": {
"dateHisTest": {
"date_histogram": {
"field": "birth",
"interval": "year"
}
}
},
"size": 0
}

Range
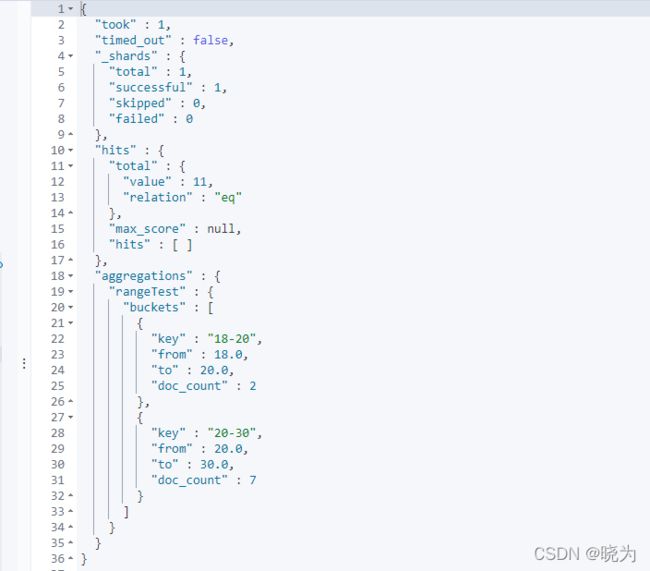
#Range
#可以通过key值来指定区间 自定义的 方便后续查找
GET /testindex2/_search
{
"aggs": {
"rangeTest": {
"range": {
"field": "age",
"ranges": [
{
"key": "18-20",
"from": 18,"to": 20
},
{
"key": "20-30",
"from": 20,"to": 30
}
]
}
}
},
"size": 0
}
结合使用
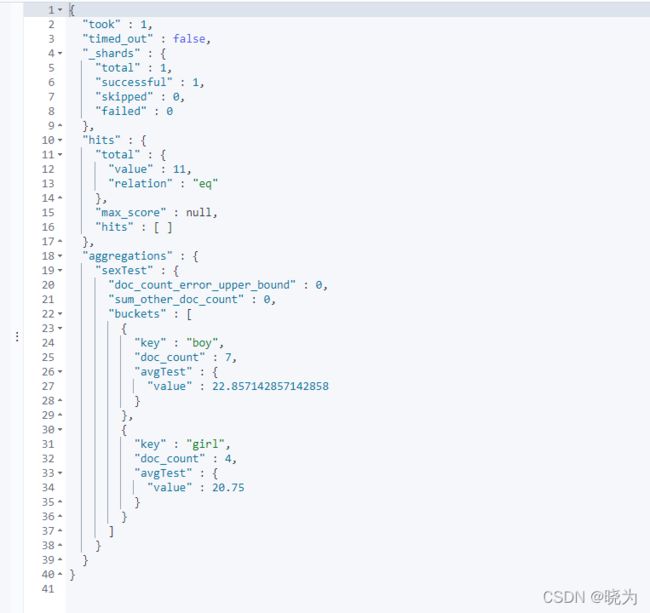
#测试
#根据性别分组 查询每个组内的平均年龄
GET /testindex2/_search
{
"size": 0,
"aggs": {
"sexTest": {
"terms": {
"field": "sex"
},
"aggs": {
"avgTest": {
"avg": {
"field": "age"
}
}
}
}
}
}
全文检索以及短语匹配和多字段匹配
数据准备
#新建索引
PUT /testindex3
#删除索引
DELETE /testindex3
#批量插入
POST /testindex3/_bulk
{"index": { "_id": 1 }}
{"desc1":"a","desc2":"c"}
{"index": { "_id": 2 }}
{"desc1":"b","desc2":"a"}
{"index": { "_id": 3 }}
{"desc1":"c","desc2":"b"}
{"index": { "_id": 4 }}
{"desc1":"a b c","desc2":"a d"}
{"index": { "_id": 5 }}
{"desc1":"b c d","desc2":" a c"}
{"index": { "_id": 6 }}
{"desc1":"a c e","desc2":"d"}
{"index": { "_id": 7 }}
{"desc1":"d f g ","desc2":"a b c"}
{"index": { "_id": 8 }}
{"desc1":"c a","desc2":" c d"}
1.minimum_should_match
最低匹配
含义为最低匹配几个词
传入的参数
数字 正整数或者负数 正整数表示至少匹配几个词 负数表示最多不匹配的个数 比如 2,-2
百分比 至少匹配词的百分比 和数字一样 可以是正的也可以是负的 比如 50%, -50%
也可以混用
数字参数
#数字
GET /testindex2/_search
{
"query": {
"match": {
"about": {
"query": "i,like,and",
"minimum_should_match": 2
}
}
}
}
百分比
#百分比
GET /testindex2/_search
{
"query": {
"match": {
"about": {
"query": "i,like,and",
"minimum_should_match": "40%"
}
}
}
}
组合使用
#组合
#组合的格式为 数字<百分比 逻辑为如果给出的词分词个数小于等于数字时用数字 否则用百分比
#也可以理解为三元表达式格式 (给定查询词分词个数 <= 给出的数字参数)? 给出的参数数字:给出的百分比
#多个组合格式的话时串联执行的
GET /testindex2/_search
{
"query": {
"match": {
"about": {
"query": "i,like,and",
"minimum_should_match": "3<40% 2<-10%"
}
}
}
}
2.match_phrase
match_phrase搜索的数据类型为text类型,会将查询条件进行分词,但要求待匹配的文档需要同时包含分词后的数据。并且顺序一致 可以理解为term精准匹配的功能
这种搜索性能不高 因为要计算分词的位置信息
GET /testindex2/_search
{
"query": {
"match_phrase": {
"about": {
"query": "i like aaa",
"slop": 0
}
}
}
}
3.多字段匹配
#使用multi_match可以查询多个字段的数据 相当于写多个match并用dis_max包裹一样或者bool的符合查询。这两种在花式查询中有测试。现在使用这个单独多字段查询的api
最重要的一点是能为查询字段的分数设置权重
设置权重可以用 ^ 权重来设置 比如 : about^3 表示about字段的权重是3倍
multi_match常用的类型为:
| 类型 | 说明 |
|---|---|
| best_fields | (默认)查找与任何字段匹配的文档,使用最佳字段的权重 |
| most_fields | 查找与任何字段匹配的文档,并组合每个字段的权重 |
| cross_fields | 使用相同的分析仪处理字段,就像它们是一个大字段。 在任何字段中查找每个字词 |
| phrase | 对每个字段运行match_phrase查询,并合并每个字段的权重 不推荐 |
best_fields
best_fields类型使用单个最佳匹配字段的分数
如果tie_breaker指定了该分数,则按照以下方式计算score:单个最佳匹配字段的分数+(tie_breaker*其他所有匹配字段的score)
operator则是指定分词是否都匹配的关系
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2"],
"type": "best_fields",
"tie_breaker": 0
}
}
}
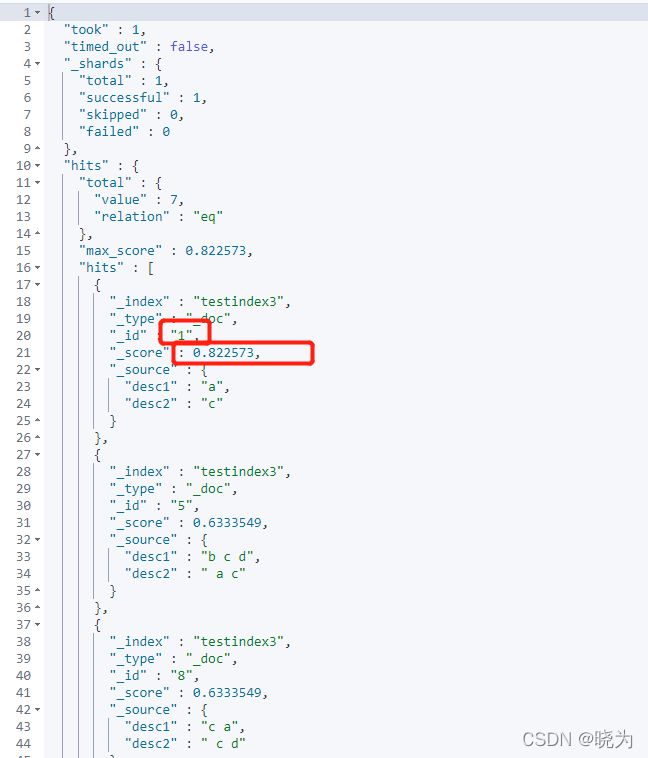
提升权重:
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2^3"],
"type": "best_fields",
"tie_breaker": 0
}
}
}
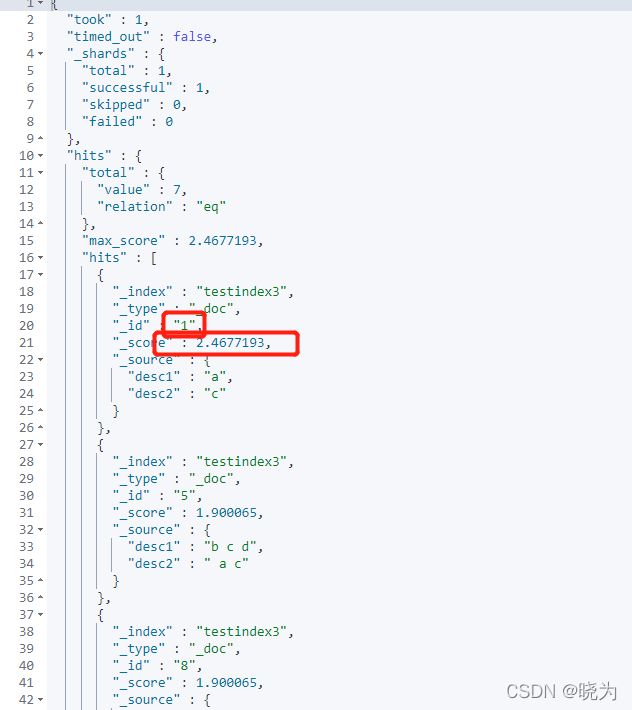
可见分数已经不同
most_fields
查找与任何字段匹配的文档,并组合每个字段的权重
为了与best_filed类型区分 给出两个api对比结果
看结果score的排序可区分两种类型 由于设计的数据不完善 所以most_files中给desc2两倍的权重来查看区别
如果都为best_fields类型就算增加权重 排序结果也不会变 所以增加most_fields的权重如果排序结果变化的话就可以表明问题
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2"],
"type": "best_fields",
"tie_breaker": 0
}
}
}
#most_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2^2"],
"type": "most_fields",
"tie_breaker": 0
}
}
}
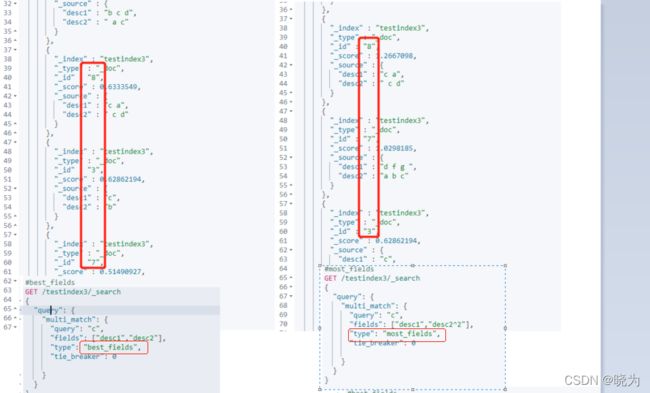
cross_fields
为了让 cross_fields 查询以最优方式工作,所有的字段都须使用相同的分析器,具有相同分析器的字段会被分组在一起作为混合字段使用。
best_fields和most_fields是字段中心式查询
cross_fields 是词中心式查询
明显区别是如果设定opreation为and 那么字段中心式两个词必须都在字段中才行 词中心式两个词可以在任何一个字段中
为了与以字段为中心的对比 使用best_fileds类型与之比对
#cross_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c a",
"fields": ["desc1","desc2"],
"type": "cross_fields",
"tie_breaker": 0,
"operator": "and"
}
}
}
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c a",
"fields": ["desc1","desc2"],
"type": "best_fields",
"tie_breaker": 0,
"operator": "and"
}
}
}
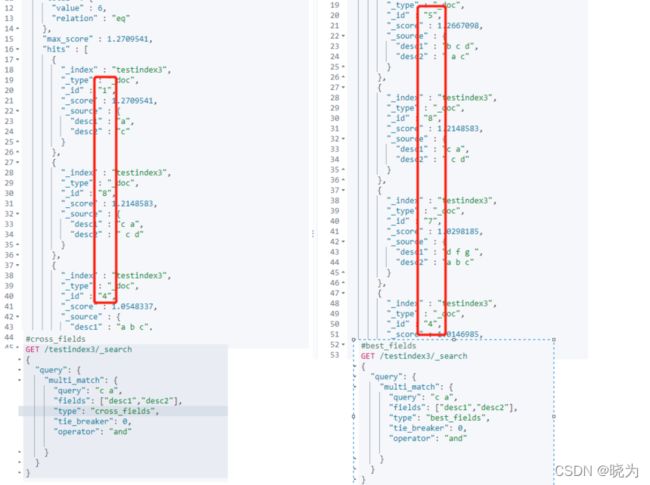
五、关于相关性算法的理解
ES 5.0 之前,默认的相关性算分采用的是 TF-IDF,而之后则默认采用 BM25。
TF-IDF算法
TF:词频(分词在整个文档的次数占比 如果文档总共有100个词 其中a词有10个 那么a的词频就是 10/100=1/10)
IDF:逆向文档频率 理解为包含词的索引数量在一个索引中所有文档数量中的占比 表示这个词在整个索引中的重要性
占比越多的话表示这个词越常见 这个词的重要性就越低 也就是权重就越低
算法为 ln(索引中所有文档数量/包含词语a的文档数量+1) 如果索引中包含文档100个 其中包含a词的文档9个 那么a词的IDF=ln(100/11)=ln10
公式中+1主要为了防止分母为0
而TF/IDF算法也就是 TFIDF 也就是单词a的词频单词a在文档中的权重来表示单词a的文档相关性
现在这种算法有了弊端 那就是如果IDF不变的情况下 词频无限制的增长 那么分数就会无限制增长 最后就是哪个文档中词频高的影响会越来越大
下面是TF/IDF算法和BM25算法的相关度趋势图 可以看出在之后BM25算法趋近平稳

BM25算法
BM25算法是 Best Matching的意思
算法做了一些优化 增加了k1和b两个可调参数
根据Kibana工具调试进行理解:
使用**“explain”: true**来获取相关评分解释
GET /unstructured_retrieval/_search
{
"query": {
"bool": {
"must": [
{"term": {
...
}
}},
{"multi_match": {
...
}}
],
"should": [
{"multi_match": {
...
}}
]
}
},
"explain": true,
"size": 1
}
得到其中一部分:
"value" : 12.527857,
"description" : "sum of:",
"details" : [
{
"value" : 12.527857,
"description" : "sum of:",
"details" : [
{
"value" : 2.3420286,
"description" : "weight(structureInfoDesc:张 in 58849) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 2.3420286,
"description" : "score(freq=3.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 2.0948625,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 127352,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 1034652,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.50817585,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 3.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 1688.0,
"description" : "dl, length of field (approximate)",
"details" : [ ]
},
{
"value" : 583.52924,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
...
可以看到是各个分词评分的sum of来计算最终评分,每个词的评分计算为score(freq=3.0), computed as boost * idf * tf from:
其中boost不知道怎么计算的。
而IDF的计算公式为:idf, computed as log(1 + (N - n + 0.5) / (n + 0.5))
这个对于TF/IDF算法来说更加细腻了 但还是对数值
而TF:tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl))
为什么BM25的曲线更柔和的原因就在这里了
freq是词出现的次数,我们可以将k1 * (1 - b + b * dl / avgdl) 简化为一个常数b
那么tf的公式变为:
freq /(freq+b) 这种函数的图像如下:
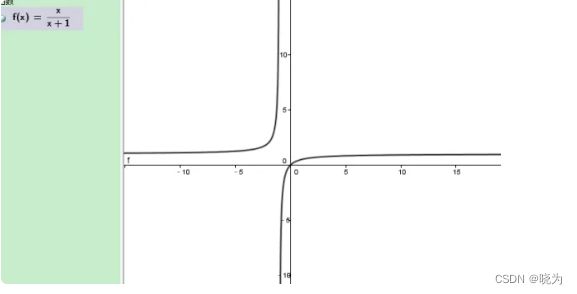
可以大概算下 b是大于0的 所以是一象限的图形
上图可以看出:当freq越大 那么曲线越平滑
下面探讨ES给出的可调参数k1和b的作用
dl是文档的长度,avdl是文档的平均长度,
k1和b是调整参数,b为0时即不考虑文档长度的影响,经验表明b=0.75左右效果比较好。但是也要根据相应的场景进行调整。b越大对文档长度的惩罚越大,k1因子用于调整词频,极限情况下k1=0,则第二部分退化成1,及词频特征失效,可以证明k1越大词频的作用越大。