文档级关系抽取方法总结
文章目录
- 1 文档级关系抽取
-
- 1.1 将关系抽取由句子级扩展到文档级的原因
- 1.2 文档级关系抽取数据集DocRED
- 2 图神经网络
-
- 2.1 图网络结构的分类
- 2.2 GCN
- 3 文档级关系抽取论文总结
-
- GP-GNN
- GraphRel
- GCNN
- EoG
- LSR
- DyGIE/DyGIE++
1 文档级关系抽取
1.1 将关系抽取由句子级扩展到文档级的原因
目前大多数关系抽取方法抽取单个实体对在某个句子内反映的关系,在实践中受到不可避免的限制:在真实场景中,大量的关系事实是以多个句子表达的。文档中的多个实体之间,往往存在复杂的相互关系。
以下图为例,就包括了文章中的两个关系事实(这是从文档标注的19个关系事实中采样得到的),其中涉及这些关系事实的命名实体用蓝色着色,其它命名实体用下划线标出。为了识别关系事实(Riddarhuset,country,Sweden),必须首先从句子4中抽取Riddarhuset位于Stockholm的关系事实,然后从句子1确定Stockholm是Sweden的首都,以及Sweden是一个国家,最后从这些事实推断出Riddarhuset的主权国家是瑞典。

该过程需要对文档中的多个句子进行阅读和推理,这显然超出了句子级关系抽取方法的能力范围。根据从维基百科采样的人工标注数据的统计表明,至少40%的实体关系事实只能从多个句子联合获取。因此,有必要将关系抽取从句子级别推进到文档级别。
1.2 文档级关系抽取数据集DocRED
19年的ACL上提出了一个关系抽取数据集DocRED,为文档级关系抽取的研究提供了一个非常好的标注数据集,今年的ACL上,就有论文使用DocRED作为语料,提出了文档级关系抽取的模型。
DocRED包含对超过5000篇Wikipedia文章的标注,包括96种关系类型、143,375个实体和56,354个关系事实。这在规模上超越了以往的同类精标注数据集。与传统的基于单句的关系抽取数据集相比,不同之处在于,DocRED中超过40%的关系事实只能从多个句子中联合抽取,因此需要模型具备较强的获取和综合文章中信息的能力,尤其是抽取跨句关系的能力。
2 图神经网络
相比较传统的CNN和RNN,图神经网络能够更好地在文档层面上建立实体之间的联系,从而实现文档级的关系推理。因此在解决文档级实体关系抽取任务中,图神经网络的主流的方法。
2.1 图网络结构的分类
在使用图神经网络时,图的构造是关键的一个环节,根据是否需要区分图中边的类型,可以将图分为异质图和同质图。
- 异质网络图
这种图定义了不同类型的边,边的表示方式因类型不同而有所区别,主要的代表工作是GCNN、EOG。 - 同质网络图 (latent structure)
把所有的边当作同质关系进行处理,利用attention或者其他的方式自动进行区分,主要的代表是LSR。
2.2 GCN
图卷积神经网络是一个很好地在图结构上进行特征抽取的神经网络模型,在图网络上进行卷积,简单的说就是是用=邻接节点的特征,更新节点自己的向量表达,达到特征传递的目的。使用GCN时,首先构建一个无向图,然后计算图的邻接矩阵 A i j A_{ij} Aij,下面是GCN的一般形式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dy6n5JR2-1595207598707)(C:\Users\IceBurg\Desktop\文档\例会\7.14\LSR10.PNG)]](http://img.e-com-net.com/image/info8/3cd24da3c9124e3cbd5b7fe3e262c66b.jpg) 这里需要注意的是GCN只能在同质网络图上使用,即不区分边的类型,所有的边在进行特征传递时进行相同的处理。而且上面的GCN一般形式只能在无向图中使用,如果是有向图,则需要针对问题进行调整。
这里需要注意的是GCN只能在同质网络图上使用,即不区分边的类型,所有的边在进行特征传递时进行相同的处理。而且上面的GCN一般形式只能在无向图中使用,如果是有向图,则需要针对问题进行调整。
GCN每次卷积过程中,节点通过跟自己相连接的节点的向量表示更新自己的向量表达。下图展示了GCN的卷积过程,第一次卷积操作过后节点使用一阶邻接节点的特征更新自己的状态
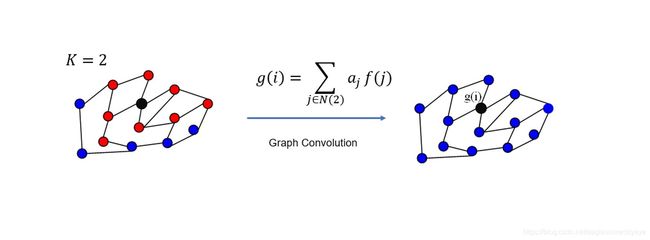
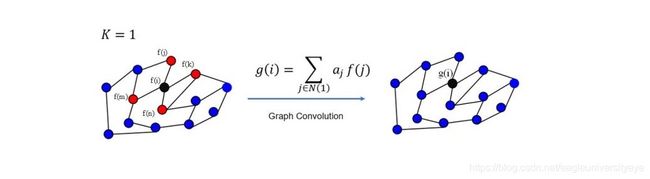 第二次卷积操作过后节点使用到了二阶邻接节点的特征
第二次卷积操作过后节点使用到了二阶邻接节点的特征
3 文档级关系抽取论文总结
GP-GNN
论文:Graph Neural Networks with Generated Parameters for Relation Extraction
GP-GNN主要解决的是句子级的长距离关系推理。GP-GNN首先用文本序列中的实体构造一个全连接的同质网络图,不区分边的类型,通过编码的方式让模型自动学习边的参数(这也是为什么模型叫做生成参数的GNN的原因)。图构建完成之后使用三个模块来处理关系推理:
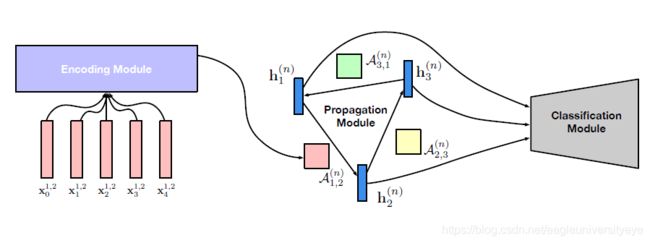
编码模块:
该模块的输入是 E ( x t i , j ) = [ x t ; p t i , j ] E(x^{i,j}_t) = [x_t;p^{i,j}_t] E(xti,j)=[xt;pti,j],其中 x t x_t xt是单词t的词向量, p t i , j p^{i,j}_t pti,j表示单词t与一个实体对的相对位置向量,单词t相对于实体对1,2的位置向量为 p t 1 , 2 p^{1,2}_t pt1,2。编码模块最终得到一个向量 A i , j ( n ) A^{(n)}_{i,j} Ai,j(n) 作为图中边的参数:
A i , j ( n ) = [ M L P n ( B i L S T M n ( ( E ( x 0 i , j ) , E ( x 1 i , j ) , . . . , E ( x l i , j − 1 ) ) ] A^{(n)}_{i,j}=[MLP_n(BiLSTM_n((E(x^{i,j}_0),E(x^{i,j}_1),...,E(x^{i,j}_l-1))] Ai,j(n)=[MLPn(BiLSTMn((E(x0i,j),E(x1i,j),...,E(xli,j−1))]
传播模块:
使用GCN,在各个节点之间传播关系信息,其中 N ( v i ) N(v_i) N(vi)表示图G中节点 v i v_i vi的邻接节点。
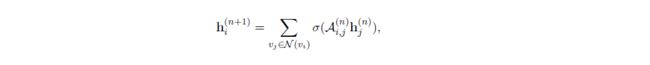 分类模块:
分类模块:
首先构建两个节点之间的关系表示 r v i , v j r_{{v_i},{v_j}} rvi,vj,其中K表示传播模块的层数。
r v i , v j = [ [ h v i ( 1 ) ] ⊙ [ h v j ( 1 ) ] ; [ h v i ( 2 ) ] ⊙ [ h v j ( 2 ) ] ; . . . ; [ h v i ( K ) ] ⊙ [ h v j ( K ) ] ; ] r_{{v_i},{v_j}}=[[h^{(1)}_{v_i}]⊙[h^{(1)}_{v_j}];[h^{(2)}_{v_i}]⊙[h^{(2)}_{v_j}];...;[h^{(K)}_{v_i}]⊙[h^{(K)}_{v_j}];] rvi,vj=[[hvi(1)]⊙[hvj(1)];[hvi(2)]⊙[hvj(2)];...;[hvi(K)]⊙[hvj(K)];]
然后使用 r v i , v j r_{{v_i},{v_j}} rvi,vj进行关系分类
P ( r v i , v j ∣ h , t , s ) = s o f t m a x ( M L P ( r v i , v j ) ) P(r_{{v_i},{v_j}}|h,t,s) = softmax(MLP(r_{{v_i},{v_j}})) P(rvi,vj∣h,t,s)=softmax(MLP(rvi,vj))
GraphRel
论文:GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction
GraphRel是一个实体关系抽取联合模型,总体架构图下图所示,包含2个阶段。
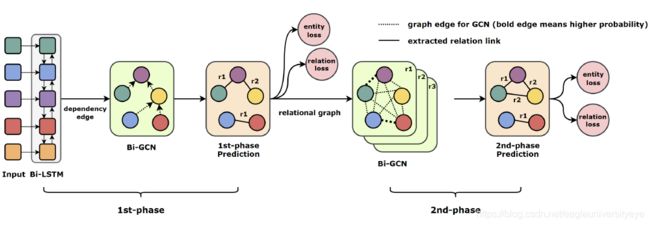
第1阶段,首先使用Bi-LSTM对文本输入进行编码,然后构建句子的依存关系树,以Bi-LSTM的编码结果作为输入使用Bi-GCN捕捉依存关系信息。之后利用Bi-GCN的结果,进行第一次实体和关系预测,得到第一阶段的entity loss和relation loss,计算实体间关系的公式如下,其中 W r 1 , W r 2 , W r 3 W_r^1,W_r^2,W_r^3 Wr1,Wr2,Wr3是可训练的参数, h w 1 , h w 2 h_{w1},h_{w2} hw1,hw2是两实体的向量,计算每一对实体的关系得分 S S S
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GJsjs8rq-1595204837811)(C:\Users\IceBurg\Desktop\文档\例会\7.14\GraphRel4.png)]](http://img.e-com-net.com/image/info8/30f7ab6496204329a597e2609b013fb5.jpg) 第2阶段,为第一阶段结束后,得到了初步的实体和实体间关系,第二阶段以第一阶段预测的实体作为节点,为每种关系建立一个全连接关系图,使用GCN使实体信息充分的交互,然后利用GCN处理过的全连接关系图预测实体之间该关系的概率。这一阶段也得到一个entity loss和relation loss,与第一阶段的entity loss和relation loss相加作为总的loss进行训练
第2阶段,为第一阶段结束后,得到了初步的实体和实体间关系,第二阶段以第一阶段预测的实体作为节点,为每种关系建立一个全连接关系图,使用GCN使实体信息充分的交互,然后利用GCN处理过的全连接关系图预测实体之间该关系的概率。这一阶段也得到一个entity loss和relation loss,与第一阶段的entity loss和relation loss相加作为总的loss进行训练
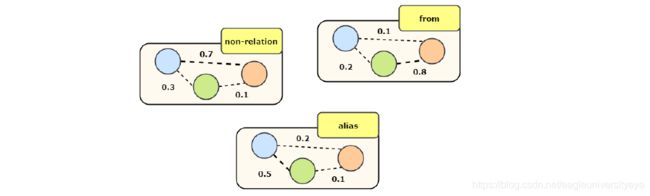
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eZPumLmf-1595204837814)(C:\Users\IceBurg\Desktop\文档\例会\7.14\GraphRel3.png)]](http://img.e-com-net.com/image/info8/7e05efd3016742cd8c7961c673ada5b2.jpg) 如下图所示,经过第一阶段的预测得到三个实体,一种有三种关系类型,分别是form、alias、non-relation。为三种关系类型构建三个全连接图,以预测每对实体之间的关系。
如下图所示,经过第一阶段的预测得到三个实体,一种有三种关系类型,分别是form、alias、non-relation。为三种关系类型构建三个全连接图,以预测每对实体之间的关系。
GCNN
论文:Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network
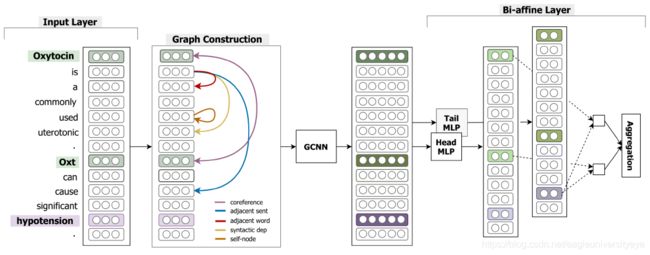
文档的句子之间存在不同的关联,比如共指关系,语义依存关系等。GCNN为不同的关联类型,建立不同的图单独进行图卷积操作,然后将各图的结果相加,达到同时使用多种关联特征的效果。
GCNN一共使用到了5种类型的关联,不同的关联类型构造不同的边,所以GCNN构建的图一共有5种边。由于边的类型不同,所以GCNN构建的图属于异质网络图 。
- Syntactic dependency edge 使用句子内的依存语法树,每种依存关系作为一种类型的边
- Coreference edge 共指边,代表两个指称描述同一个实体
- Adjacent sentence edge 将相邻句子的依存语法树根节点连接构成一种类型的边
- Adjacent word edge 指向相邻单词的边
- Self-node edge 自反边,指向自己的边
GCNN使用的GCN和普通的GCN有一些不同,它只交互一阶相邻节点的信息,并且有K个块,每个块针对一种边进行卷积操作,最后将各个块的结果累加。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GKv4qCAT-1595204837819)(C:\Users\IceBurg\Desktop\文档\例会\7.14\GCNN1.PNG)]](http://img.e-com-net.com/image/info8/0dc141ab25134a3b88092a6814f459ef.jpg)
GCNN的整个处理过程其实可以看作是用5种关联类型构建了5个图,分别进行图卷积操作,然后将5个图的结果累加。这样做的原因是不同的关联类型代表的含义是不同的,必须加以区分。GCNN最大的亮点就在这里,通过分层巧妙的使用了多种关联关系。
得到节点的表示后使用多示例学习,将上一步得到的结果映射为两个值,这一步的操作和下一步紧密相关,两个值分别用于计算节点是头实体和尾实体时节点间的关系概率。这里多示例学习的原理类似Transformer中的多头注意力,为了捕捉更多样的特征。以关系分类的角度这样做也很合理,因为关系三元组是有向的,节点作为主体和客体时使用的特征也应该不同。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ioHnKCpZ-1595204837820)(C:\Users\IceBurg\Desktop\文档\例会\7.14\GCNN2.PNG)]](http://img.e-com-net.com/image/info8/827cac673b624cb588dc59ba2eb78e21.jpg) 最后将两个通过多示例学习得到的值作为输入,计算两节点间的关系类型
最后将两个通过多示例学习得到的值作为输入,计算两节点间的关系类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X2XVnkTI-1595204837823)(C:\Users\IceBurg\Desktop\文档\例会\7.14\GCNN3.PNG)]](http://img.e-com-net.com/image/info8/2598e5fb769144d1ac77fbeafd5aba72.jpg)
EoG
论文:Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs
现有的方法使用基于图神经网络的模型,以实体作为节点,边代表实体之间的关系。这些模型是基于节点的,也就是说,它们仅根据两个目标节点来确定实体间的关系。然而,实体间的边在图神经网络的信息过程中也非常重要,EoG在不同种类节点之间,建立不同类型的边来决定信息流入节点的多少,可以更好的拟合文档之间异构的交互关系。
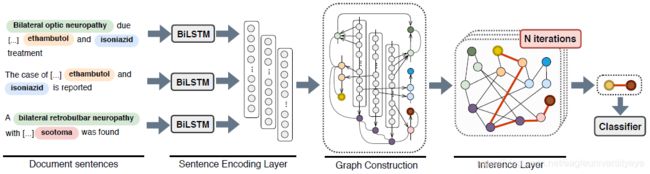
EoG中的节点分为三类:
- 提及节点M:实体提及(Entity mention),表示输入文档中实体的不同提及,包括实体的简称,指代词等等。提及节点的编码采用实体提及词向量的hidden。
- 实体节点E:实体节点代表独特的实体概念。实体节点的编码采用实体的所有提及向量的平均值。
- 句子节点S:句子节点对应句子。句子节点表示为句子中所有单词表示的平均值。
EoG中有三种类型的节点,所以不同节点间相连接就有6种不同类型的边(不考虑边的指向),分别是MM、ME、MS、ES、SS、EE。其中ME、MS、ES三种边的表达采用两节点向量的拼接,MM边则融入了距离信息和上下文信息,SS边也融入了句子间的距离向量。
-
ME:如果提及M与实体E关联,则将提及节点连接到实体节点。ME边的表示为 x M E = [ n m ; n e ] x_{ME}=[n_m;n_e] xME=[nm;ne]
-
MS:当提及M位于句子S中时,将提及节点连接到句子节点。MS边的表示为 x M S = [ n m ; n s ] x_{MS}=[n_m;n_s] xMS=[nm;ns]
-
ES:当实体E位于句子S中时,将实体节点连接到句子节点。ES边的表示为 x E S = [ n e ; n s ] x_{ES}=[n_e;n_s] xES=[ne;ns]
-
MM:提及节点到提及节点之间的边构建要稍微复杂一点,EoG只连接同一个句子中的两个有关联的mention,不同句子中有关联的mention通过句子节点连接。每个提及对 m i m_i mi和 m j m_j mj之间的MM边的表示,由三种向量拼接而成:分别是两节点的表示 n m i n_{mi} nmi和 n m j n_{mj} nmj、上下文特征信息 c m i 、 m j c_{mi、mj} cmi、mj以及两个提及之间的距离嵌入 d m i 、 m j d_{mi、mj} dmi、mj,即 x M M = [ n m i ; n m j ; c m i , m j ; d m i , m j ] x_{MM}=[n_{mi};n_{mj};c_{mi,mj};d_{mi,mj}] xMM=[nmi;nmj;cmi,mj;dmi,mj]。其中上下文特征信息 c m i 、 m j c_{mi、mj} cmi、mj使用了一个简单的注意力机制:
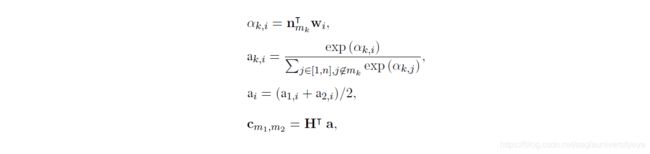 k = { 1 , 2 } k=\{1,2\} k={1,2}表示两个提及, w i w_i wi表示两个提及所在的句子中的word。
k = { 1 , 2 } k=\{1,2\} k={1,2}表示两个提及, w i w_i wi表示两个提及所在的句子中的word。 -
SS:每个句子节点都和其他的句子节点两两相连,SS边的表示由两节点的表示 n s i n_{si} nsi和 n s j n_{sj} nsj和距离向量 d s i 、 s j d_{si、sj} dsi、sj拼接而成, x S S = [ n s i ; n s j ; d s i , s j ] x_{SS}=[n_{si};n_{sj};d_{si,sj}] xSS=[nsi;nsj;dsi,sj]。其中距离向量 d s i 、 s j ∈ [ S S d i r e c t , S S i n d i r e c t ] d_{si、sj}∈[SS_{direct},SS_{indirect}] dsi、sj∈[SSdirect,SSindirect],当两个句子为相邻句时, d s i 、 s j = S S d i r e c t d_{si、sj} = SS_{direct} dsi、sj=SSdirect(距离等于1),当两个句子不相邻时, d s i 、 s j = S S i n d i r e c t d_{si、sj} = SS_{indirect} dsi、sj=SSindirect(距离>1)。
建立不同种类的边表示节点间的关系,最终的目的还是寻找实体EE之间是否存在关系,所以需要将异构的不同类型的边进行转换以能够进行计算。
e z ( 1 ) = W z x z e^{(1)}_z =W_zx_z ez(1)=Wzxz
e z ( 1 ) e^{(1)}_z ez(1)表示一个经过转换后的长度为1的边, W z ∈ R d z × d W_z∈R^{dz×d} Wz∈Rdz×d对应一个参数矩阵, z ∈ [ M M , M S , M E , S S , E S ] z∈[MM,MS,ME,SS,ES] z∈[MM,MS,ME,SS,ES]。
EoG在构建图时,不会将两个实体连接,这意味着没有直接的实体到实体(EE)的边。EoG通过节点之间的路径来生成实体到实体之间的联系,通过两步推理机制对图中节点和边之间的交互进行编码,从而对EE关联进行建模。
第一步,利用中间节点 k k k在两个节点 i i i和 j j j之间生成一条路径,然后计算:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TfnC7PyF-1595204837826)(C:\Users\IceBurg\Desktop\文档\例会\7.14\EoG2.PNG)]](http://img.e-com-net.com/image/info8/fc370dec50b744119da42caab6dfc41d.jpg) 其中σ是sigmoid非线性函数, W z ∈ R d z × d W_z∈R^{dz×d} Wz∈Rdz×d是一个参数矩阵, l l l是边的长度, e i k e_{ik} eik对应于节点 i i i和 k k k之间的边的表示。
其中σ是sigmoid非线性函数, W z ∈ R d z × d W_z∈R^{dz×d} Wz∈Rdz×d是一个参数矩阵, l l l是边的长度, e i k e_{ik} eik对应于节点 i i i和 k k k之间的边的表示。
第二步,用上一步得到的原始(短)边表示和新的(长)边表示进行聚合,如下所示:
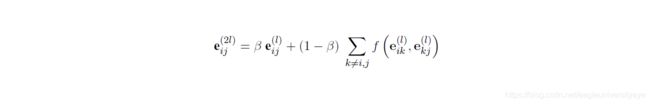 其中 β ∈ [ 0 , 1 ] β∈[0,1] β∈[0,1]是一个对远近关系进行控制的超参数, β β β越大表示对直接连接(近距离关系)的注意程度越高。
其中 β ∈ [ 0 , 1 ] β∈[0,1] β∈[0,1]是一个对远近关系进行控制的超参数, β β β越大表示对直接连接(近距离关系)的注意程度越高。
这两个步骤重复N次,迭代次数与边缘表示的最终长度相关。经过N次迭代,边的长度将达到2N。
经过上一步的推理过程之后,图中的信息经过不断循环流动,实体之间的信息充分交互,最后使用softmax分类器进行关系分类:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AmjLOek4-1595204837829)(C:\Users\IceBurg\Desktop\文档\例会\7.14\EoG3.PNG)]](http://img.e-com-net.com/image/info8/ca6e66b51dbc4735a9cfe32c82d3a136.jpg)
LSR
论文:Reasoning with Latent Structure Refinement for Document-Level Relation Extraction
本文提出的模型将图结构视为一个潜在变量,并以端到端的方式对其进行归纳。模型建立在结构化注意力的基础上。使用矩阵树定理的变体,能够生成任务特定的依赖结构,以捕捉实体之间的非局部交互。作者还提出了一种迭代策略,使模型能够基于上一次迭代动态地构建潜在结构,从而使模型能够不断地通过迭代捕获复杂的交互信息,改进整个文档中的信息聚合,从而更好地进行多跳推理。
简单的说就是,LSR构建了一个同质网络,不区分边的类型,通过节点信息的传播来更新边的表示,通过动态更新自动的学习到哪些边更重要,从而增强对远程关系的推理能力。
LSR模型由三个部分组成:节点构造函数、动态推理器和分类器。节点构造函数首先对输入文档的每个句子进行编码并输出上下文表示。句子中最短依赖路径上的token和提及相对应的表示被提取为节点,实体节点根据提及节点生成。然后应用动态推理器根据提取的节点归纳出文档级结构。基于潜在结构上的信息传播来更新节点的表示,并对其进行迭代优化。分类器使用节点的最终表示来计算分类分数。
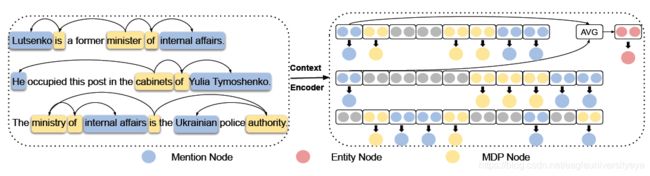
LSR中节点的构造:
- MDP元依赖节点:MDP表示一个句子中所有提及的最短依赖路径集,在MDP元依赖路径中,引用和单词的表示分别被提取为提及节点和MDP节点。
- mention提及节点:mention内部单词平均池化得到。
- entity实体节点:与entity相关联的所有mention的平均值。
LSR中节点的构造与EoG有一点不同。LSR和EoG都有实体节点和提及节点且构建方式是一样的,但LSR中没有句子节点,而是用MDP元依赖节点代替,这样的优点是可以有效地利用相关信息而忽略无关信息。
 节点的编码方式,可以使用bert或者LSRM,以BiLSTM为例:
节点的编码方式,可以使用bert或者LSRM,以BiLSTM为例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a8yKBpCj-1595204837830)(C:\Users\IceBurg\Desktop\文档\例会\7.14\LSR3.PNG)]](http://img.e-com-net.com/image/info8/209c5140600e47cca7605837a534728d.jpg) 使用两个方向的隐藏层向量的拼接作为token的向量,是很常规的做法。
使用两个方向的隐藏层向量的拼接作为token的向量,是很常规的做法。
动态推理器有两个模块,结构归纳模块和多跳推理模块。结构归纳模块用于学习文档级图的潜在结构。多跳推理模块用于对潜在结构进行推理,根据图中节点的信息聚合更新每个节点的表示。
LSR对于不同的节点之间采用相同的方式来计算概率,作为边的表示:
![]() 这个公式的含义可以理解为利用attention的方式计算两个节点之间的关联度,其中 W p ∈ R d × d W_p∈R^{d×d} Wp∈Rd×d和 W c ∈ R d × d W_c∈R{d×d} Wc∈Rd×d是两个前馈神经网络的权值, d d d是节点表示的维度,tanh作为激活函数。 W b ∈ R d × d W_b∈R^{d×d} Wb∈Rd×d是双线性变换的权值。
这个公式的含义可以理解为利用attention的方式计算两个节点之间的关联度,其中 W p ∈ R d × d W_p∈R^{d×d} Wp∈Rd×d和 W c ∈ R d × d W_c∈R{d×d} Wc∈Rd×d是两个前馈神经网络的权值, d d d是节点表示的维度,tanh作为激活函数。 W b ∈ R d × d W_b∈R^{d×d} Wb∈Rd×d是双线性变换的权值。
第i个节点被选为结构根节点的非规范化概率 s i r s_i^r sir:
![]() 其中 W r ∈ R 1 × d W_r∈R^{1×d} Wr∈R1×d是线性变换的权重。
其中 W r ∈ R 1 × d W_r∈R^{1×d} Wr∈R1×d是线性变换的权重。
接下来计算文档级图的每个依赖边的表示。对于有n个节点的图G,我们首先给图的边赋非负权 P ∈ R n × n P∈R^{n×n} P∈Rn×n:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ckYcK8pC-1595204837834)(C:\Users\IceBurg\Desktop\文档\例会\7.14\LSR6.PNG)]](http://img.e-com-net.com/image/info8/73f32eb98b944bf78875b3dd7fecd2f3.jpg) 其中 P i j P_{ij} Pij是第i个节点和第j个节点之间的边的权重。然后定义G的拉普拉斯矩阵 L ∈ R n × n L∈R_{n×n} L∈Rn×n,和它的变量 L ∗ ∈ R n × n L^*∈R_{n×n} L∗∈Rn×n:
其中 P i j P_{ij} Pij是第i个节点和第j个节点之间的边的权重。然后定义G的拉普拉斯矩阵 L ∈ R n × n L∈R_{n×n} L∈Rn×n,和它的变量 L ∗ ∈ R n × n L^*∈R_{n×n} L∗∈Rn×n:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q8dJZUe5-1595204837836)(C:\Users\IceBurg\Desktop\文档\例会\7.14\LSR7.PNG)]](http://img.e-com-net.com/image/info8/765847358610494595a4a6a7f440f26a.jpg) 最终计算出 A i j A_{ij} Aij作为文档级实体图的加权邻接矩阵,然后使用 A i j A_{ij} Aij构建GCN网络,在多跳推理模块中更新潜在结构中节点的表示。
最终计算出 A i j A_{ij} Aij作为文档级实体图的加权邻接矩阵,然后使用 A i j A_{ij} Aij构建GCN网络,在多跳推理模块中更新潜在结构中节点的表示。
![]() LSR基于图卷积网络GCN来进行推理。用由前一个结构归纳模块导出的n×n邻接矩阵 A i j A_{ij} Aij,第l层节点i的卷积计算(以前一层的表示 u i l − 1 u^{l-1}_i uil−1作为输入并输出更新的表示 u i l u^l_i uil)可以定义为:
LSR基于图卷积网络GCN来进行推理。用由前一个结构归纳模块导出的n×n邻接矩阵 A i j A_{ij} Aij,第l层节点i的卷积计算(以前一层的表示 u i l − 1 u^{l-1}_i uil−1作为输入并输出更新的表示 u i l u^l_i uil)可以定义为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DRx0cUjS-1595204837839)(C:\Users\IceBurg\Desktop\文档\例会\7.14\LSR10.PNG)]](http://img.e-com-net.com/image/info8/1514dde3674d445c9de503032ce9fb37.jpg) 其中, W l W^l Wl和 b l b^l bl分别是第l层的权重矩阵和偏移向量。σ是ReLU激活函数。 u i 0 ∈ R d u_i^0∈R^d ui0∈Rd是由节点构造函数构造的第i个节点的初始上下文表示。
其中, W l W^l Wl和 b l b^l bl分别是第l层的权重矩阵和偏移向量。σ是ReLU激活函数。 u i 0 ∈ R d u_i^0∈R^d ui0∈Rd是由节点构造函数构造的第i个节点的初始上下文表示。
LSR还使用了多层图网络密集连接,以便在大型文档级图上捕获更多的结构信息。在密集连接的帮助下,能够训练一个更深层次的模型,捕捉更丰富的局部和非局部信息,以学习更好的图形表示。这个密集连接的图网络和多头注意力机制的原理相似,而联想到图中边是根据两个节点经过注意力计算得到的,可以推测密集连接和多头注意力的效果相似,可以捕获图中不同的特征信息。
为了能够推断出超出简单父子关系的更丰富的结构信息,使用N个动态推理块来多次归纳文档级结构。通过与更丰富的非本地信息的交互,结构变得更加细化,归纳模块能够生成更合理的结构。
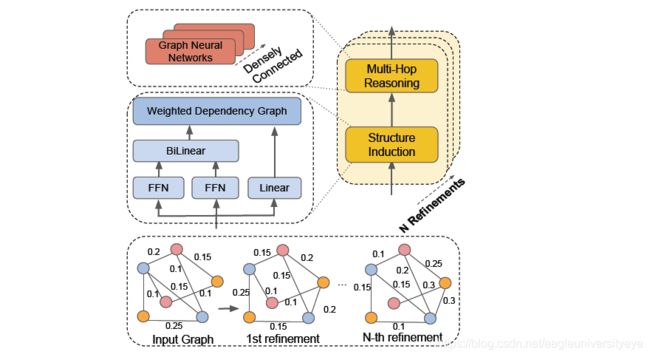
经过上述动态推理器的信息传递后,结果被输入进一个分类器对图中的实体节点对进行关系分类。
![]() 其中, W e ∈ R d × k × d W_e∈R^{d×k×d} We∈Rd×k×d和 b e ∈ R k b_e∈R^k be∈Rk是可训练的权值和偏差,k是关系类型的数量,σ是sigmoid激活函数,方程右边的下标r是关系类型。
其中, W e ∈ R d × k × d W_e∈R^{d×k×d} We∈Rd×k×d和 b e ∈ R k b_e∈R^k be∈Rk是可训练的权值和偏差,k是关系类型的数量,σ是sigmoid激活函数,方程右边的下标r是关系类型。
DyGIE/DyGIE++
论文:A General Framework for Information Extraction using Dynamic Span Graphs
DyGIE/DyGIE++构建了一个动态图,动态图与静态图的不同在于静态图构建时其节点是确定的,进行关系传播的过程中节点不会变化,而动态图节点不确定,关系传播的过程中节点会变化。
DyGIE使用片段分类的方法,首先列举出所有可能的片段,然后从候选span中选取一些比较有可能是实体的span片段,然后用这些片段作为图中的节点,并使用权重为置信度的关系类型以及共指关系连接这些节点。通过共指关系和关系类型构建的边进行信息传播,迭代地更新span的表示。
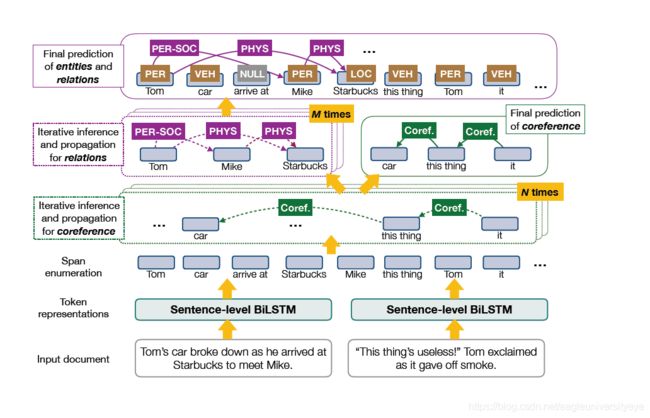
模型的输入采用字符表示、GLoVe词嵌入和ELMo嵌入的拼接,编码层采用Bi-LSTM。
得到字符的编码后,用枚举的方式列举出所有可能的span,对于每个span s i s_i si,使用字符特征和宽度特征的拼接作为其向量表达,用 g i 0 g_i^0 gi0表示。
得到初始的span向量表示后,接下来先进行共指传播。首先定义一个beam B C B_C BC,由最可能出现在共指链中的 b c b_c bc个span组成。共指关系图的边是单向的,当前的节点 s i s_i si和其在共指beam中潜在的父节点 s j s_j sj有一条边连接。 s i s_i si和 s j s_j sj间边的权重由在当前迭代中的共指可信度得分 P C t ( i , j ) P_C^t(i,j) PCt(i,j)决定, P C t P_C^t PCt大小为 b c × K b_c×K bc×K,其中K为候选父节点数量的最大值。通过聚合邻居span的表示 g j t g_j^t gjt,以共指分数 P C t ( i , j ) P_C^t(i,j) PCt(i,j)作为权重,计算更新向量 u C t ( i ) ∈ R d u_C^t(i)∈R^d uCt(i)∈Rd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8L6gDBmt-1595204837843)(C:\Users\IceBurg\Desktop\文档\例会\7.14\DyGIE1.PNG)]](http://img.e-com-net.com/image/info8/ad0b8a4576504f3b848475504c888ac2.jpg) 其中 B C ( i ) B_C(i) BC(i)是当前的节点 s i s_i si的 K K K个父节点span组成的集合。
其中 B C ( i ) B_C(i) BC(i)是当前的节点 s i s_i si的 K K K个父节点span组成的集合。
共指可信度得分 P C t ( i , j ) P_C^t(i,j) PCt(i,j)的计算方式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j3pDQQLz-1595204837845)(C:\Users\IceBurg\Desktop\文档\例会\7.14\DyGIE2.PNG)]](http://img.e-com-net.com/image/info8/fefeeb30a70e47b382cfdce17284d50b.jpg) 其中 V C t ( i , j ) V_C^t(i,j) VCt(i,j)是通过拼接span的表示 [ g i t , g j t , g i t ⊙ g j t ] [g_i^t,g_j^t,g_i^t⊙g_j^t] [git,gjt,git⊙gjt]计算得到的标量分值,其中 ⊙ ⊙ ⊙表示元素级别的相乘。将拼接后的向量输入到FFNN中,得到标量分值 V C t ( i , j ) V_C^t(i,j) VCt(i,j),通过 V C t ( i , j ) V_C^t(i,j) VCt(i,j)计算 P C t ( i , j ) P_C^t(i,j) PCt(i,j)。
其中 V C t ( i , j ) V_C^t(i,j) VCt(i,j)是通过拼接span的表示 [ g i t , g j t , g i t ⊙ g j t ] [g_i^t,g_j^t,g_i^t⊙g_j^t] [git,gjt,git⊙gjt]计算得到的标量分值,其中 ⊙ ⊙ ⊙表示元素级别的相乘。将拼接后的向量输入到FFNN中,得到标量分值 V C t ( i , j ) V_C^t(i,j) VCt(i,j),通过 V C t ( i , j ) V_C^t(i,j) VCt(i,j)计算 P C t ( i , j ) P_C^t(i,j) PCt(i,j)。
共指传播后,再进行关系传播,关系传播的方式和共指传播类似。对于每个句子,定义一个beam B R B_R BR,由 b r b_r br个最有可能有关联的实体spans组成。和共指关系图不同,此处关系图中边的权重捕获了不同关系类型的信息。因此,在第t次迭代中,使用一个张量 V R t ∈ R b R × b R × L R V^t_R∈R^{b_R×b_R×L_R} VRt∈RbR×bR×LR来捕获每种关系类型 L R L_R LR的分值。也就是说,关系图中的边连接了关系beam B R B_R BR中两个实体span s i s_i si和 s j s_j sj。通过聚合关系图中的相邻span的表示,得到关系更新向量 u R t ( i ) ∈ R d u^t_R(i)∈R^d uRt(i)∈Rd:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NpE2ZI9f-1595204837847)(C:\Users\IceBurg\Desktop\文档\例会\7.14\DyGIE3.PNG)]](http://img.e-com-net.com/image/info8/ba5cebf0e8c949ec84f90b248e454401.jpg) V R t ( i , j ) V_R^t(i,j) VRt(i,j)是通过将 [ g i t , g j t ] [g^t_i,g^t_j] [git,gjt]作为输入,通过一个FFNN得到的长为 L R L_R LR的关系分值向量。
V R t ( i , j ) V_R^t(i,j) VRt(i,j)是通过将 [ g i t , g j t ] [g^t_i,g^t_j] [git,gjt]作为输入,通过一个FFNN得到的长为 L R L_R LR的关系分值向量。
为了计算下一次迭代 t ∈ 1 , . . . , N + M t ∈ 1 , . . . , N + M t∈{1,...,N+M}t∈{1,...,N+M} t∈1,...,N+Mt∈1,...,N+M的span的表示,作者定义了一个门向量 f x t ( i ) ∈ R d , x ∈ C , R f_x^t(i)∈R^d,x∈{C,R} fxt(i)∈Rd,x∈C,R,来权衡对先前span表示 g i t g_i^t git的保留以及对共指链接/关系的更新向量 u x t ( i ) u_x^t(i) uxt(i)新信息的引入。计算公式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-23JNM9NT-1595204837847)(C:\Users\IceBurg\Desktop\文档\例会\7.14\DyGIE4.PNG)]](http://img.e-com-net.com/image/info8/4352430f0b2440a895c037f902a06d57.jpg)