NLP教程笔记:GPT 单向语言模型
NLP教程
TF_IDF
词向量
句向量
Seq2Seq 语言生成模型
CNN的语言模型
语言模型的注意力
Transformer 将注意力发挥到极致
ELMo 一词多义
GPT 单向语言模型
BERT 双向语言模型
NLP模型的多种应用
目录
- NLP教程
- GPT是啥
- 学习案例
- 代码
- GPT注意力结果
- 还能怎么玩
- 全部代码
今天要学习的是一个在自然语言中比ELMo更厉害的模型。 这个模型玩的不是RNN那一套循环机制,而是Transformer的注意力机制。 它成功地将Transformer的注意力运用在语言模型中,并且让模型能够非常精准的预测出答案,在很多方面让人类打开眼界。
这个模型就是 Generative Pre-Training (GPT) 模型。目前这个模型已经迭代了3个版本了,最强的一个GPT3,媒体已经将其夸上了天。不过抛开噱头部分, GPT3的确算是在NLP里面的优秀模型。
GPT是啥
GPT主要的目标还是当好一个预训练模型该有的样子。用非监督的人类语言数据,训练一个预训练模型,然后拿着这个模型进行finetune, 基本上就可以让你在其他任务上也表现出色。因为下游要finetune的任务千奇百怪,在这个教学中,我会更专注GPT模型本身。 告诉你GPT模型到底长什么样,又会有什么样的特性。至于后续的finetune部分,其实比起模型本身,要容易不少。
具体到GPT的模型,其实它和Transformer有着目不可分的联系。有人说它是Transformer的Decoder,但是我觉得这可能并不准确。 它更像是一种Transformer Decoder与Encoder的结合。用着Decoder的 Future Mask (Look Ahead Mask),但结构上又更像Encoder。
说说为什么这样设计吧。说到底,这么设计就是为了让GPT方便训练。用前文的信息预测后文的信息,所以用上了Future Mask。
如果不用Future Mask, 又要做大量语料的非监督学习,很可能会让模型在预测A时看到A的信息,从而有一种信息穿越的问题。 具体解释一下,因为Transformer这种MultiHead Attention模式,每一个Head都会看到所有的文字内容,如果用前文的信息预测后文内容,又不用Future Mask时, 模型是可以看到要预测的信息的,这种训练是无效的。 Future Mask的应用,就是不让模型看到被穿越的信息,用一双无形的手,蒙蔽了它的透视眼。
另外一个与Transformer Decoder的不同之处是,它没有借用到Encoder提供的 self-attention 信息。所以GPT的Decoder要比Transformer少一些层。 那么最终的模型乍一看的确和Transformer的某一部分很像,不过就是有两点不同。
- Decoder 少了一些连接 Encoder 的层;
- 只使用Future Mask (Look ahead mask)做注意力。
学习案例
和训练ELMo一样,我们拥有网络上大量的无标签数据,语言模型进行无监督学习,训练出一个pretrained模型就有了优势。 这次的案例我们还是使用在ELMo训练的 Microsoft Research Paraphrase Corpus (MRPC) 数据。 可以做一个横向对比。这个数据集的内容大概是用这种形式组织的。

每行有两句话 #1 String 和 #2 String, 如果他们是语义相同的话,Quality 为1,反之为0。这份数据集可以做两件事:
- 两句合起来训练文本匹配;
- 两句拆开单独对待,理解人类语言,学一个语言模型。
这个教学中,我们在训练语言模型的时候,用的是无监督的方法训练第2种模式。但同时也涉及到了第1种任务。 除了无监督能训练,我们同样还能引入有监督的学习, 这次GPT就带你体验一把同时训练无监督和有监督的做法。
其实我们可以将无监督看成是一个task,预测是否是下一句看成另一个task,当然task还能有很多。就看你的数据支持的是什么样的task了。 多种task一起来训练一个模型,能让这个模型在更多task上的泛化能力更强。
先看看最终的训练结果会是怎样吧~
代码
首先还是我们的训练步骤,因为训练的循环是最能看出来训练时的差异化的。
def train(model, data, step=10000):
for t in range(step):
seqs, segs, xlen, nsp_labels = data.sample(16)
loss, pred = model.step(seqs[:, :-1], segs[:, :-1], seqs[:, 1:], nsp_labels)
d = utils.MRPCData("./MRPC", 2000)
m = GPT(...)
train(m, d, step=5000)
这里的utils.MRPCData(), 已经将他们封装好, model.step()中,
seqs[:, :-1]是X input中的句子信息,segs[:, :-1]是X input的前后句信息,判断是否是前句还是后句。因为我们会同时将前句和后句放在seqs中一起给模型,所以模型需要搞清楚他到底是前句还是后句。seqs[:, 1:]是非监督学习的Y信息,用前句预测后句。nsp_labels是判断输入的两句话是否是前后文关系。
总体来说,就是将前后句的文本信息和片段信息传入模型,让模型训练两个任务,
- 非监督的后文预测,
- 是否是下一句。
我们可以看到,如果展示出整个训练的结果,它是这样的:
step: 0 | time: 0.63 | loss: 9.663
| tgt: they also are reshaping the retail business relationship elsewhere , as companies take away ideas and practices that change how they do business in their own firms and with others . <SEP> they also are reshaping the retail-business relationship , as companies take away concepts and practices that change how they do business internally and with others .
| prd: kinsley van-vliet franco atheist bottom kent performance toured trapeze reporting alta miz crush <NUM>-month crush kennedy dominick clarence ``will thames mr scanning abuses losses sleeping since detection punching scrutiny fare-beating shiites sue gagne canfor built schafer chronicle assignment cat deadline action slipping enhances crush tearing cat mobile widen treaty retire towards an-najaf virtually alta widen files gillian jamaica
step: 100 | time: 14.39 | loss: 8.227
| tgt: <quote> we are declaring war on sexual harassment and sexual assault . <SEP> <quote> we have declared war on sexual assault and sexual harassment , <quote> rosa said .
| prd: the the the the the the the the the , the the <SEP> the the , , , , , , , , , <NUM> <SEP> <SEP> <NUM> the
...
step: 4800 | time: 14.08 | loss: 0.612
| tgt: the rest said they belonged to another party or had no affiliation . <SEP> the rest said they had no affiliation or belonged to another party .
| prd: the company said they remain to another party or had no affiliation . <SEP> the rest said they had no affiliation or belonged to another party or
step: 4900 | time: 14.05 | loss: 0.677
| tgt: <quote> craxi begged me to intervene because he believed the operation damaged the state , <quote> mr berlusconi said . <SEP> <quote> i had no direct interest and craxi begged me to intervene because he believed that the deal was damaging to the state , <quote> berlusconi testified .
| prd: the the begged me to intervene because he believed the operation damaged the state , <quote> mr berlusconi said . <SEP> <quote> i had no direct interest and craxi begged me to intervene because in believed that the deal was damaging to the state , <quote> berlusconi testified .
经历了5000步的训练,从最开始频繁预测 the 变成最能够比较好预测句子的后半段内容。因为future mask的原因,GPT是没办法很好的预测句子的前半段的, 因为前半段的信息太少了。所以我们才说GPT是单向语言模型。
而模型的架构我们会使用到在Transformer中的Encoder代码,因为他们是通用的。 只是我们需要将Encoder中的Mask规则给替换掉。而且在模型中为seg和word多加上几个embedding参数。
class GPT(keras.Model):
def __init__(self, ...):
self.word_emb = keras.layers.Embedding(...) # [n_vocab, dim]
self.segment_emb = keras.layers.Embedding(...) # [max_seg, dim]
self.position_emb = self.add_weight(...) # [step, dim]
self.encoder = Encoder(n_head, model_dim, drop_rate, n_layer)
self.task_mlm = keras.layers.Dense(n_vocab)
self.task_nsp = keras.layers.Dense(2)
...
定义好词向量word_emb,片段向量segment_emb,位置向量position_emb, 这三个向量表达,我们的输入端就完成了, 接着就是直接套用Transformer的encoder。
class GPT(keras.Model):
def input_emb(self, seqs, segs):
return self.word_emb(seqs) + self.segment_emb(segs) + self.position_emb # [n, step, dim]
def call(self, seqs, segs, training=False):
embed = self.input_emb(seqs, segs) # [n, step, dim]
z = self.encoder(embed, training=training, mask=self.mask(seqs)) # [n, step, dim]
mlm_logits = self.task_mlm(z) # [n, step, n_vocab]
nsp_logits = self.task_nsp(tf.reshape(z, [z.shape[0], -1])) # [n, n_cls]
return mlm_logits, nsp_logits
用call()做前向预测的时候,X数据过一遍所有的embedding,然后直接进入Transformer的Encoder,拿到最后的注意后的结果。 最后经过两个输出端 mlm (非监督语言模型) 和 nsp (是否是前后句),完成两个任务的预测。 对于encoder中使用的mask,我们需要特别定义,因为之前上面也提到过,在GPT中的mask不是Transformer中的mask,因为GPT做非监督训练的时候, 是不能看到未来的信息的。所以,我们要定制一个future mask来蒙蔽它的双眼。
class GPT(keras.Model):
def mask(self, seqs):
"""
abcd--
a011111
b001111
c000111
d000011
-000011
-000011
force head not to see afterward. eg.
a is a embedding for a---
b is a embedding for ab--
c is a embedding for abc-
later, b embedding will + b another embedding from previous residual input to predict c
"""
mask = 1 - tf.linalg.band_part(tf.ones((self.max_len, self.max_len)), -1, 0)
pad = tf.math.equal(seqs, self.padding_idx)
mask = tf.where(pad[:, tf.newaxis, tf.newaxis, :], 1, mask[tf.newaxis, tf.newaxis, :, :])
return mask # (step, step)
为什么不直接用Transformer中的lookaheadmask呢?其实也就是因为我写Transformer的时候,是将paddingmask和lookaheadmask分开写的。 但是GPT的future mask,我想把 paddingmask和lookaheadmask 合起来。所以重新写了一下。如果可视化出来,就是这样。
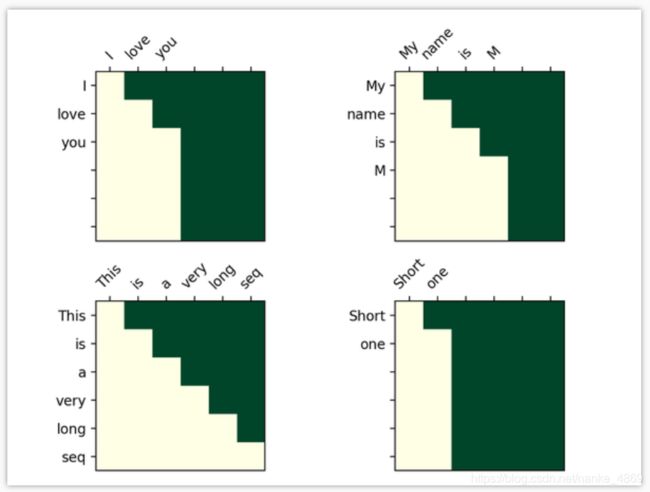
GPT的核心代码就这么多啦。
GPT注意力结果
模型经过5000步训练,已经能有效地注意到句子中的某些重要部分了。我们来看看矩阵形式的attention。 之后我们做BERT可视化的时候也会用到这份可视化代码。
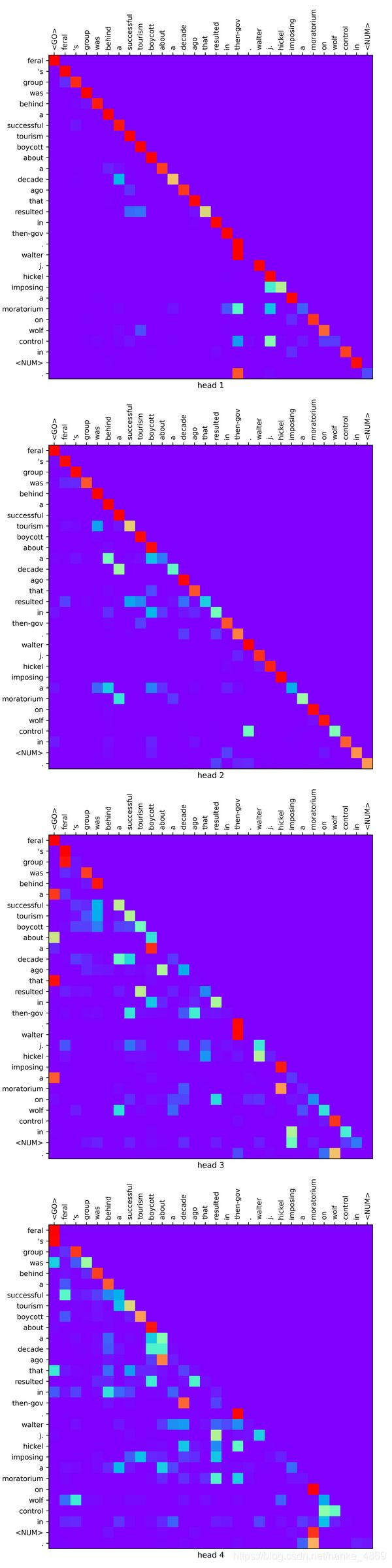
矩阵的形式可能不太方便看出什么结果。所以我还是做了一个连线形式的。这种连线模式就能比较好看出每个词的注意力关系,线段粗的注意力就越大。 我输出的是最后一层网络的自注意力。在这一层中一共有4个head,所以相当于有4个人在看这些信息,每个人关注不同的部分。
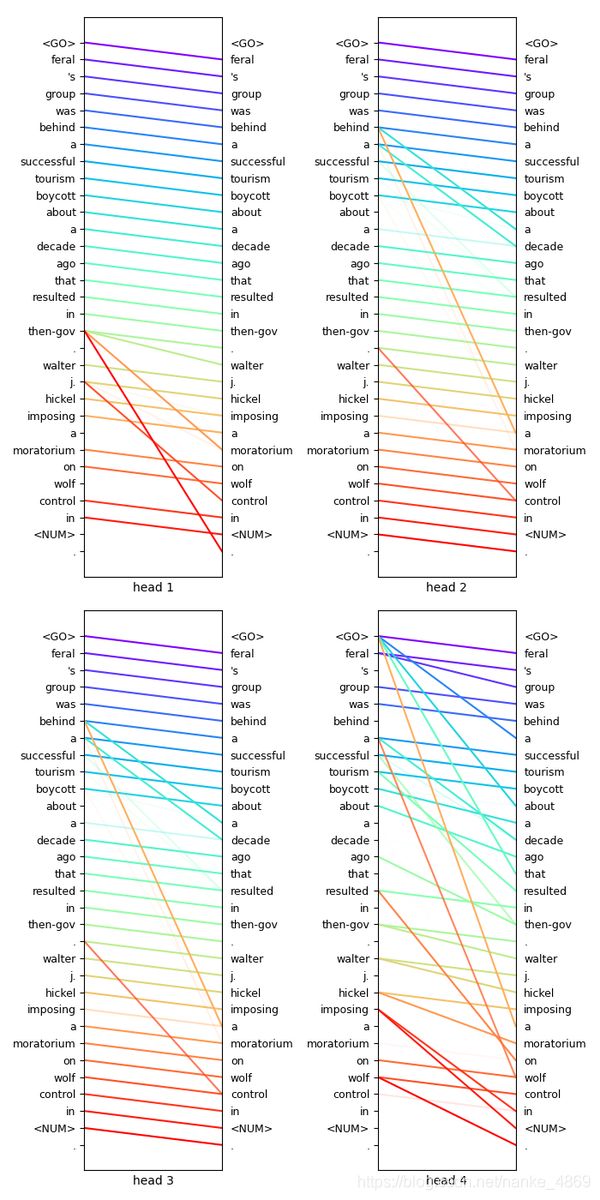
我们还是可以观测到一些关键的注意节点的,head3在预测posted的时候,关注到的是前面的pearson。有趣的是,很多头都会用最开始的
还能怎么玩
GPT 已经比ELMo好上很多了,但研究人员为了达到更高的效果,目前还有两个升级版。 GPT2(稍微调整了一下结构,主结构不变)增大了模型的体量, 它有1600维隐藏层,参数规模达15亿。 GPT3在GPT2的基础上再次拓展,变得更大,效果更好。1750亿个参数,真是大力出奇迹。
什么感受,天哪!GPT3的参数量已经不是其他模型能够相比的了。可见,在拼爹拼硬件的年代,拼NLP的效果,如果你爹不是Google,openAI,微软,阿里腾讯等,你是根本没有机会训练这样庞大的模型的。 唉,普通NLP玩家充当一下吃瓜群众就好了~
全部代码
可视化代码
def self_attention_matrix(bert_or_gpt="gpt", case=0):
with open("./visual/tmp/"+bert_or_gpt+"_attention_matrix.pkl", "rb") as f:
data = pickle.load(f)
src = data["src"]
attentions = data["attentions"]
encoder_atten = attentions["encoder"]
plt.rcParams['xtick.bottom'] = plt.rcParams['xtick.labelbottom'] = False
plt.rcParams['xtick.top'] = plt.rcParams['xtick.labeltop'] = True
s_len = 0
for s in src[case]:
if s == "" :
break
s_len += 1
plt.figure(0, (7, 28))
for j in range(4):
plt.subplot(4, 1, j + 1)
img = encoder_atten[-1][case, j][:s_len-1, :s_len-1]
plt.imshow(img, vmax=img.max(), vmin=0, cmap="rainbow")
plt.xticks(range(s_len-1), src[case][:s_len-1], rotation=90, fontsize=9)
plt.yticks(range(s_len-1), src[case][1:s_len], fontsize=9)
plt.xlabel("head %i" % (j+1))
plt.subplots_adjust(top=0.9)
plt.tight_layout()
plt.savefig("./visual/results/"+bert_or_gpt+"%d_self_attention.png" % case, dpi=500)
# plt.show()
utils.MRPCData()
class MRPCData:
num_seg = 3
pad_id = PAD_ID
def __init__(self, data_dir="./MRPC/", rows=None, proxy=None):
maybe_download_mrpc(save_dir=data_dir, proxy=proxy)
data, self.v2i, self.i2v = _process_mrpc(data_dir, rows)
self.max_len = max(
[len(s1) + len(s2) + 3 for s1, s2 in zip(
data["train"]["s1id"] + data["test"]["s1id"], data["train"]["s2id"] + data["test"]["s2id"])])
self.xlen = np.array([
[
len(data["train"]["s1id"][i]), len(data["train"]["s2id"][i])
] for i in range(len(data["train"]["s1id"]))], dtype=int)
x = [
[self.v2i["" ]] + data["train"]["s1id"][i] + [self.v2i["" ]] + data["train"]["s2id"][i] + [self.v2i["" ]]
for i in range(len(self.xlen))
]
self.x = pad_zero(x, max_len=self.max_len)
self.nsp_y = data["train"]["is_same"][:, None]
self.seg = np.full(self.x.shape, self.num_seg-1, np.int32)
for i in range(len(x)):
si = self.xlen[i][0] + 2
self.seg[i, :si] = 0
si_ = si + self.xlen[i][1] + 1
self.seg[i, si:si_] = 1
self.word_ids = np.array(list(set(self.i2v.keys()).difference(
[self.v2i[v] for v in ["" , "" , "" ]])))
def sample(self, n):
bi = np.random.randint(0, self.x.shape[0], size=n)
bx, bs, bl, by = self.x[bi], self.seg[bi], self.xlen[bi], self.nsp_y[bi]
return bx, bs, bl, by
@property
def num_word(self):
return len(self.v2i)
@property
def mask_id(self):
return self.v2i["" ]
import tensorflow as tf
from tensorflow import keras
import utils
import time
from transformer import Encoder
import pickle
import os
class GPT(keras.Model):
def __init__(self, model_dim, max_len, n_layer, n_head, n_vocab, lr, max_seg=3, drop_rate=0.1, padding_idx=0):
super().__init__()
self.padding_idx = padding_idx
self.n_vocab = n_vocab
self.max_len = max_len
self.word_emb = keras.layers.Embedding(
input_dim=n_vocab, output_dim=model_dim, # [n_vocab, dim]
embeddings_initializer=tf.initializers.RandomNormal(0., 0.01),
)
self.segment_emb = keras.layers.Embedding(
input_dim=max_seg, output_dim=model_dim, # [max_seg, dim]
embeddings_initializer=tf.initializers.RandomNormal(0., 0.01),
)
self.position_emb = self.add_weight(
name="pos", shape=[1, max_len, model_dim], dtype=tf.float32, # [1, step, dim]
initializer=keras.initializers.RandomNormal(0., 0.01))
self.encoder = Encoder(n_head, model_dim, drop_rate, n_layer)
self.task_mlm = keras.layers.Dense(n_vocab)
self.task_nsp = keras.layers.Dense(2)
self.cross_entropy = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction="none")
self.opt = keras.optimizers.Adam(lr)
def call(self, seqs, segs, training=False):
embed = self.input_emb(seqs, segs) # [n, step, dim]
z = self.encoder(embed, training=training, mask=self.mask(seqs)) # [n, step, dim]
mlm_logits = self.task_mlm(z) # [n, step, n_vocab]
nsp_logits = self.task_nsp(tf.reshape(z, [z.shape[0], -1])) # [n, n_cls]
return mlm_logits, nsp_logits
def step(self, seqs, segs, seqs_, nsp_labels):
with tf.GradientTape() as tape:
mlm_logits, nsp_logits = self.call(seqs, segs, training=True)
pad_mask = tf.math.not_equal(seqs_, self.padding_idx)
pred_loss = tf.reduce_mean(tf.boolean_mask(self.cross_entropy(seqs_, mlm_logits), pad_mask))
nsp_loss = tf.reduce_mean(self.cross_entropy(nsp_labels, nsp_logits))
loss = pred_loss + 0.2 * nsp_loss
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss, mlm_logits
def input_emb(self, seqs, segs):
return self.word_emb(seqs) + self.segment_emb(segs) + self.position_emb # [n, step, dim]
def mask(self, seqs):
"""
abcd--
a011111
b001111
c000111
d000011
-000011
-000011
force head not to see afterward. eg.
a is a embedding for a---
b is a embedding for ab--
c is a embedding for abc-
later, b embedding will + b another embedding from previous residual input to predict c
"""
mask = 1 - tf.linalg.band_part(tf.ones((self.max_len, self.max_len)), -1, 0)
pad = tf.math.equal(seqs, self.padding_idx)
mask = tf.where(pad[:, tf.newaxis, tf.newaxis, :], 1, mask[tf.newaxis, tf.newaxis, :, :])
return mask # (step, step)
@property
def attentions(self):
attentions = {
"encoder": [l.mh.attention.numpy() for l in self.encoder.ls],
}
return attentions
def train(model, data, step=10000, name="gpt"):
t0 = time.time()
for t in range(step):
seqs, segs, xlen, nsp_labels = data.sample(16)
loss, pred = model.step(seqs[:, :-1], segs[:, :-1], seqs[:, 1:], nsp_labels)
if t % 100 == 0:
pred = pred[0].numpy().argmax(axis=1)
t1 = time.time()
print(
"\n\nstep: ", t,
"| time: %.2f" % (t1 - t0),
"| loss: %.3f" % loss.numpy(),
"\n| tgt: ", " ".join([data.i2v[i] for i in seqs[0, 1:][:xlen[0].sum()+1]]),
"\n| prd: ", " ".join([data.i2v[i] for i in pred[:xlen[0].sum()+1]]),
)
t0 = t1
os.makedirs("./visual/models/%s" % name, exist_ok=True)
model.save_weights("./visual/models/%s/model.ckpt" % name)
def export_attention(model, data, name="gpt"):
model.load_weights("./visual/models/%s/model.ckpt" % name)
# save attention matrix for visualization
seqs, segs, xlen, nsp_labels = data.sample(32)
model.call(seqs[:, :-1], segs[:, :-1], False)
data = {"src": [[data.i2v[i] for i in seqs[j]] for j in range(len(seqs))], "attentions": model.attentions}
path = "./visual/tmp/%s_attention_matrix.pkl" % name
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "wb") as f:
pickle.dump(data, f)
if __name__ == "__main__":
utils.set_soft_gpu(True)
MODEL_DIM = 256
N_LAYER = 4
LEARNING_RATE = 1e-4
d = utils.MRPCData("./MRPC", 2000)
print("num word: ", d.num_word)
m = GPT(
model_dim=MODEL_DIM, max_len=d.max_len - 1, n_layer=N_LAYER, n_head=4, n_vocab=d.num_word,
lr=LEARNING_RATE, max_seg=d.num_seg, drop_rate=0.2, padding_idx=d.pad_id)
train(m, d, step=5000, name="gpt")
export_attention(m, d, name="gpt")