Bert实战之文本分类(附代码)
Bert实战之文本分类
-
- 1、概要
- 2、Bert怎么用
-
- 2.1 fine-tune(微调)
- 2.2 feature extract(特征抽取)
- 3、coding
-
- 3.1 基于fine-tune的文本分类
- 3.2 基于feature extract的文本分类
1、概要
Bert 是 Google 在 2018 年 10 月提出的一种利用大规模语料进行训练的语言模型,其通过Masked LM和sentence-level这两个子任务进行预训练。
2、Bert怎么用
2.1 fine-tune(微调)
通过加载预训练好的 Bert 模型,将我们自己任务的数据集输入给该模型,在原网络上继续训练、不断更新模型的权重,最后得到一个适用于自己任务的模型。
2.2 feature extract(特征抽取)
调用预训练好的 Bert 模型,将我们自己任务的训练数据编码成定长的向量(此方法类似于word2vec,区别在于bert获取的是上下文相关的表示,而word2vec是查表得到的词向量)。和Bert类似的还有ELMo(Deep contextualized word representations)
3、coding
3.1 基于fine-tune的文本分类
import argparse
import tensorflow as tf
import numpy as np
from bert import tokenization
from bert import modeling
import data_input
tf.logging.set_verbosity(tf.logging.INFO)
def main():
num_class = 10 # 分类类别数
bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_path+"bert_config.json")
vocab_file = FLAGS.bert_path+"vocab.txt"
if FLAGS.max_seq_len > bert_config.max_position_embeddings: # 模型有个最大的输入长度 512
raise ValueError("超出模型最大长度")
tf.logging.info("**** init model ****")
with tf.name_scope("bert_feture_extract"):
# 创建bert的输入
input_ids=tf.placeholder (shape=[None, None],dtype=tf.int32,name="input_ids")
input_mask=tf.placeholder (shape=[None, None],dtype=tf.int32,name="input_mask")
input_segment_ids=tf.placeholder (shape=[None, None],dtype=tf.int32,name="input_segment_ids")
input_labels=tf.placeholder (shape=[None],dtype=tf.int32,name="input_ids")
# 创建bert模型
model = modeling.BertModel(
config=bert_config,
is_training=True,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=input_segment_ids,
use_one_hot_embeddings=False
)
# output_layer = model.get_sequence_output()# 这个获取每个token的output 输入数据[batch_size, seq_length, embedding_size] 如果做seq2seq 或者ner 用这个
output_layer = model.get_pooled_output() # 这个获取句子的表示
# hidden_size = output_layer.shape[-1].value #获取输出的维度
with tf.name_scope("mlp_layer"):
output_layer = tf.contrib.layers.fully_connected(output_layer, 128, activation_fn=tf.nn.relu)
with tf.name_scope("output_layer"):
W = tf.get_variable(name="W", shape=[128, num_class],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable(name="b", shape=[num_class])
logits = tf.nn.xw_plus_b(output_layer, W, b, name="logits")
probs = tf.nn.softmax(logits, axis=1, name="probs")
with tf.name_scope("metrics"):
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=input_labels, logits=logits))
predictions = tf.argmax(logits, 1, name="predictions")
correct_prediction = tf.equal(tf.cast(predictions,tf.int32), input_labels)
accuracy =tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name="Accuracy")
with tf.name_scope("optim"):
global_step = tf.Variable(0, name="global_step", trainable=False)
# 指定优化器
optimizer = tf.train.AdamOptimizer(FLAGS.lr)
grads_and_vars = optimizer.compute_gradients(loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
saver = tf.train.Saver()
with tf.name_scope("bert_vars_init"):
#bert模型参数初始化的地方
init_checkpoint = FLAGS.bert_path+"bert_model.ckpt"
use_tpu = False
# 获取模型中所有的训练参数。
tvars = tf.trainable_variables()
# 加载BERT模型
(assignment_map, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars,
init_checkpoint)
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
# 打印加载模型的参数
for var in tvars:
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
tf.logging.info("**** loading data... ****")
train_file = 'data/train_bert.txt'
test_file = 'data/test_bert.txt'
train_data = data_input.get_data(train_file, vocab_file, FLAGS.max_seq_len, True)
test_data = data_input.get_data(test_file, vocab_file, FLAGS.max_seq_len, False)
train_steps = int(len(train_data[0])/FLAGS.batch_size)
test_steps = int(len(test_data[0])/FLAGS.batch_size)
tf.logging.info("**** Training... ****")
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
sess_config.gpu_options.allow_growth = True
with tf.Session(config=sess_config) as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(5):
for train_step in range(train_steps):
batch_labels = train_data[-1][train_step*FLAGS.batch_size: (train_step+1)*FLAGS.batch_size]
batch_input_idsList=train_data[0][train_step*FLAGS.batch_size:(train_step+1)*FLAGS.batch_size, :]
batch_input_masksList=train_data[1][train_step*FLAGS.batch_size: (train_step+1)*FLAGS.batch_size, :]
batch_segment_idsList=train_data[2][train_step*FLAGS.batch_size: (train_step+1)*FLAGS.batch_size, :]
l,a,_global_step,_train_op= sess.run([loss,accuracy,global_step, train_op],feed_dict={
input_ids:batch_input_idsList,input_mask:batch_input_masksList,
input_segment_ids:batch_segment_idsList,input_labels:batch_labels
})
if (train_step%1000)==0:
tf.logging.info("【Train】:step: {}, acc: {}, loss: {}".format(_global_step, a, l))
top_correct_count = 0
acces = []
for test_step in range(test_steps):
batch_labels = test_data[-1][test_step*FLAGS.batch_size: (test_step+1)*FLAGS.batch_size]
batch_input_idsList=test_data[0][test_step*FLAGS.batch_size:(test_step+1)*FLAGS.batch_size, :]
batch_input_masksList=test_data[1][test_step*FLAGS.batch_size: (test_step+1)*FLAGS.batch_size, :]
batch_segment_idsList=test_data[2][test_step*FLAGS.batch_size: (test_step+1)*FLAGS.batch_size, :]
probs, test_acc = sess.run([probs, accuracy],feed_dict={
input_ids:batch_input_idsList,input_mask:batch_input_masksList,
input_segment_ids:batch_segment_idsList,input_labels:batch_labels
})
acces.append(test_acc)
tf.logging.info("【Eval】:acc: {}".format(np.mean(acces))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', type=int, default=32,
help='Number of steps to run trainer.')
parser.add_argument('--lr', type=float, default=0.00005,
help='Initial learning rate')
parser.add_argument('--max_seq_len', type=int, default=32,
help='max_seq_len')
parser.add_argument('--bert_path', type=str, default='chinese_L-12_H-768_A-12/',
help='bert_path')
FLAGS, unparsed = parser.parse_known_args()
tf.logging.info(FLAGS)
main()
官方fine-tune超参推荐:
• Batch size: 16, 32
• Learning rate (Adam): 5e-5, 3e-5, 2e-5
• Number of epochs: 3, 4
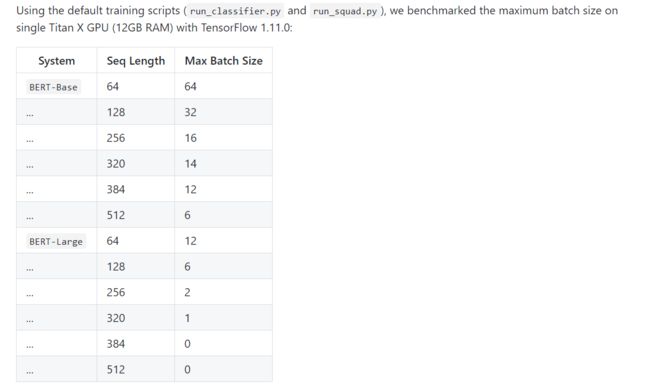
3.2 基于feature extract的文本分类
利用bert-as-service对语料进行表示,获取其向量后后面可以接自定义的网络结构。当作word2vec的向量用就可以,在此不做赘述。
参考1、参考2