【逆强化学习-1】学徒学习(Apprenticeship Learning)
文章目录
- 0.引言
- 1.算法原理
- 2.仿真环境
- 3.运行
- 4.补充(学徒学习+深度Q网络)
本文为逆强化学习系列第1篇,没有看过逆强化学习介绍的那篇的朋友,可以看一下:
Inverse Reinforcement Learning-Introduction 传送门
0.引言
\qquad 可以说学徒学习(简称App)是最早的一种逆强化学习的方法,如果看过最原始那篇论文的读者可能会觉得这个方法怎么这么晦涩难懂,但其实看完Code你会觉得这个Algorithm还挺粗糙的,这还是一件挺矛盾的事情。由于IRL-Introduction的论文介绍中没有该论文的下载链接,因此将其提供如下:
本文完整代码链接:CSDN下载
论文PDF链接:论文PDF(CSDN资源,永久免费)
1.算法原理
\qquad 在IRL-Introduction介绍过了,该方法是2004年出现的,那时候DL还不是很受欢迎,因此作者采用的是线性函数的方法计算Reward的。APP方法从Observation中提取特征,计算特征期望,再将reward作为特征期望的线性函数。
\qquad 提取特征的函数可以是非线性的,对算法没有任何影响,一般记为 ϕ ( s ) \phi(s) ϕ(s),而轨迹 π \pi π的特征期望 μ ( π ) \mu(\pi) μ(π)在paper中的计算方法即为
μ ( π ) = ∑ t = 0 ∞ γ t ϕ ( s t ) \mu(\pi)=\sum_{t=0}^{\infty}\gamma^t\phi(s_t) μ(π)=t=0∑∞γtϕ(st)
\qquad 如果是环境在互动过程中具有随机性,则求得的应该是特征期望的数学期望,用均值近似数学期望可以得到(其中n为轨迹数目, s t ( i ) s_t^{(i)} st(i)为第 i i i条轨迹的第 t t t个状态):
μ ( π ) = 1 n ∑ i = 1 n ∑ t = 0 ∞ γ t ϕ ( s t ( i ) ) \mu(\pi)=\frac{1}{n}\sum_{i=1}^{n}\sum_{t=0}^{\infty}\gamma^t\phi(s_t^{(i)}) μ(π)=n1i=1∑nt=0∑∞γtϕ(st(i))
在实际求解中,计算有限的时域 t t t近似即可。
\qquad 学徒学习的基本思想是寻找Reward使得所有的Agent产生的Reward都小于Expert的Reward的,再用这个reward去训练Agent。但为了防止Margin走向0和无穷大两个极端,在约束条件时还加入了一些限制。
该算法的步骤如下:
- 获得专家轨迹 π E \pi_E πE,定于特征提取函数 ϕ ( s t ) , t = 1 , 2 , . . . , N \phi(s_t),t=1,2,...,N ϕ(st),t=1,2,...,N,产生一个Random Agent,迭代次数 g = 0 g=0 g=0,随机设定一个 w w w,奖赏函数 r ϕ = w T μ ( π ) r_\phi=w^T\mu(\pi) rϕ=wTμ(π)
- 利用 ϕ \phi ϕ提取专家轨迹的特征 ϕ ( s 1 ( E ) ) , ϕ ( s 2 ( E ) ) , . . . , ϕ ( s N ( E ) ) \phi(s_1^{(E)}),\phi(s_2^{(E)}),...,\phi(s_N^{(E)}) ϕ(s1(E)),ϕ(s2(E)),...,ϕ(sN(E))
- 定义折扣因子 γ \gamma γ并计算专家轨迹的特征期望 μ ( π E ) = ∑ t γ t ϕ ( s t ( E ) ) \mu(\pi_E)=\sum_t\gamma^t\phi(s_t^{(E)}) μ(πE)=∑tγtϕ(st(E))
- 奖赏函数设为 r ϕ = w T μ ( π g ) r_\phi=w^T\mu(\pi_g) rϕ=wTμ(πg),Agent与环境互动(可能会互动不止一次,因为model的更新需要时间),产生轨迹 π g \pi_g πg,提取特征为 ϕ ( s 1 ( E ) ) , ϕ ( s 2 ( E ) ) , . . . , ϕ ( s M ( E ) ) \phi(s_1^{(E)}),\phi(s_2^{(E)}),...,\phi(s_M^{(E)}) ϕ(s1(E)),ϕ(s2(E)),...,ϕ(sM(E)),也计算Agent的轨迹期望值 μ ( π g ) = ∑ t γ t ϕ ( s t ( g ) ) \mu(\pi_g)=\sum_t\gamma^t\phi(s_t^{(g)}) μ(πg)=∑tγtϕ(st(g))
- 求解最优 w = w ∗ w=w^* w=w∗以更新线性Reward函数 r ϕ = w T μ ( π ) r_\phi=w^T\mu(\pi) rϕ=wTμ(π):
m a x t , w t s . t . { w T μ ( π E ) ≥ w T μ ( π g ) + t , g = 0 , 1 , . . . , i − 1 ∥ w ∥ 2 ≤ 1 \begin{aligned}& max_{t,w}\quad t\\ & s.t.\begin{cases}w^T\mu(\pi_E)\geq w^T\mu(\pi_g)+t,g=0,1,...,i-1 \\[2ex] \lVert w\rVert_2\leq1 \end{cases} \end{aligned} maxt,wts.t.⎩ ⎨ ⎧wTμ(πE)≥wTμ(πg)+t,g=0,1,...,i−1∥w∥2≤1 - g = g + 1 g=g+1 g=g+1,若达到最大迭代次数,终止,否则转步骤4.
其他的步骤都没什么,主要是步骤(5),步骤(5)不仅不是线性规划,还带有一个令人讨厌的非线性约束(意味着只能采用拉格朗日乘子法),但如果大家仔细分析这个问题就会发现,损失函数只和t有关,而 w w w向量虽然有模长的限制,但是方向是可以随意变化的,那么为了让Margin最大,肯定要取和 μ ( π E ) − μ ( π g ) \mu(\pi_E)-\mu(\pi_g) μ(πE)−μ(πg)平行的方向,然后取到最大模长1,由此步骤(5)就迎刃而解。对于 g = 0 , 1 , 2 , . . . , i g=0,1,2,...,i g=0,1,2,...,i均成立的问题,只需要计算取Margin最小的 w ∗ w^* w∗以满足 t t t即可:
w g ∗ = μ ( π E ) − μ ( π g ) ∥ μ ( π E ) − μ ( π g ) ∥ 2 , ( g = 0 , 1 , . . . , i ) w ∗ = arg min g = 0 , 1 , . . . , i w g ∗ [ μ ( π E ) − μ ( π g ) ] t ∗ = w ∗ ( μ ( π E ) − μ ( π g ) ) \begin{array}{l} w^*_g=\frac{\mu(\pi_E)-\mu(\pi_g)}{\lVert\mu(\pi_E)-\mu(\pi_g)\rVert_2},(g=0,1,...,i)\\[2ex] w^*=\argmin_{g=0,1,...,i} {w^*_g[\mu(\pi_E)-\mu(\pi_g)]}\\[2ex] t^*=w^*(\mu(\pi_E)-\mu(\pi_g))\\ \end{array} wg∗=∥μ(πE)−μ(πg)∥2μ(πE)−μ(πg),(g=0,1,...,i)w∗=argming=0,1,...,iwg∗[μ(πE)−μ(πg)]t∗=w∗(μ(πE)−μ(πg))
当然了,其实真正有用的只是 w ∗ w^* w∗罢了(再确切一些,只是 w ∗ w^* w∗的方向有用)。原作者给出的Python代码中用的不是这个公式,但是它的解和上述公式解出来是一样的。
2.仿真环境
\qquad 仿真环境使用的是gym,在IRL-Introduction也提到过这是需要Linux环境的,另外python的版本不能超过3.7(超过之后虽然这个代码可以运行,但是其他很多gym的环境都会出现bug,以强化学习为课题的读者们建议在Python3.7环境下运行)。
仿真环境说明-链接

\qquad MountainCar-v1是连续的状态空间,离散的动作空间的仿真环境,Action其实就是小车加速度(只能取-1, 0, 1),Observation是小车位置和速度,取值范围Boundary见上图。
\qquad 真实的Reward是每隔一秒就会扣1分,直到小车到达终点。MountainCar-v1中走左侧坡道不扣分,而
v2版本则是将这条规则取消(以增加模型难度)。当然我们只是用它来做evaluation,在train中是不起作用的(因为逆强化学习用不到Reward函数)。
\qquad 学徒学习参考了github项目的代码(稍微有点问题,已经在博客中修正并且在git中另申请了一个branch)
链接:
Github代码网址
\qquad python环境依赖:numpy,gym,readchar (Python捕捉键盘操作的库)
3.运行
\qquad Github上的代码是基于Q-Table的,没有显卡加速的,运行60000代大概需要20分钟左右(AMD R3处理器)。由于贴出了GitHub上的下载链接,这里就不粘贴代码了,如果发现不能下载的朋友也不用着急,我已经上传到资源了(下载是免费的):
下载链接
\qquad 直接运行mountaincar/app/test.py即可查看效果,trian.py是训练(会把之前保存的Agent给覆盖掉),结果保存在results文件夹下。
\qquad IRL的专家轨迹保存在expert_demo文件夹下,有一个make_expert.py是专门用来产生专家轨迹的(人工游戏产生),里面指定了三个按键用来采取左,停,右的动作(加速度)。事实上这个代码有那么一点bug,我的电脑上是不能正常运行的,所以我重新写了一个,运行的时候需要在程序根目录下运行。但是它产生的轨迹包含的step数目并不是每次都相等的,只需要修改app.py中有关demonstration遍历的代码即可。
make_expert2.py \;\;\; 操作:ASD按键
import gym
import readchar
import numpy as np
import pickle as pkl
# MACROS
Push_Left = 0
No_Push = 1
Push_Right = 2
# Key mapping
arrow_keys = {
'A': Push_Left,
'S': No_Push,
'D': Push_Right}
end_key = 'Q'
env = gym.make('MountainCar-v0')
end_flag = False
trajectories = []
for episode in range(20): # n_trajectories : 20
trajectory = []
env.reset()
print("episode:{}".format(episode))
score = 0
while True:
env.render()
key = readchar.readkey().upper()
if key not in arrow_keys.keys():
print('invalid key:{}'.format(key))
if key == end_key:
end_flag = True
break
action = arrow_keys[key]
state, reward, done, _ = env.step(action)
score += reward
if state[0] >= env.env.goal_position:
trajectory.append((state[0], state[1], action))
env.reset()
print('mission accomplished! env is reset.')
break
trajectory.append((state[0], state[1], action))
if end_flag:
print('end!')
break
trajectory_numpy = np.array(trajectory, float)
print("trajectory_numpy.shape", trajectory_numpy.shape)
print("score:{}".format(score))
trajectories.append(trajectory) # don't need to seperate trajectories
env.close()
if not end_flag:
with open('expert_demo.p',"wb")as f:
pkl.dump(trajectories,f)
app.py修改的部分【expert_feature_expectation】
def expert_feature_expectation(feature_num, gamma, demonstrations, env):
feature_estimate = FeatureEstimate(feature_num, env)
feature_expectations = np.zeros(feature_num)
for demo_num,traj in enumerate(demonstrations):
for demo_length in range(len(traj)):
state = demonstrations[demo_num][demo_length]
features = feature_estimate.get_features(state)
feature_expectations += (gamma**(demo_length)) * np.array(features)
feature_expectations = feature_expectations / len(demonstrations)
学徒学习+Q-table的训练结果


4.补充(学徒学习+深度Q网络)
\qquad 除此之外,我还尝试了将Q-Table换成DQN加以训练,由于DQN的输入state不像Q-Table一样是有限的,因此训练的时候非常不稳定,在多次调参之后,获得了一个差强人意的结果。

下面是gym仿真的gif截图,与Q-Table不同,DQN的结果时好时坏,好在大多数情况下真实Reward均可以大于-200(即表示成功到达终点)
| Reward:-88 | Reward:-90 | Reward: -141 |
|---|---|---|
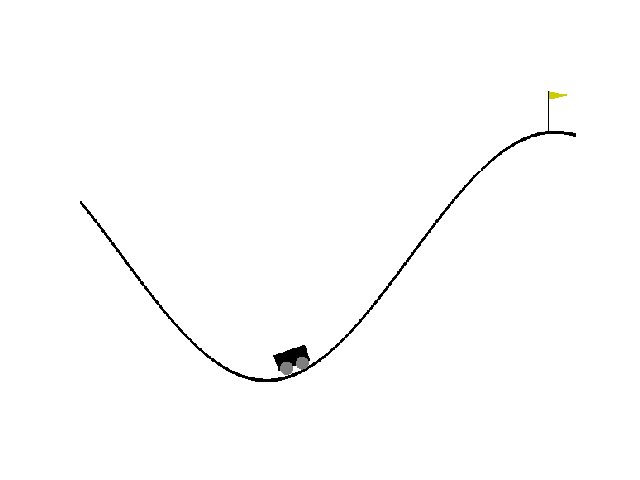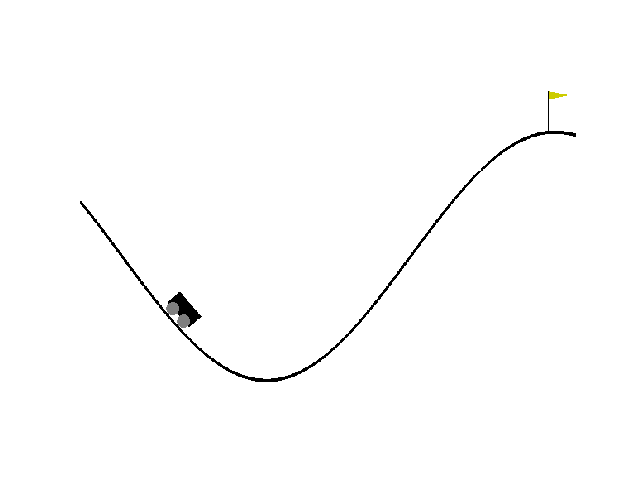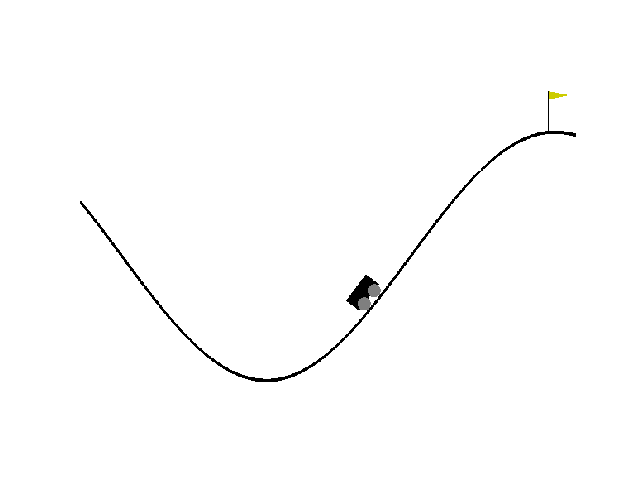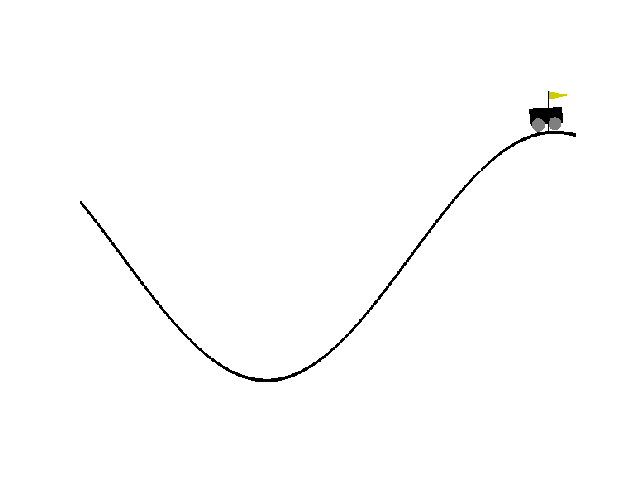 |
 |
 |
\qquad 需要增加和替换的代码主要为dqn,train_dpn和test_dqn三个文件,另外只需对app.py添加一个计算dqn输出的feature expectation即可运行。篇幅原因,这里仅给出dqn的代码,train和test的过程读者模仿原github项目中的train.py和test.py即可顺利完成。(全套代码链接,限时免费,本文点赞过一百将设为 永久免费,说实话研究逆强化学习的朋友不多,我个人也是没有导师指导自学的,还是期望与大家多交流)
dqn.py
import torch as T
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
default_dqn_paras=dict(gamma=0.99,epsilon=0.1,lr=5e-3,input_dims=2,\
batch_size=128,n_actions=3,max_mem_size=int(4e3),\
eps_end=0.01,eps_dec=1e-4,replace_target=50,weight_decay=5e-4)
class DeepQNetwork(nn.Module):
def __init__(self, lr, input_dims, fc1_dims, fc2_dims,
n_actions,weight_decay):
super(DeepQNetwork, self).__init__()
self.input_dims = input_dims
self.fc1_dims = fc1_dims
self.fc2_dims = fc2_dims
self.n_actions = n_actions
self.fc1 = nn.Linear(self.input_dims, self.fc1_dims)
self.fc2 = nn.Linear(self.fc1_dims, self.fc2_dims)
self.fc3 = nn.Linear(self.fc2_dims, self.n_actions)
self.optimizer = optim.Adam(self.parameters(), lr=lr,weight_decay=weight_decay)
self.loss = nn.MSELoss()
self.device = T.device('cuda:0' if T.cuda.is_available() else 'cpu')
self.to(self.device)
def forward(self, state):
x = F.relu(self.fc1(state),inplace=True)
x = F.relu(self.fc2(x),inplace=True)
actions = self.fc3(x)
return actions
class Agent():
def __init__(self, gamma, epsilon, lr, input_dims, batch_size, n_actions,
max_mem_size=100000, eps_end=0.05, eps_dec=5e-4, replace_target=100, weight_decay=1e-4):
self.gamma = gamma
self.epsilon = epsilon
self.eps_min = eps_end
self.eps_dec = eps_dec
self.training = True
self.lr = lr
self.action_space = [i for i in range(n_actions)]
self.mem_size = max_mem_size
self.batch_size = batch_size
self.mem_cntr = 0
self.iter_cntr = 0
self.replace_target = replace_target
self.Q_eval = DeepQNetwork(lr, n_actions=n_actions, input_dims=input_dims,
fc1_dims=32, fc2_dims=32, weight_decay=weight_decay)
self.Q_next = DeepQNetwork(lr, n_actions=n_actions, input_dims=input_dims,
fc1_dims=32, fc2_dims=32, weight_decay=weight_decay)
self.state_memory = np.zeros((self.mem_size, input_dims), dtype=np.float32)
self.new_state_memory = np.zeros((self.mem_size, input_dims), dtype=np.float32)
self.action_memory = np.zeros(self.mem_size, dtype=np.int32)
self.reward_memory = np.zeros(self.mem_size, dtype=np.float32)
self.terminal_memory = np.zeros(self.mem_size, dtype=np.bool)
self.Q_eval.eval()
self.Q_next.eval()
def store_transition(self, state, action, reward, state_, terminal):
index = self.mem_cntr % self.mem_size
self.state_memory[index] = state
self.new_state_memory[index] = state_
self.reward_memory[index] = reward
self.action_memory[index] = action
self.terminal_memory[index] = terminal
self.mem_cntr += 1
@T.no_grad()
def choose_action(self, observation):
"""Epsilon Greedy Exploration
Args:
observation ([iterable]): observation vector
Returns:
action: element in env.action_space
"""
self.Q_eval.eval()
if np.random.random() > self.epsilon or (not self.training):
state = T.tensor(observation,dtype=T.float32).detach().to(self.Q_eval.device)
actions = self.Q_eval.forward(state)
action = T.argmax(actions).item()
else:
action = np.random.choice(self.action_space)
return action
@T.enable_grad()
def learn(self):
if self.mem_cntr < self.batch_size:
return
self.Q_eval.train()
self.Q_next.eval()
self.Q_eval.optimizer.zero_grad()
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, self.batch_size, replace=False)
batch_index = np.arange(self.batch_size, dtype=np.int32)
state_batch = T.tensor(self.state_memory[batch]).detach().requires_grad_(True).to(self.Q_eval.device)
new_state_batch = T.tensor(self.new_state_memory[batch]).detach().requires_grad_(True).to(self.Q_eval.device)
action_batch = self.action_memory[batch]
reward_batch = T.tensor(self.reward_memory[batch]).detach().requires_grad_(True).to(self.Q_eval.device)
terminal_batch = T.tensor(self.terminal_memory[batch]).to(self.Q_eval.device)
q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]
q_next = self.Q_next.forward(new_state_batch).detach()
q_next[terminal_batch] = 0.0 # when state is terminal state, value function is zero
q_target = reward_batch + self.gamma*T.max(q_next,dim=1)[0]
loss = self.Q_eval.loss(q_target, q_eval).to(self.Q_eval.device)
loss.backward()
self.Q_eval.optimizer.step()
self.iter_cntr += 1
self.epsilon = max(self.epsilon - self.eps_dec, self.eps_min)
if self.iter_cntr % self.replace_target == 0:
self.Q_next.load_state_dict(self.Q_eval.state_dict())