【python + Neo4j】知识图谱工具的简单使用
【python + Neo4j】知识图谱工具的简单使用
写在最前面:由于毕业设计需要用到知识图谱工具可视化显示csv表格,经过学习知乎、博客等,决定使用neo4j进行初步的实现。本篇记录了小白入门的全过程,供新手参考嗷!
一、neo4j安装与环境配置
这部分参照前辈们的博客实现的,下面放上介绍的很详细的一篇博客,我就是跟着这篇做的,亲测可用。
Neo4j 第一篇:在Windows环境中安装Neo4j - 悦光阴 - 博客园 (cnblogs.com)
PS:第三部分 网络连接配置 我没有操作,因为没有这个需求,且我的计算机网络学的很差,不太能看懂。
二、python操作neo4j
这里要用到一个库:py2neo,直接pip安装即可。
2.1 入门操作
最简单的入门操作我参考了下面这篇博客,请注意调整代码中的用户名和密码。
(5条消息) 知识图谱 之 python 操作neo4j (导入CSV操作)_辰溪0502的博客-CSDN博客
但是对于没有数据库基础的同学来讲,还是要专门了解一下节点名称和节点标签的区分;以及Node,Relationship函数的参数表示什么意思。参考下面的链接
(2 封私信 / 42 条消息) Neo4j 中节点名称和节点标签到底是什么关系? - 知乎 (zhihu.com)
2.2 将CSV导入neo4j
这里结合了pandas库和py2neo实现。此外,对于表中存在的空缺值,py2neo会直接报错,而不是自动跳过,所以需要我们在代码中添加判断。具体如下:
def CSV4neo4j(filepath, graph):
# 读取CSV文件
data = pd.read_csv(filepath, error_bad_lines=False, encoding='GBK')
for i in range(len(data)):
"""跳过第一行表头"""
if str(data.iloc[i, 0]) == '原文':
continue
"""逐行建立节点与关系(if用于判断事件属性值是否存在)"""
text = Node('text', name=data.iloc[i, 0])
graph.create(text)
"""属性1"""
if str(data.iloc[i, 1]) != 'nan':
prim = Node('prim', name=data.iloc[i, 1])
graph.create(prim)
# 建立关系
text2prim = Relationship(text, '属性1', prim)
graph.create(text2prim)
"""属性2"""
if str(data.iloc[i, 2]) != 'nan':
size = Node('size', name=data.iloc[i, 2])
graph.create(size)
# 建立关系
prim2size = Relationship(text, '属性2', size)
graph.create(prim2size)
"""属性3"""
if str(data.iloc[i, 3]) != 'nan':
trans = Node('trans', name=data.iloc[i, 3])
graph.create(trans)
# 建立关系
text2trans = Relationship(text, '属性3', trans)
graph.create(text2trans)
2.3 合并相同节点(去重)
相同节点不合并的话节点之间的关系就不明晰了,知识图谱的意义也就不大了,所以这部分也是很重要的一步。
在实现的过程中,发现很多其他的博客是使用Neo4j的Cypher语言实现的,但是对我这种数据库基础比较差的,没有用mySQL指令操作过数据库的菜鸡来说太难了。。。所以找到了另一种方式,即在当前图中搜索相同节点是否已存在(NodeMatcher)主要参考了以下两篇博客,第一篇介绍整体思路,第二篇聚焦代码实现,我这里就不再具体介绍了,请移步大神博客嘻嘻!
(5条消息) neo4j,python,关于使用csv批量建立节点时,会重复建立相同名称节点。去重。_qq_51388397的博客-CSDN博客
(5条消息) python操作Neo4j进行同名实体合并_何时西风止的博客-CSDN博客
因此将上述CSV4neo4j函数改进如下:
def CSV4neo4j(filepath, graph):
# 导入CSV文件
data = pd.read_csv(filepath, error_bad_lines=False, encoding='GBK')
for i in range(len(data)):
"""跳过第一行表头"""
if str(data.iloc[i, 0]) == '原文':
continue
"""逐行建立节点与关系(if用于判断事件属性值是否存在)"""
text = Node('text', name=data.iloc[i, 0])
graph.create(text)
"""属性1"""
if str(data.iloc[i, 1]) != 'nan':
prim = Node('prim', name=data.iloc[i, 1])
matcher = NodeMatcher(graph)
matchlist = list(matcher.match('prim', name=data.iloc[i, 1]))
if len(matchlist) > 0: # 节点已存在,无需再行创建
prim = matchlist[0]
# 直接建立关系
text2prim = Relationship(text, '属性1', prim)
graph.create(text2prim)
else: # 需创建节点
graph.create(prim)
# 建立关系
text2prim = Relationship(text, '属性1', prim)
graph.create(text2prim)
"""属性2"""
if str(data.iloc[i, 2]) != 'nan':
size = Node('size', name=data.iloc[i, 2])
matcher = NodeMatcher(graph)
matchlist_size = list(matcher.match('size', name=data.iloc[i, 2]))
if len(matchlist_size) > 0:
size = matchlist_size[0]
# 建立关系
prim2size = Relationship(text, '属性2', size)
graph.create(prim2size)
else:
graph.create(size)
# 建立关系
prim2size = Relationship(text, '属性2', size)
graph.create(prim2size)
"""属性3"""
if str(data.iloc[i, 3]) != 'nan':
trans = Node('trans', name=data.iloc[i, 3])
matcher = NodeMatcher(graph)
matchlist_trans = list(matcher.match('trans', name=data.iloc[i, 3]))
if len(matchlist_trans) > 0:
trans = matchlist_trans[0]
# 建立关系
text2trans = Relationship(text, '属性3', trans)
graph.create(text2trans)
else:
graph.create(trans)
# 建立关系
text2trans = Relationship(text, '属性3', trans)
graph.create(text2trans)
最后根据需要调用即可
from py2neo import Graph, Node, Relationship, NodeMatcher
import pandas as pd
# 连接neo4j数据库,输入地址、用户名、密码
graph = Graph('http://localhost:7474', username='neo4j', password='')
graph.delete_all()
myfilepath = 'D:/毕设/代码/data/test.CSV'
CSV4neo4j(myfilepath, graph)
结果如下
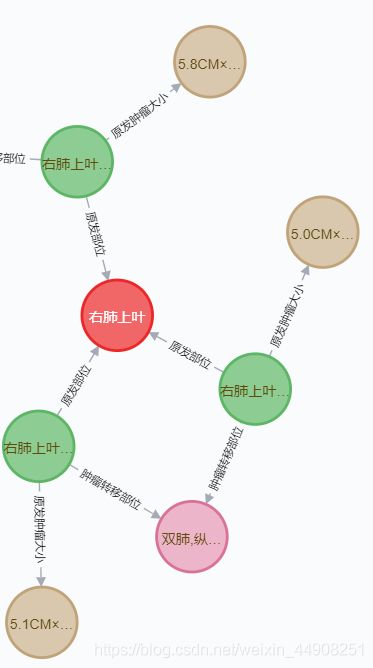
欢迎交流!