FATE —— 2.3.2 Homo-NN内置数据集
前言
在FATE-1.10中,提供了表、nlp_标记器和图像三个数据集,以满足表数据、文本数据和图像数据的基本需求
表数据集
TableDataset在table.py下提供,用于处理csv格式的数据,并将自动从数据中解析id和标签。以下是一些源代码,用于了解此数据集类的用法:
class TableDataset(Dataset):
"""
A Table Dataset, load data from a give csv path, or transform FATE DTable
Parameters
----------
label_col str, name of label column in csv, if None, will automatically take 'y' or 'label' or 'target' as label
feature_dtype dtype of feature, supports int, long, float, double
label_dtype: dtype of label, supports int, long, float, double
label_shape: list or tuple, the shape of label
flatten_label: bool, flatten extracted label column or not, default is False
"""
def __init__(
self,
label_col=None,
feature_dtype='float',
label_dtype='float',
label_shape=None,
flatten_label=False):标记器数据集
TokenizerDataset是在nlp_tokenizer.py下提供的,它是基于Transformer的BertTokenizer开发的,它可以从csv中读取字符串,同时自动分割文本并将其转换为单词id。
class TokenizerDataset(Dataset):
"""
A Dataset for some basic NLP Tasks, this dataset will automatically transform raw text into word indices
using BertTokenizer from transformers library,
see https://huggingface.co/docs/transformers/model_doc/bert?highlight=berttokenizer for details of BertTokenizer
Parameters
----------
truncation bool, truncate word sequence to 'text_max_length'
text_max_length int, max length of word sequences
tokenizer_name_or_path str, name of bert tokenizer(see transformers official for details) or path to local
transformer tokenizer folder
return_label bool, return label or not, this option is for host dataset, when running hetero-NN
"""
def __init__(self, truncation=True, text_max_length=128,
tokenizer_name_or_path="bert-base-uncased",
return_label=True):图像数据集
ImageDataset在image.py下提供,用于简单处理图像数据。它是基于torchvision的ImageFolder开发的。可以看出,使用了该数据集的参数:
class ImageDataset(Dataset):
"""
A basic Image Dataset built on pytorch ImageFolder, supports simple image transform
Given a folder path, ImageDataset will load images from this folder, images in this
folder need to be organized in a Torch-ImageFolder format, see
https://pytorch.org/vision/main/generated/torchvision.datasets.ImageFolder.html for details.
Image name will be automatically taken as the sample id.
Parameters
----------
center_crop : bool, use center crop transformer
center_crop_shape: tuple or list
generate_id_from_file_name: bool, whether to take image name as sample id
file_suffix: str, default is '.jpg', if generate_id_from_file_name is True, will remove this suffix from file name,
result will be the sample id
return_label: bool, return label or not, this option is for host dataset, when running hetero-NN
float64: bool, returned image tensors will be transformed to double precision
label_dtype: str, long, float, or double, the dtype of return label
"""
def __init__(self, center_crop=False, center_crop_shape=None,
generate_id_from_file_name=True, file_suffix='.jpg',
return_label=True, float64=False, label_dtype='long'):使用内置数据集
使用FATE的内置数据集与使用用户自定义数据集完全相同。在这里,我们使用我们的图像数据集和一个具有对流层的新模型来再次解决MNIST手写识别任务,作为示例。
如果您没有MNIST数据集,可以参考前面的教程并下载:Homo-NN自定义数据集
from federatedml.nn.dataset.image import ImageDatasetdataset = ImageDataset()
dataset.load('/mnt/hgfs/mnist/') # 根据自己得文件位置进行调整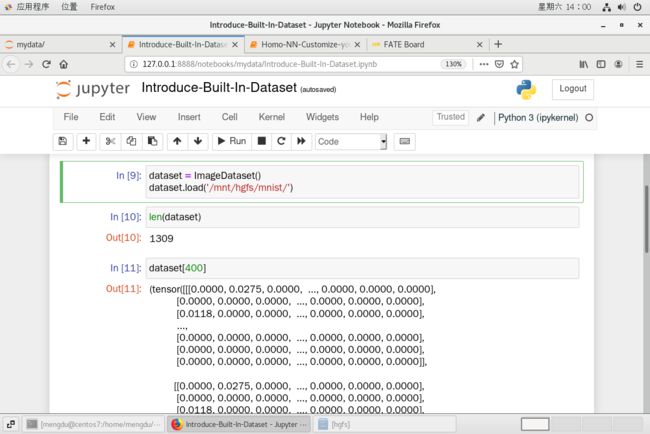
from torch import nn
import torch as t
from torch.nn import functional as F
from pipeline.component.nn.backend.torch.operation import Flatten
# a new model with conv layer, it can work with our ImageDataset
model = t.nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5),
nn.MaxPool2d(kernel_size=3),
nn.Conv2d(in_channels=12, out_channels=12, kernel_size=3),
nn.AvgPool2d(kernel_size=3),
Flatten(start_dim=1),
nn.Linear(48, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.Softmax(dim=1)
)本地测试
在本地测试的情况下,将跳过所有联合过程,并且模型将不执行fed平均
from federatedml.nn.homo.trainer.fedavg_trainer import FedAVGTrainer
trainer = FedAVGTrainer(epochs=5, batch_size=256, shuffle=True, data_loader_worker=8, pin_memory=False) # 参数
trainer.set_model(model)trainer.local_mode() optimizer = t.optim.Adam(model.parameters(), lr=0.01)
loss = t.nn.CrossEntropyLoss()
trainer.train(train_set=dataset,optimizer=optimizer, loss=loss)
它可以工作,现在可以执行联合任务了
具有内置数据集的Homo NN任务
import torch as t
from torch import nn
from pipeline import fate_torch_hook
from pipeline.component import HomoNN
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.interface import Data, Model
t = fate_torch_hook(t)import os
# bind data path to name & namespace
fate_project_path = os.path.abspath('../')
host = 10000
guest = 9999
arbiter = 10000
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host,
arbiter=arbiter)
data_0 = {"name": "mnist_guest", "namespace": "experiment"}
data_1 = {"name": "mnist_host", "namespace": "experiment"}
# 这里需要根据自己得版本作出调整,否则文件参数上传失败会报错
data_path_0 = fate_project_path + '/examples/data/mnist_train'
data_path_1 = fate_project_path + '/examples/data/mnist_train'
pipeline.bind_table(name=data_0['name'], namespace=data_0['namespace'], path=data_path_0)
pipeline.bind_table(name=data_1['name'], namespace=data_1['namespace'], path=data_path_1){'namespace': 'experiment', 'table_name': 'mnist_host'}
# 定义reader
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=data_0)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=data_1)from pipeline.component.homo_nn import DatasetParam, TrainerParam
# a new model with conv layer, it can work with our ImageDataset
model = t.nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5),
nn.MaxPool2d(kernel_size=3),
nn.Conv2d(in_channels=12, out_channels=12, kernel_size=3),
nn.AvgPool2d(kernel_size=3),
Flatten(start_dim=1),
nn.Linear(48, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.Softmax(dim=1)
)
nn_component = HomoNN(name='nn_0',
model=model, # model
loss=t.nn.CrossEntropyLoss(), # loss
optimizer=t.optim.Adam(model.parameters(), lr=0.01), # optimizer
dataset=DatasetParam(dataset_name='image', label_dtype='long'), # dataset
trainer=TrainerParam(trainer_name='fedavg_trainer', epochs=2, batch_size=1024, validation_freqs=1),
torch_seed=100 # random seed
)pipeline.add_component(reader_0)
pipeline.add_component(nn_component, data=Data(train_data=reader_0.output.data))
pipeline.add_component(Evaluation(name='eval_0', eval_type='multi'), data=Data(data=nn_component.output.data))pipeline.compile()
pipeline.fit()