MYSQL 存储引擎与索引
目录
一、查看mysql 支持的引擎:
二、常用引擎特点:
三、索引优缺点
优点:
缺点:
技巧:
四、B+树模型
1.b+树简介
2.模拟b+树与表
3.InnoDB b+树性能分析
五、聚簇索引
一、查看mysql 支持的引擎:
SHOW ENGINES; 常用的引擎 InnoDB、Myisam、Memrory

二、常用引擎特点:
- InnoDB
- InnoDB 支持外键
- InnoDB在3.23后就支持,在5.5后成为默认存储引擎
- InnoDB支持事务,可确保事务完整提交和回滚
- InnoDB支持行级锁。
- InnoDB对内存较多。(页缓存)
- 支持崩溃恢复。(binlog)
- 聚簇索引,主键与数据存在一起,叶子节点上就是完整的数据记录。
- Myisam
- 不支持事务、不支持外键、锁粒度为表级。
- 不支持崩溃恢复。
- count(*)很快,因为在数据表中有专门字段来记录记录数。
- 索引与数据分开存储,主键b+树的叶子结点除主键外,其余的数据都是指针,指向数据文件中的记录指针。
- Memory
- 内存数据库
- 储引擎为Hash表。
- 擅长等值与非等值查找。
- 不支持范围查找与通配LIKE。
- 如何选择InnoDB与Myisam
- 如果查询较多,更新、插入较少,则使用myisam。myisam是索引与数据分开存储,它会将索引全部加载到内存中,所以查找记录快。
- 然而大多数情况还是使用InnoDB。
三、索引优缺点
-
优点:
- 提高数据检索效率,从而降低IO成本。
- 通过建唯一索引,可以让表的字段具有唯一性。
- 加速表的连接,当要连接的字段上有索引时,连接时会更快。
- group by、order by 更快,因为建好为索引天生有序。
-
缺点:
- 创建索引和维护索引都比较耗时,且随着数据量增加,这个成本在上升。
- 索引需要额外空间,即单独的索引文件。
- 更新表的速度下降。
-
技巧:
- 当需要插入大量数据时,可以先删除表上的索引,当插入完成时,再建立索引,这样比一边插入数据一边维护索引速度快!
四、B+树模型
1.b+树简介
InnoDB与Myisam引擎都是通过b+树实现。b+树时多叉树,每个非叶子节点的扇出数在 几十、几百、甚至几千 不等。这就造就了b+数的形状一定是矮且胖的。这个形状有利于将更多的数据存放在一个页(一个页默认16KB)中,且磁盘IO的次数不会很高。
b+树的非叶子节点不存放数据,只存放索引,真正的数据都存放在叶子节点中。b+树按索引升序或降序排序,所以很适合范围查找。
2.模拟b+树与表
下面假设表创建一张表user:
CREATE TABLE USER(
id INTEGER PRIMARY KEY AUTO_INCREMENT,
age INTEGER,
NAME VARCHAR(20)
);
然后插入数据:
INSERT INTO USER
VALUES(1,4,'a'),
(2,4,'b'),
(3,5,'a'),
(4,6,'d'),
(5,1,'b'),
(6,2,'c'),
(7,20,'z'),
(8,32,'b'),
(9,5,'a'),
(10,1,'f'),
(11,5,'b'),
(12,5,'a');
那么按InnoDB引擎,聚簇索引就可能长下面这个样子,仅模拟。(真实情况下,只需一个页就能存下这点数据)。
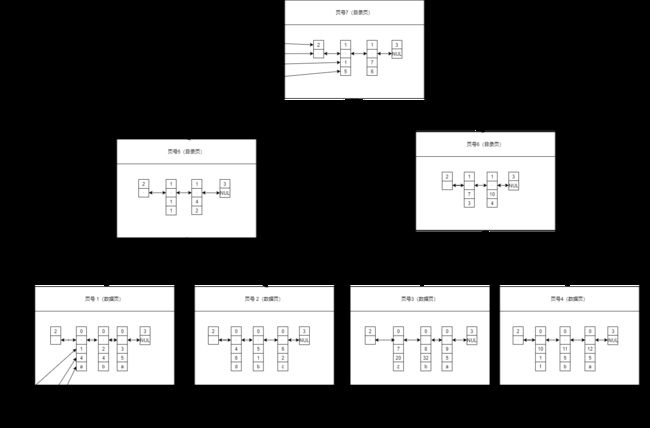
record_type:表示记录类型:0普通记录、1目录项记录 、 2最小记录、3最大记录
next_record:表示记录的下一个记录,相当于指针。
select * from user where id=5;在b+树中的查询过程可能是:
首先在根节点中查找,发现第一条记录中最小的id=1,第二条记录最小id=7,由于叶子节点的id一定递增,所以id=5的记录可能在编号为5的页中,然后将页5加载到内存中,同样的判断方法,发现id=5的记录可能在编号为2的页中,将页2加载到内存中,然后遍历查找id=4的记录,匹配到,然后获取这条记录。
3.InnoDB b+树性能分析
由于一个页默认大小16KB(目录页或数据页),则假设1KB的空间全部用于控制字段,15KB用于存放记录。又假设每条记录150B。则这么算下来叶子结点可以存100条记录,目录节点可以存约1000条记录。
注:根节点一般都常驻内存。
当b+树有一层时:记录数为100条,零次磁盘io。
当b+树有二层时:记录数为1000*100条,一次磁盘io。
当b+树有三层时:记录数为1000*1000*100条,两次磁盘io。
当b+树有四层时:记录数为1000*1000*1000*100条,三次磁盘io。
由于开发中,当mysql InnoDB表操作千万级时,就需要分表,可见一般的磁盘io不会超过2次。
五、聚簇索引
聚簇索引是基于主键,索引即数据,数据即索引。不需要显示index 创建。非聚簇索引:基于非主键。
聚簇索引优点:
1.数据访问更快
2.聚簇索引对于基于主键的查询、排序速度更快。
3.在一定范围内,节省IO操作。
聚簇索引缺点:
1.需要按主键顺序插入,否则出现页分裂,一般建议ID自增,auto_increment、
2.更新主键代价高,会移动行的位置,因此一般不更新。
Mysql中,目前只有InnoDB支持聚簇索引。Myisam 不支持。