【机器学习】Logistic回归
一、Logistic回归概念
Logistic回归(logistic regression)是统计学习中的经典分类方法,属于对数线性模型,所以也被称为对数几率回归。这里要注意,虽然带有回归的字眼,但是该模型是一种分类算法,Logistic回归是一种线性分类器,针对的是线性可分问题。利用logistic回归进行分类的主要思想是:根据现有的数据对分类边界线建立回归公式,以此进行分类。
二、基于Logistic回归和Sigmoid函数的分类
1.Sigmoid函数
函数表达式:

下图给出了Sigmoid函数在不同坐标尺度下的两条曲线图,当x为0时,Sigmoid函数值为0.5。随着x的增大,对应的Sigmoid值将逼近于1;随着x的减小则逼近于0.当横坐标尺度较小时,曲线变化较为平滑,当尺度扩大到一定程度,Sigmoid看起来像一个阶跃函数。


那么对于Sigmoid函数计算公式,我们可以这样解释:为了实现logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和带入sigmoid函数中。进而得到一个范围在0-1之间的数值。最后设定一个阈值,在大于阈值时判定为1,否则判定为0。以上便是逻辑斯谛回归算法是思想,公式就是分类器的函数形式。
"""
Sigmoid函数实现
"""
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
2.Logistic回归的优缺点
优点:
(1)无需事先假设数据分布
(2)可得到“类别”的近似概率预测(概率值还可用于后续应用)
(3)可直接应用现有数值优化算法(如牛顿法)求取最优解,具有快速、高效的特点
缺点:容易欠拟合,分类精度可能不高。
使用数据类型:数值型和标称型数据
3.Logistic回归的一般过程
1、收集数据:任何方式
2、准备数据:由于要计算距离,因此要求数据都是数值型的,另外结构化数据格式最佳。
3、分析数据:采用任一方是对数据进行分析
4、训练算法:大部分时间将用于训练,训练的目的为了找到最佳的分类回归系数
5、测试算法:一旦训练步骤完成,分类将会很快
6、使用算法:首先,我们需要输入一些数据,并将其转化成对应的结构化数值;接着基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪一类别;在这之后,我们就可以在输出的类别上做一些其他的分析工作。
三、基于最优化方法的最佳回归系数确定
1.梯度上升法
要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为▽,则函数f(x,y)的梯度由下式表示:

这个梯度意味着要沿x的方向移动: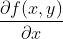
沿y的方向移动: 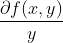
其中,函数f(x,y)必须要在待计算的点上有定义并且可微。
用向量来表示的话,梯度算法的迭代公式如下:
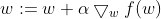 ,其中
,其中 表示步长。
表示步长。
2.梯度下降法
按梯度上升的反方向迭代公式即可
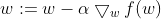
梯度上升算法用来求函数的最大值,而梯度下降算法用来求函数的最小值

3.极大似然估计
假设:
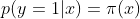
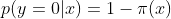
可以得到似然函数为:
![\prod_{i=1}^{N}[\pi (x_{i})^{y_{i}}][1-\pi (x_{i})]^{1-y_{i}}](http://img.e-com-net.com/image/info8/de00680b493b4062816c25b26a2529db.gif)
对似然函数取对数可得:

四、Logistic实战之预测糖尿病的发作
1.数据收集
数据收集来源:http://archive.ics.uci.edu/ml/index.php
这里的数据包含了768个样本和8个属性特征。然后通过0,1来判断用户是否会换上糖尿病。
数据的部分内容展示:

2.核心算法
这里通过分类函数把样本数据分成五份,然后采用随机梯度下降法(随机下降与随机上升法核心内容一样)对这五份样本进行训练,并通过sigmoid函数对训练好的样本进行分类。
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return 1.0 / (1.0 + exp(-yhat))
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
for row in train:
yhat = predict(row, coef)
error = row[-1] - yhat
coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat)
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i]
return coef
def logistic_regression(train, test, l_rate, n_epoch):
predictions = list()
coef = coefficients_sgd(train, l_rate, n_epoch)
for row in test:
yhat = predict(row, coef)
yhat = round(yhat)
predictions.append(yhat)
return(predictions)
3.测试运行
这里把学习率设为0.4,训练次数设置为训练1000次,seed(1)是为了保证五份样本每次执行都能产生同一个随机数,防止结果偏差。 n_folds = 5被用于交叉验证,给每次迭代 768/5 = 条记录来进行评估。
if __name__ == '__main__':
seed(1)#每一次执行本文件时都能产生同一个随机数
filename = 'pima-indians-diabetes.csv'
dataset = load_csv(filename)
for i in range(len(dataset[0])):
str_column_to_float(dataset, i)
minmax = dataset_minmax(dataset)
normalize_dataset(dataset, minmax)
n_folds = 5
l_rate = 0.4
n_epoch = 1000
scores = evaluate_algorithm(dataset, logistic_regression, n_folds, l_rate, n_epoch)
print('五份样本的正确率: %s' % scores)
print('总样本平均正确率: %.3f%%' % (sum(scores)/float(len(scores))))
运行这个样本,为 5 次交叉验证的每一次 输出 一个分数,然后输出这五个分数的平均数。我们可以看到平均正确率为77.988%。
运行结果:
