8、DeepFM介绍
前言
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。
在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。
简单线性模型,缺乏学习high-order特征的能力,很难从训练样本中学习到从未出现或极少出现的重要特征。深层模型善于捕捉high-order复杂特征。现有模型用于CTR预估的有很多尝试,如CNN/RNN/FNN/PNN/W&D等,但都有各自的问题。
1、DeepFM 简介
DeepFM 是华为诺亚方舟实验室在 2017 年提出的模型。
可以看做是从FM基础上衍生的算法,将Deep与FM相结合,用FM做特征间低阶组合,用Deep NN部分做特征间高阶组合,通过并行的方式组合两种方法,使得最终的架构具有以下特点:
- (1) 不需要预训练 FM 得到隐向量;
- (2) 不需要人工特征工程;
- (3)能同时学习低阶和高阶的组合特征;
- (4)FM 模块和 Deep 模块共享 Feature Embedding 部分,可以更快的训练,以及更精确的训练学习。
2、 DeepFM 模型结构
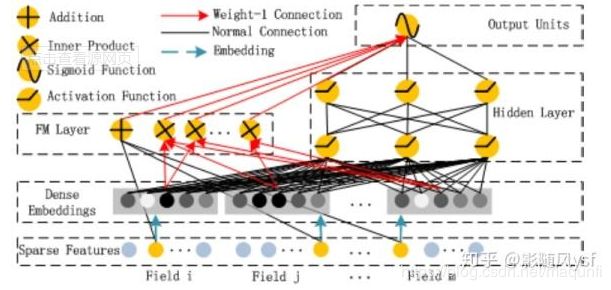
为了同时利用low-order和high-order特征,DeepFM包含FM和DNN两部分,两部分共享输入特征。
对于特征i,标量wi是其1阶特征的权重,该特征和其他特征的交互影响用隐向量Vi来表示。
Vi输入到FM模型获得特征的2阶表示,输入到DNN模型得到high-order高阶特征。模型联合训练,结果可表示为:

2.1 FM部分

FM模型不单可以建模1阶特征,还可以通过隐向量点积的方法高效的获得2阶特征表示,即使交叉特征在数据集中非常稀疏甚至是从来没出现过。这也是FM的优势所在。

2.3 Deep部分

深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于CTR的输入一般是及其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。
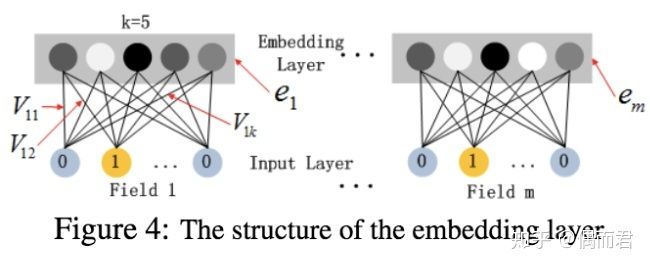
子网络设计时的两个要点:
- 不同field特征长度不同,但是子网络输出的向量需具有相同维度;
- 利用FM模型的隐特征向量V作为网络权重初始化来获得子网络输出向量;
这里的第二点可以这么理解,如上图假设k=5,对于输入的一条记录,同一个field只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。文中将FM的预训练V向量作为网络权重初始化替换为直接将FM和DNN进行整体联合训练,从而实现了一个端到端的模型。
3、DeeepFM 架构解读
3.1 field 解释
从下往上开始看吧,首先是最底下这一部分,可以看到field这个名词,这是因为在处理特征时候,我们需要对离散型数据进行one-hot转化,经过one-hot之后一列会变成多列,这样会导致特征矩阵变得非常稀疏
。

为了应对这一问题,我们把进行one-hot之前的每个特征都看作一个field,这样做的原因是为了在进行矩阵存储时候,我们可以把对一个大稀疏矩阵的存储,转换成对两个小矩阵 和一个字典的存储。 (这个是deepFM最难理解的地方)
对应看图中,每个连续型特征都可以对应为一个点,而每个离散特征(成为一个field),因为要做one-hot话,则每个field根据 不同值的数量n可以对应n个点。
3.2 主要步骤
-
1)对 feature的embeding转换,包括两部分的embedding, 其中可以看到
- 1、是针对不同特征做的embedding【FM的二阶两两交互计算部分和 deep部分是共享这个embedding结果的】,
- 2、是FM的一阶计算部分【使用权重weights[‘feature_bias’]、直接对原始特征做的一阶计算】

- 3、是对应FM的二阶计算阶段,对经过weights[‘feature_embeddings’]权重embedding的结果做二阶交叉计算,
- 4、是deep部分的全连接计算部分,使用神经网络权重weights["layer_n]和 weights["bias_n]进行计算。
-
2)FM计算的过程,其中左部分FM阶段对应的公式如下,可以看到2部分对应着左侧一阶的公式,3部分对应右侧二阶的公式。

-
(3)深度部分可以对应序号4,架构图是下面的形式。
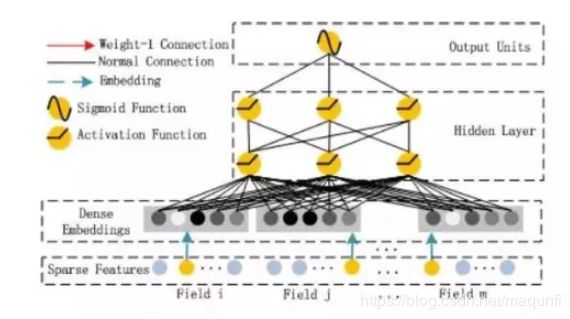
3.3 具体计算时,主要涉及四个权重
-
weights[‘feature_embeddings’] :维度是[self.feature_size,self.embedding_size]。这里表示存储对 每个feature的embedng表示,这里embedding转换就相当于是一个全连接层、feature_size是总的特征数量(可以看出离散特征的每个离散值都有单独的embedding表示的)。
-
weights[‘feature_bias’]:维度是 [self.feature_size,1]。这里存储对特征的一维交叉计算,对应FM公式中的一维计算部分,对每个特征都会附加长度为1的权重。
-
weights[‘layer_0’]:维度是(上一层神经元树量,当前层神经元数量),对应deep部分神经元的权重部分
-
weights[‘bias_0’]:维度是(1,当前层神经元数量),对应深度计算的偏置部分。
4、实例
接下来使用的代码主要采用开源的DeepCTR,相应的API文档可以在这里阅读
https://deepctr-doc.readthedocs.io/en/latest/Examples.html
DeepCTR是一个易于使用、模块化和可扩展的深度学习CTR模型库,它内置了很多核心的组件从而便于我们自定义模型,它兼容tensorflow 1.4+和2.0+。
学术界常用的Criteo数据集,这是一个展示广告的数据集
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import *
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
if __name__ == "__main__":
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
# 1.Label Encoding for sparse features,and do simple Transformation for dense features
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
# 2.count #unique features for each sparse field,and record dense feature field name
fixlen_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].max() + 1, embedding_dim=4)
for i, feat in enumerate(sparse_features)] + [DenseFeat(feat, 1, )
for feat in dense_features]
dnn_feature_columns = fixlen_feature_columns
linear_feature_columns = fixlen_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
# 3.generate input data for model
train, test = train_test_split(data, test_size=0.2, random_state=2020)
train_model_input = {name: train[name] for name in feature_names}
test_model_input = {name: test[name] for name in feature_names}
# 4.Define Model,train,predict and evaluate
model = DeepFM(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
5、总结
整体的算法过程是这样的:
- (1)数据的加载,训练集和测试集的分装。
- (2)配置离散特征集、连续特征集,构建特征字典,构建每个样本的特征索引矩阵 和特征值矩阵, 完成对原特征矩阵 one-hot形式的转换。
- (3)搭建网络架构,初始化网络参数,对网络进行批次训练,最后进行效果验证。
参考文献:
1、深度推荐模型之DeepFM
https://zhuanlan.zhihu.com/p/57873613
2、推荐系统 - DeepFM架构详解
https://blog.csdn.net/maqunfi/article/details/99635620