从左逆右逆广义逆到求解线性方程组的最小二乘解
矩阵的广义逆及应用
- 前言
- 知识点
- 初等行变换求逆
- 代码实现
-
- test example
- test example
- 应用:拟合数据点曲线
-
- 代码实现
- test example
- 总结
前言
终于赶完期末大作业啦,抓不住我(不是。上次说到用LU分解的方式求解线性方程组,但是有时候当方程组不相容时常规方法就会失效,这时候我们可以使用最小二乘法,当然对于矩阵形式的拟合,我们可以利用后面介绍的M-P广义逆直接计算其最小二乘逼近解,开搞!
正文开始~
知识点
完全懵x的童鞋可以翻看相关的线性代数或者矩阵论知识~
-
对于常规意义下的矩阵逆我们有 A B = B A = I AB=BA=I AB=BA=I形式,其中A为n阶可逆矩阵,B为其逆矩阵,记为 A − 1 = B A^{-1}=B A−1=B。
-
若矩阵A满足条件 A H A = A A H A^{H}A=AA^{H} AHA=AAH,则成A是一个正规矩阵,且有 r a n k ( A ) = r a n k ( A H A ) = r a n k ( A A H ) rank(A)=rank(A^{H}A)=rank(AA^{H}) rank(A)=rank(AHA)=rank(AAH)。正规矩阵的充分必要条件为A有n个线性无关的特征向量,且它们构成空间 C n C^n Cn的标准正交基。如果此时 A H A A^{H}A AHA是正定矩阵,即 r a n k ( A H A ) = n rank(A^{H}A)=n rank(AHA)=n,则 A H A A^{H}A AHA可逆,对应于n个非零的特征值。
-
若存在 A ∈ C m × n , B ∈ C n × m A \in C^{m \times n}, B \in C^{n \times m} A∈Cm×n,B∈Cn×m,使得 B A = I n BA=I_n BA=In。则称A是左可逆的,B为A的一个左逆矩阵,记为 A L − 1 A_L^{-1} AL−1。在《矩阵论》(杨明,刘先忠)教材中有证明得到对于左可逆矩阵A,其有列满秩的性质,即 r a n k ( A ) = n rank(A)=n rank(A)=n,则由知识点2可知, A H A A^{H}A AHA可逆,此时A存在一个左逆矩阵 ( A H A ) − 1 A H (A^{H}A)^{-1}A^{H} (AHA)−1AH。
-
同样的,若存在 C ∈ C n × m C \in C^{n \times m} C∈Cn×m,使得 A C = I m AC=I_m AC=Im,则成C是A的一个右逆矩阵,记为 A R − 1 A_R^{-1} AR−1。此时可以证明得到A是行满秩的,A存在一个右逆矩阵 A H ( A A H ) − 1 A^{H}(AA^{H})^{-1} AH(AAH)−1。
-
在左逆右逆的基础上,提出减号广义逆,有 A G A = A AGA=A AGA=A,可以证明左逆右逆自动满足减号逆的定义。
-
在减号逆的基础上,Moore和Penrose提出广义加号逆,满足:
(1) A G A = A AGA=A AGA=A
(2) G A G = G GAG=G GAG=G
(3) ( A G ) H = A G (AG)^H=AG (AG)H=AG
(4) ( G A ) H = G A (GA)^H=GA (GA)H=GA
记广义加号逆G为 A + A^+ A+。若矩阵A是列满秩的,则其加号逆为 ( A H A ) − 1 A H (A^{H}A)^{-1}A^{H} (AHA)−1AH;
若矩阵A是行满秩的,则其加号逆为 A H ( A A H ) − 1 A^{H}(AA^{H})^{-1} AH(AAH)−1。 -
结合前面我们提到的满秩分解,可证明得到以下结论,任意矩阵 A ∈ C m × n A \in C^{m \times n} A∈Cm×n都存在广义加号逆,设 r a n k ( A ) = r rank(A)=r rank(A)=r,A的一个满秩分解为 A = B C , B ∈ C m × r , C ∈ C r × m A=BC,B \in C^{m \times r}, C \in C^{r \times m} A=BC,B∈Cm×r,C∈Cr×m,则有
A + = C R − 1 B L − 1 = C H ( C C H ) − 1 ( B H B ) − 1 B H A^{+} = C_R^{-1}B_L^{-1}=C^{H}(CC^H)^{-1}(B^HB)^{-1}B^H A+=CR−1BL−1=CH(CCH)−1(BHB)−1BH。 -
借助正交投影变换(有兴趣的uu可查阅相关资料,这里不展开),我们可以证明得到对于不相容的方程组 A x = b Ax=b Ax=b, x 0 = A + b x_0=A^+b x0=A+b是其的最佳最小二乘解,最佳在这里的意义是该最小二乘解是在范数约束下的最佳逼近。
初等行变换求逆
由上面的内容可以知道为了得到不相容矩阵的最佳最小二乘解,我们需要求A的广义加号逆,那就要求A的满秩分解(其实也可以用奇异值分解,但这个坑我还没填上hhh),再对满秩分解的结果进行左右逆计算,所以最本质的操作是怎么计算矩阵的逆(这里我们可以保证所求矩阵 A A H AA^{H} AAH或 A H A A^{H}A AHA都是可逆的)。最最普遍的方法,从大一说到研一,那当然是初等行变换求逆啦。大致思路(还是啰嗦一句),将A矩阵与单位矩阵构成一个大矩阵 [ A ∣ I ] [A|I] [A∣I],通过初等行变换将A化为单位阵的同时,右边的单位阵在相同操作下得到的矩阵即为A的逆矩阵。
代码实现
@classmethod
def Primary_Row_Transformation_Inv(self, target, eps=1e-6, test=False):
"""Primary_Row_Transformation_Inv
Args:
target ([np.darray]): [target matrix]
eps ([float]): numerical threshold.
test (bool, optional): [whether to show testing information]. Defaults to False.
Returns:
[np.darray]: [A-]
Last edited: 22-01-09
Author: Junno
"""
assert len(np.shape(target)) == 2
# get row and col numbers
M, N = np.shape(target)
assert M == N, 'This matrix is not square-like, so it can\'t use PRT to get inverse and you can use MP-inverse to calculate its general inv'
assert self.Get_row_rank(
target, eps) == M, 'This matrix is not full-rank, so it can\'t use PRT to get inverse and you can use MP-inverse to calculate its general inv'
E = np.eye(M)
A = deepcopy(target)
if test:
print('original matrix:')
print(target)
for i in range(M):
for j in range(i, N):
if test:
print('During process in row:{}, col:{}'.format(i, j))
if sum(abs(A[i:, j])) > eps:
# sort rows by non-zero values from small to large
zero_index = []
non_zero_index = []
for k in range(i, M):
if abs(A[k, j]) > eps:
non_zero_index.append(k)
else:
zero_index.append(k)
non_zero_index = sorted(
non_zero_index, key=lambda x: abs(A[x, j]))
sort_cols = non_zero_index+zero_index
if test:
print("Sort_cols index: {}".format(sort_cols))
# E should be processed with the same operations.
A[i:, :] = A[sort_cols, :]
E[i:, :] = E[sort_cols, :]
if test:
print('After resorting')
print(A)
print(E)
# eliminate elements belows
prefix = -A[i+1:, j]/A[i, j]
temp = (np.array(prefix).reshape(-1, 1)
)@A[i, :].reshape((1, -1))
A[i+1:, :] += temp
temp = (np.array(prefix).reshape(-1, 1)
)@E[i, :].reshape((1, -1))
E[i+1:, :] += temp
if test:
print('After primary row transformation:')
print(A)
print(E)
# eliminate elements above
for k in range(i):
if abs(A[k, j]) > eps:
# be careful to using intermediate parameter
temp = -(A[k, j]/A[i, j])
A[k, :] += temp*A[i, :]
E[k, :] += temp*E[i, :]
if test:
print('After eliminating elements above:')
print(A)
print(E)
break
else:
continue
# normalize the first element of each row to 1
for m in range(M):
if abs(A[m, m]) > eps:
if A[m, m] != 1:
temp = 1./A[m, m]
A[m, :] *= temp
E[m, :] *= temp
return E
test example
>>> import numpy as np
>>> from Matrix_Solutions import Matrix_Solutions
>>> A=np.array([[ 1., -3., 7.],
... [ 2., 4., -3.],
... [-3., 7., 2.]], dtype=np.float32)
>>> inv_A=Matrix_Solutions.Primary_Row_Transformation_Inv(A)
>>> inv_A
array([[ 0.148, 0.281, -0.097],
[ 0.026, 0.117, 0.087],
[ 0.133, 0.01 , 0.051]])
>>> A@inv_A
array([[ 1., -0., -0.],
[-0., 1., -0.],
[ 0., 0., 1.]])
>>> inv_A@A
array([[ 1., 0., -0.],
[ 0., 1., 0.],
[-0., 0., 1.]])
有了求逆工具后,我们的各种广义逆也就水到渠成,直接上代码
@classmethod
def Left_inv(self, target):
"""Get_Left_Inv
Args:
target ([np.darray]): [target matrix]
Returns:
[np.darray]: [A_L]
Last edited: 22-01-09
Author: Junno
"""
assert len(np.shape(target)) == 2
# get row ans col numbers
M, N = np.shape(target)
assert self.Get_col_rank(target) == N
return self.Primary_Row_Transformation_Inv(target.T@target)@target.T
@classmethod
def Right_inv(self, target):
"""Get_Right_Inv
Args:
target ([np.darray]): [target matrix]
Returns:
[np.darray]: [A_R]
Last edited: 22-01-09
Author: Junno
"""
assert len(np.shape(target)) == 2
# get row ans col numbers
M, N = np.shape(target)
assert self.Get_row_rank(target) == M
return target.T@self.Primary_Row_Transformation_Inv(target@target.T)
@classmethod
def Moore_Penrose_General_Inv(self, target):
"""Moore_Penrose_General_Inv
Args:
target ([np.darray]): [target matrix]
Returns:
[np.darray]: [A+]
Last edited: 22-01-09
Author: Junno
"""
assert len(np.shape(target)) == 2
# get row ans col numbers
M, N = np.shape(target)
B, C = self.Full_Rank_Fact(target)
return self.Right_inv(C)@self.Left_inv(B)
test example
>>> test_m=np.array([
... [1,0,-1,1],
... [0,2,2,2],
... [-1,4,5,3]
... ]).reshape((3,4)).astype(np.float32)
>>> test_m
array([[ 1., 0., -1., 1.],
[ 0., 2., 2., 2.],
[-1., 4., 5., 3.]], dtype=float32)
>>> MPI=Matrix_Solutions.Moore_Penrose_General_Inv(test_m)
>>> MPI
array([[ 0.278, 0.111, -0.056],
[ 0.056, 0.056, 0.056],
[-0.222, -0.056, 0.111],
[ 0.333, 0.167, 0. ]])
# AGA=A
>>> test_m@MPI@test_m
array([[ 1., 0., -1., 1.],
[-0., 2., 2., 2.],
[-1., 4., 5., 3.]])
# GAG=G
>>> MPI@test_m@MPI
array([[ 0.278, 0.111, -0.056],
[ 0.056, 0.056, 0.056],
[-0.222, -0.056, 0.111],
[ 0.333, 0.167, 0. ]])
# (AG)^T=AG, 即AG是对称矩阵
>>> test_m@MPI
array([[ 0.833, 0.333, -0.167],
[ 0.333, 0.333, 0.333],
[-0.167, 0.333, 0.833]])
# (GA)^T=GA, 即GA是对称矩阵
>>> (MPI@test_m)
array([[ 0.333, 0. , -0.333, 0.333],
[ 0. , 0.333, 0.333, 0.333],
[-0.333, 0.333, 0.667, -0. ],
[ 0.333, 0.333, 0. , 0.667]])
应用:拟合数据点曲线
最小二乘法最常见的应用莫过于拟合曲线,使曲线与各个观测点的距离最小,得到x和y的对应关系。给出教材中的一个例子:
设有一组实验数据,(1,2),(2,3),(3,5),(4,7),我们希望使用直线
y = β 0 + β 1 x y=\beta_0+\beta_1 x y=β0+β1x来拟合数据点,求最佳拟合直线。列出矩阵形式:
[ 1 1 1 2 1 3 1 4 ] [ β 0 β 1 ] = [ 2 3 5 7 ] \begin{bmatrix} 1 & 1 \\ 1 & 2 \\ 1 & 3 \\ 1 & 4 \end{bmatrix} \begin{bmatrix} \beta_0\\ \beta_1 \end{bmatrix}= \begin{bmatrix} 2 \\ 3 \\ 5 \\ 7 \end{bmatrix} ⎣⎢⎢⎡11111234⎦⎥⎥⎤[β0β1]=⎣⎢⎢⎡2357⎦⎥⎥⎤
设系数矩阵为A,则我们只要求得A的广义逆,那么 β \beta β就可以表示为 A + b A^+b A+b。
最后拟合的误差可以通过 ∣ ∣ δ ∣ ∣ 2 = ∣ ∣ A β − b ∣ ∣ 2 ||\delta||_2=||A\beta-b||_2 ∣∣δ∣∣2=∣∣Aβ−b∣∣2来计算。当然我们也可以用高阶来拟合,这样的误差会更小,这在下面的实现中也会体现到。
代码实现
@classmethod
def Match_Points_LSM(self, ps, order):
"""Match Points using LSM and show results
Args:
ps ([type]): [arrays of (x,y) points]
order ([type]): [fitting order]
Last edited: 21-12-31
Author: Junno
"""
M, N = ps.shape[0], order+1
A = np.zeros((M, N))
# generate coefficient matrix A with given order
for c in range(N):
A[:, c] = np.power(ps[:, 0], c)
# get MP-inv of A
L_Inv = self.Moore_Penrose_General_Inv(A)
# solve beta
beta = L_Inv@ps[:, 1]
# show results
print('The matching line: y=', sep='', end='')
for i in range(order+1):
print('{:-.3f}*x^{}'.format(beta[i], i), sep='', end='')
print('\n')
# calculate fitting error
error = np.linalg.norm(A@beta-ps[:, 1])
print("Norm of Matching Error: {:.5f}".format(error))
# prepare to show matching line
x = np.arange(np.min(ps[:, 0])-1,
np.max(ps[:, 0])+1, 0.01).reshape((-1,))
B = np.zeros((x.shape[0], N))
for c in range(N):
B[:, c] = np.power(x, c)
y = B@beta
plt.figure(0)
fig, ax = plt.subplots()
raw = ax.scatter(ps[:, 0], ps[:, 1], marker='o', c='blue', s=10)
match = ax.scatter(x, y, marker='v', c='red', s=1)
plt.legend([raw, match], ['raw', 'match'], loc='upper left')
plt.title('Fitting points with {} order'.format(order))
plt.xlabel('x')
plt.ylabel('y')
plt.show()
test example
>>> a=np.array([
... [1,2],
... [2,3],
... [3,5],
... [4,7]
... ]).reshape((-1,2)).astype(np.float32)
# 一阶拟合
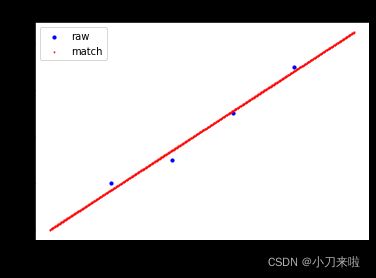
>>> Matrix_Solutions.Match_Points_LSM(a,1)
The matching line: y=+0.000*x^0+1.700*x^1
Norm of Matching Error: 0.54772
# 二阶拟合
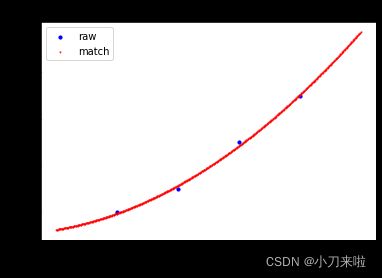
>>> Matrix_Solutions.Match_Points_LSM(a,2)
The matching line: y=+1.250*x^0+0.450*x^1+0.250*x^2
Norm of Matching Error: 0.22361
# 三阶拟合
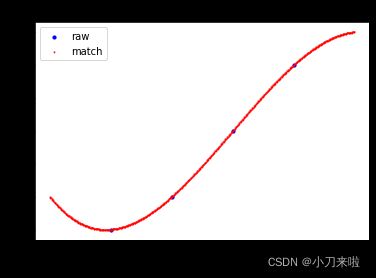
>>> Matrix_Solutions.Match_Points_LSM(a,3)
The matching line: y=+3.000*x^0-2.333*x^1+1.500*x^2-0.167*x^3
Norm of Matching Error: 0.00000
总结
今天的内容先到这,对代码有任何问题或者指正欢迎留言,我会第一时间进行回复~
不求对原理的证明有多么深刻,更多的是能掌握这类问题的解决工具。下回继续填坑!
曲高未必人不识,自有知音与清词。